
数仓建模方法论
性能:能够快速查询所需的数据,减少数据I/O的吞吐。
成本:减少不必要的数据冗余,实现计算结果的复用,降低大数据系统中的存储成本和计算成本。
效率:改善用使用数据的体验,提高使用效率。
质量:改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量的、一致的数据访问平台。
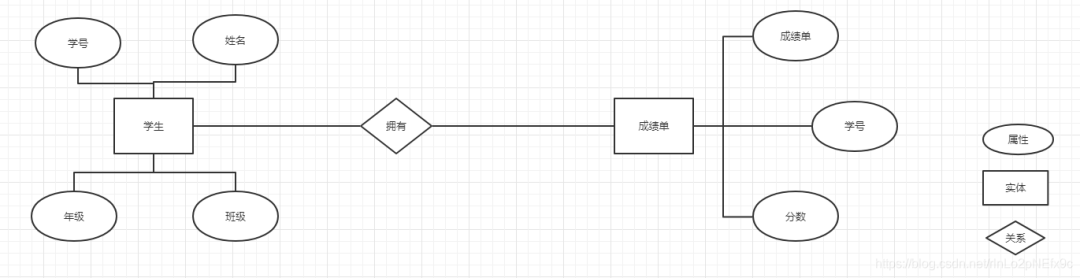
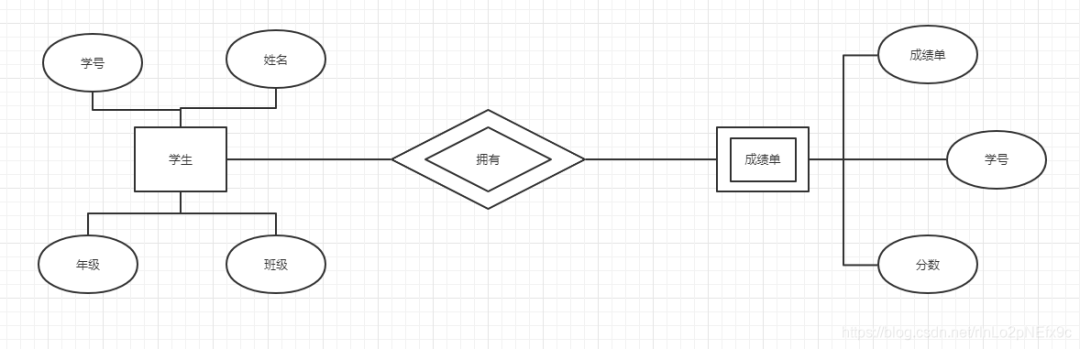


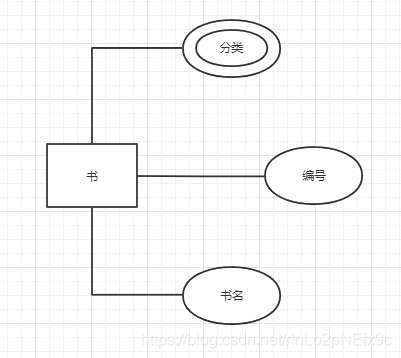
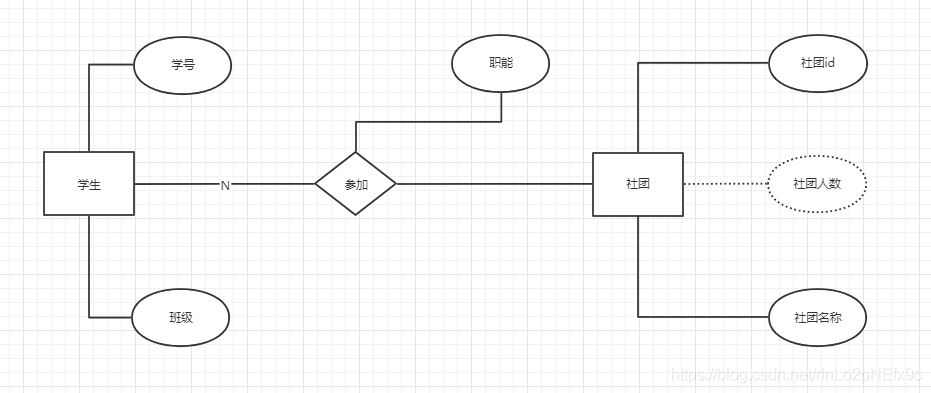
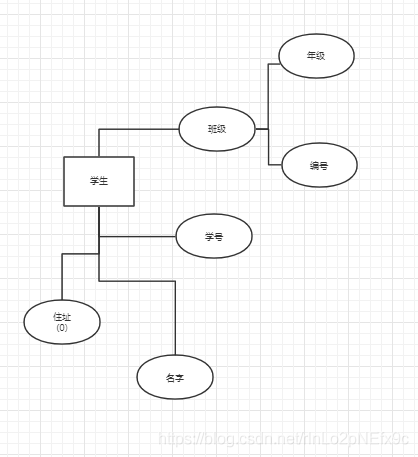

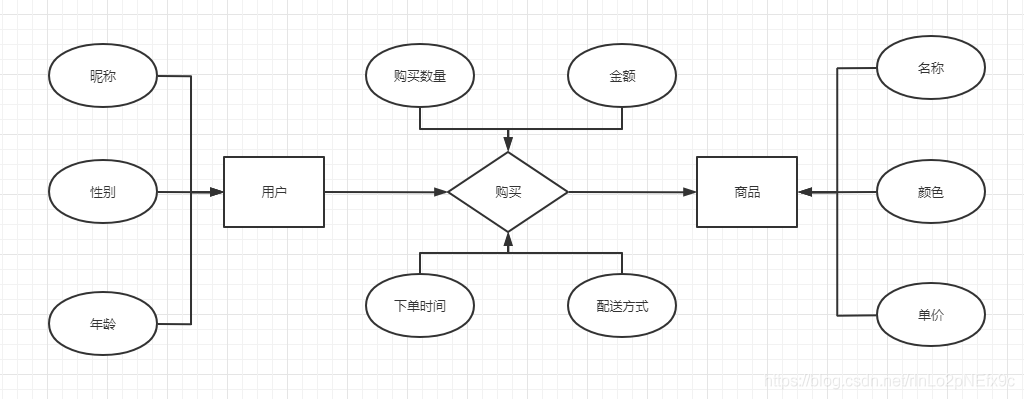


事实表的设计是以能够正确记录历史信息为准则。
维度表的设计是以能够以适合的角度来聚合主题内容为准则。
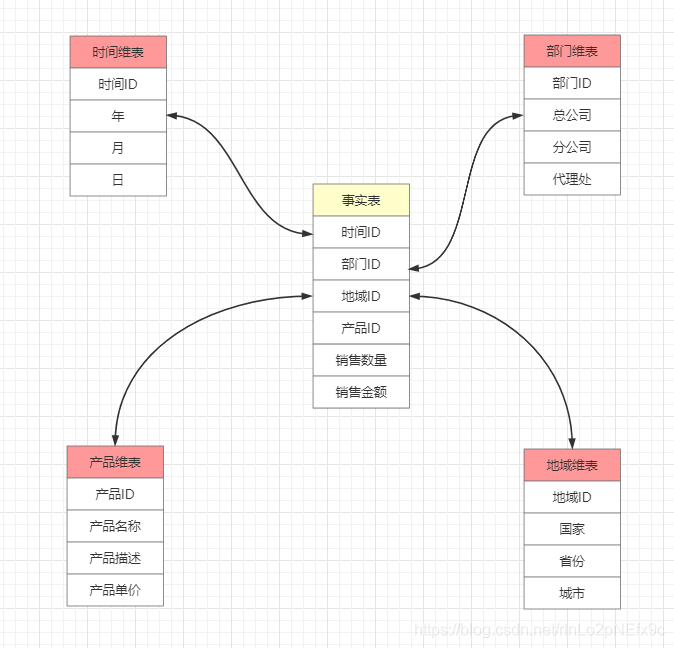
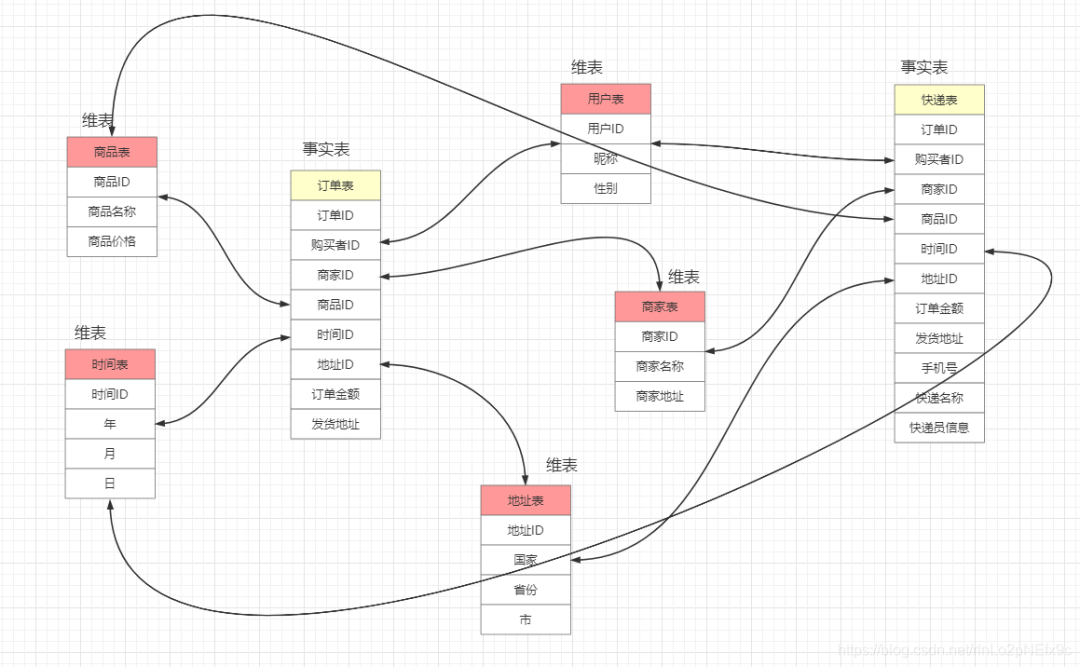
维表只和事实表关联,维表之间没有关联; 每个维表主键为单例,且该主键放置在事实表中,作为两边连接的外键; 以事实表为核心,维度表围绕核心呈星型分布;

第一个也是最简单的方法是重写现有的记录而不跟踪变动。幸运的是,这个方法被许多维度所接受。例如,如果一个部门名称从“财务”变为“财务和会计”,你很可能并不需要记录这种历史变化。但是,从客户和学生的角度看,常常有必要保持跟踪姓名、婚姻状态、教育程度和其它属性的变化——你的应用必要能够获得当前的以及历史的数值。拉链表最常用。
管理维度慢慢改变的第二个方法是数值发生变化时创建一个新的记录,并将旧的记录标记为旧记录。
第三个也是最后的一个方法是维护在维表的同一行中不同列的变化域的历史数值。
与源系统完成独立。 所有数据基于时间戳,即便数据质量很低,也不能清洗掉数据。 可以适应源数据的各种变化,并可以灵活的实现模型扩展。 数据的来源可以完全追踪,并且数据处理作业可以支持重载。


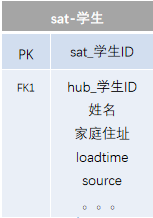


我们看一下Anchor模型的组成。
1.Anchors:类型于Data Vault的Hub,代表业务实体,且只有主键。
2.Attributes:功能类型于Data Vault的Satellite,但是它更加规范化,将其全部k-v结构化,一个表只有一个Anchors的属性描述。
3.Ties:就是Anchors之间的关系,单独用表来描述,类似于Data Vault的Link,可以提升整体模型关系的扩展能力。
4.Knots:代表那些可能会在多个Anchors中公用的属性的提炼,比如性别、状态等这种枚举类型且被公用的属性。
评论