
数仓|大数据时代,维度建模过时了吗?
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

20世纪80年代末期,数据仓库技术兴起。自Ralph Kimball 于1996 年首次出版The Data Warehouse Toolkit(Wiley)一书以来,数据仓库和商业智能(Data Warehousing and Business Intelligence, DW/BI)行业渐趋成熟。Kimball提出了数据仓库的建模技术--维度建模(dimensional modelling),该方法是在实践观察的基础上开发的。虽然它不基于任何理论,但是在实践中却非常成功。维度建模被视为设计数据仓库和数据集市的主要方法,对数据建模和数据库设计学科有着重要的影响。时至今日,维度建模依然是构建数仓首选的数据建模方法,但是随着技术的发展,获取超强的存储与计算能力的成本会变得很廉价。这在无形之中对传统的维度建模方法产生了一定的影响。本文将讨论以下内容:
维度建模的概念 维度建模的优缺点 为什么星型模型依然有用 数据建模发生了哪些变化
规则是用来被打破的!
维度建模的概念
事实表
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和与业务过程有关的度量。
事实表中一条记录所表达的业务细节程度被称为粒度。通常粒度可以通过两种方式来表述:一种是维度属性组合所表示的细节程度;一种是所表示的具体业务含义。
作为度量业务过程的事实,一般为整型或浮点型的十进制数值,有可加性、半可加性和不可加性三种类型。可加性事实是指可以按照与事实表关联的任意维度进行汇总。半可加性事实只能按照特定维度汇总,不能对所有维度汇总,比如库存可以按照地点和商品进行汇总,而按时间维度把一年中每个月的库存累加起来则毫无意义。还有一种度量完全不具备可加性,比如比率型事实。对于不可加性事实可分解为可加的组件来实现聚集。
事实表通常只有很少的列和很多行,是一种瘦高型的表。事实表定义为以下三种类型之一:
事务事实表:记录有关特定事件的事实(例如,销售事件,保存在原子的粒度,也称为原子事实表) 周期快照事实表记录给定时间点的事实(例如,月末的帐户详细信息) 累积快照事实表记录了给定时间点的汇总事实(例如,某产品的当月迄今总销售额)
维表
维度是维度建模的基础和灵魂。在维度建模中,将度量称为事实,将环境描述为维度,维度是用于分析事实所需要的多样环境。例如,在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。维度所包含的表示维度的列,称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。
维度通常是限定事实的描述性信息。例如,产品维度中的每个记录代表一个特定的产品。与事实表相比,维表通常具有相对较少的记录,但是每个记录可能具有大量的属性来描述事实数据。维度可以定义各种各样的特征,一些常见的维表:
时间维度表:以最低时间粒度级别描述时间 地理维度表:描述了位置数据,例如国家/地区/城市 产品维度表:表描述了产品的详细信息 员工维度表:描述了员工,例如销售人员
星型模型
大多数的数据仓库都采用星型模型。星型模型是由事实表和多个维表组成。事实表中存放大量关于企业的事实数据,元祖个数通常很大,而且非规范化程度很高。例如,多个时期的数据可能会出现在同一个表中。维表中通常存放描述性数据,维表是围绕事实表建立的,通常来说具有较少的行。如下图所示:
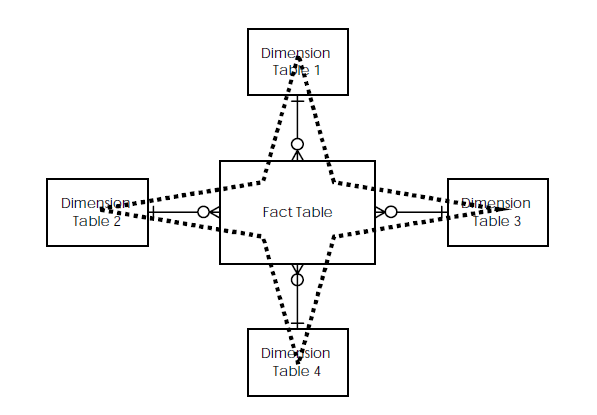
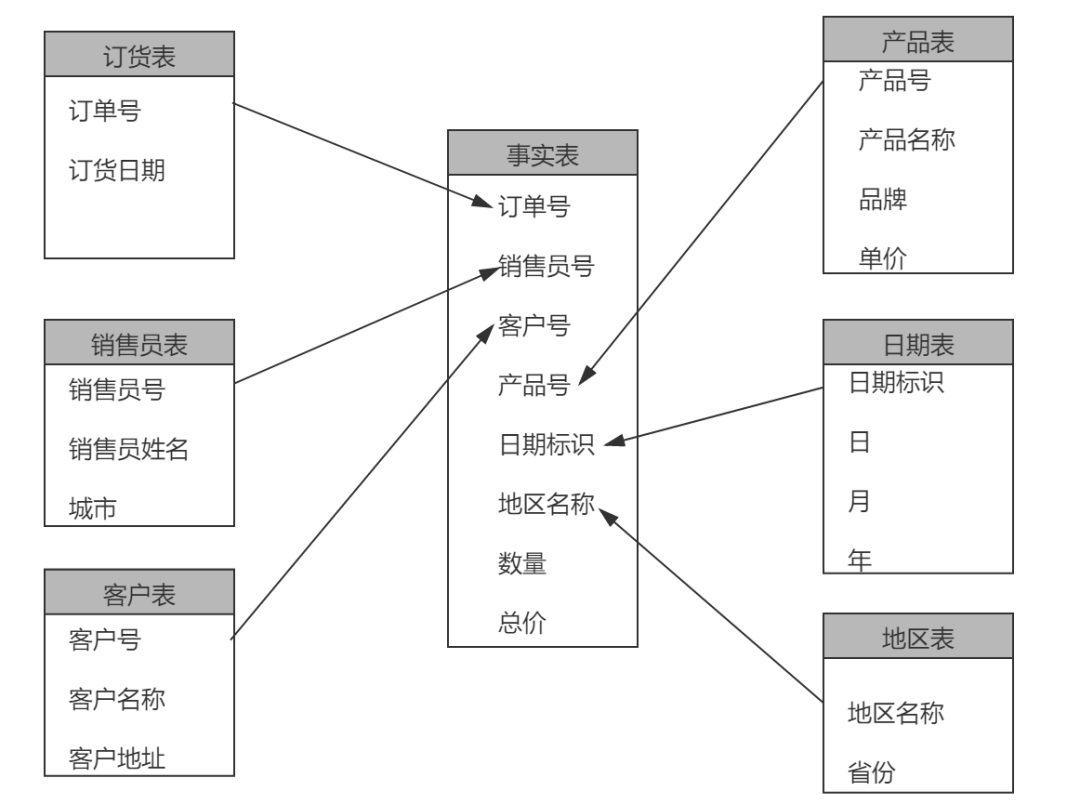
星型模型存取数据速度快,主要是针对各个维做了大量预处理,如按照维度进行预先的统计、分组合排序等。与规范化的关系型数据库设计相比,星型模型是非规范化的,通过数据冗余提升多维数据的查询速度,增加了存储空间的代价。当业务问题发生变化、原来的维度不能满足需求时,需要增加新的维度。由于事实表的主键由所有维表的主键组成,这种维的变化带来的数据变化将是非常复杂和耗时的。一个星型模型的示例:
雪花模型
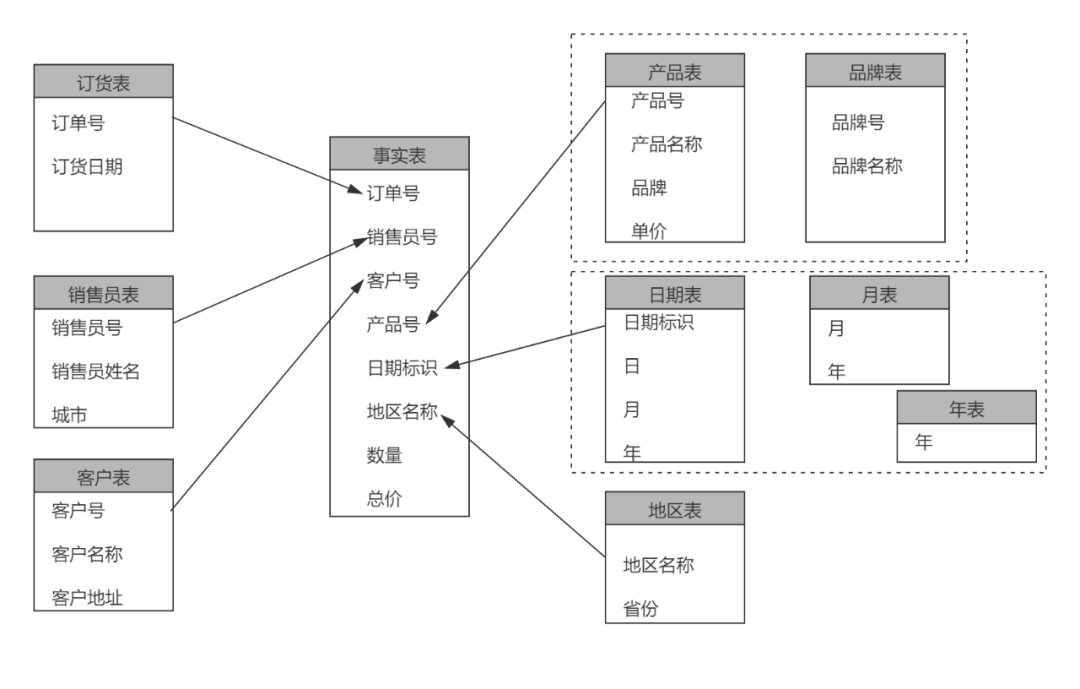
雪花模型是对星型模型的扩展,它将星型模型的维表进一步层次化,原来的各个维表可能被扩展为小的事实表,形成一些局部的层次区域。在雪花模型中能够定义多重父类维来描述某些特殊的维表,如在时间维上增加月维表和年维表,通过查看与时间有关的父类维,能够定义特殊的时间统计信息,如月统计和年统计等。
雪花模式通过更多的连接引入了更多的复杂性。随着存储变得越来越廉价,大多数情况,一般不采用雪花模型方法。
雪花模型的有点是最大限度地减少数据存储量,以及把较小的维表联合在一起来改善查询性能。但是它增加了用户必须处理的表的数量,增加了某些查询的复杂性。如下所示:
维度建模的优缺点
优点
每次需要从数据库中获取一些信息时,可以不用编写冗长的查询 针对读取进行了优化,可以写更少的JOIN,更快地返回结果
缺点
对数据进行非规范化意味着一次性插入或更新会导致数据异常。在实践中,星型模型是通过批处理实来弥补这一问题 分析灵活性有限。星型模型通常是为特定目的而设计的。在分析需求方面,它不像规范化数据模型那样灵活
为什么星型模型依然有用
多种数据源
公司从各种数据源中收集越来越多的数据,因此需要对结果数据集进行整理以进行分析,从而减少异构数据源带来的分析复杂性。
标准
由Ralph Kimball编写的Data Warehouse Toolkit定义了业界广泛理解的概念。新员工可以快速掌握数据仓库的结构,而无需熟悉具体的业务系统数据。数据工程师和分析师通常对事实、维度、粒度这些概念比较了解,从而可以促进协作。
可扩展性
新添加的事实表可以重用现有的维度。通过向事实表添加更多外键,实现向事实表添加新维度。另外,对于集成新的数据集,无需对模型进行重大调整。
数据建模发生了哪些变化
大数据时代,日新月异的技术发展促使存储和计算发生了天翻地覆的变化(存储和计算比以往任何时候都便宜),因此数据模型也相应地发生了一些变化。
缓慢变化维(SCD)
对于随时间而变化的维度,比如:用户可以更改其家庭住址,产品可以更改名称。所以需要一种策略保存历史某个时间点对应的维度信息。
Kimball书中介绍了许多类型的SCD策略,大多数使用UPDATE就地添加或修改信息。在保留历史记录的维度中,当记录中的任何属性发生更改时,都需要复制整行数据,当属性经常更改时,同样会使用更多存储空间。值得注意的是,这些技术很复杂,因为它们是在严格的存储约束下设计的。
其实,可以使用维度快照来解决SCD的问题,虽然需要更多的存储空间,但创建和查询更简单。
维度快照
维度应比事实小得多。电子商务的交易,订单可能数以百万/千万计,但是客户(维度)的数量会少得多。
每天我们都会在版本快照中重新写入整个维度表
/data_warehouse/dim_users/ds = 2020-01-01
/data_warehouse/dim_users/ds = 2020-01-02
...
由于每天有一个快照数据,因此不管发生多少变化都没有影响。这种方式非常简单粗暴,但与复杂的不同类型的缓慢变化维策略相比,不失为一种可选的方案。
使用此种方式,可以通过JOIN特定日期的维度快照来获取历史某个时间点的维度信息。另外,这种方式不会对查询速度产生影响,因为通过分区日期可以直接定位选择的日期,而不是加载所有的数据。
系统地对维度进行快照(为每个ETL计划周期存储维度的完整副本,通常在不同的表分区中),作为处理缓慢变化的维度(SCD)的通用方法,是一种简单的通用方法,不需要太多的工程工作,并且与经典方法相比,在编写ETL和查询时很容易掌握。复杂的SCD建模技术并不直观,并且会降低可访问性。
分区
为了避免上游数据处理错误导致事实表装载错误,需要从数据源系统中提取日期作为分区字段,这样可以实现数据装载的幂等性。此外,建议按 事件日期 进行分区,因为查询通常会将其用作过滤器(WHERE子句)。
代理键与冗余维度
在维表中维护代理键是非常复杂的,除此之外,还会使事实表的可读性变差。在事实表中使用自然键和维度冗余的方式越来越普遍,这样可以减少JOIN带来的性能开销。值得注意的是,支持编码和压缩的序列化格式(如Parquet、ORC)解决了非规范化相关的大多数性能损失。
总结
本文主要介绍了维度建模的基本概念,包括维表、事实表、星型模型和雪花模型。其次对星型模型的优缺点进行了阐述。最后指出了维度建模正在发生的一些变化。