编辑:David Joey 如願
【新智元导读】LeCun新发60页长文,不讲AGI,讲的是「自主机器智能」,推特还不忘喊话老冤家Gary Marcus过来对线。
最近,自从谷歌研究员提出大型语言模型LaMDA「意识觉醒」,并被谷歌雪藏之后,关于「自主AI」的话题,业界的讨论一直没听。如果AI真的有了自主意识,关于是否能实现AGI、如何通向AGI的争论,差不多就能尘埃落定了。在这场讨论中,自然少不了AI界「相爱相杀」多年的一对老冤家:图灵奖得主之一Yann LeCun和AI界「怼王」Gary Marcus。Gary Marcus本人一直对深度学习持质疑态度,他声称,深度学习无法进一步取得进展,因为神经网络在处理符号操作方面存在困难。而以LeCun为代表的主流AI学界,则认为深度学习已经在进行符号推理,并将持续改进。二人就这个问题「隔空开炮」由来已久,最近,Marcus刚写了一篇关于「深度学习撞墙」的文章,LeCun就发文反驳,意思是「别拿暂时的挫折当撞墙,没那么多墙可撞」。或许是觉得前不久那篇文章没讲透、没讲过瘾,LeCun昨天又发了一篇60多页的长文,题为「通向自主机器智能之路」,系统讲述了关于「机器如何能像动物和人类一样学习」的问题。LeCun表示,此文不仅是自己关于未来5-10年内关于AI发展大方向的思考,也是自己未来几年打算研究的内容,并希望能够启发AI界的更多人来一起研究。同时,LeCun也没忘了提醒老朋友Gary Marcus,这篇是发在OpenReview上的,敞开评论,你要战赶紧来战。
LeCun认为,今天的人工智能研究必须解决三个主要挑战:- 机器如何通过观察来学习表达世界、学习预测和学习采取行动?
- 机器如何以基于梯度的学习兼容的方式进行推理和计划?
- 机器如何学习以分层方式、多抽象层次和多时间尺度来表示感知和行动计划?

论文地址:https://openreview.net/forum?id=BZ5a1r-kVsf此文主要是解决「机器怎样才能学会推理和计划」的问题,为此,文章提出了一个架构和训练范式,用来构建能够自主的智能体。
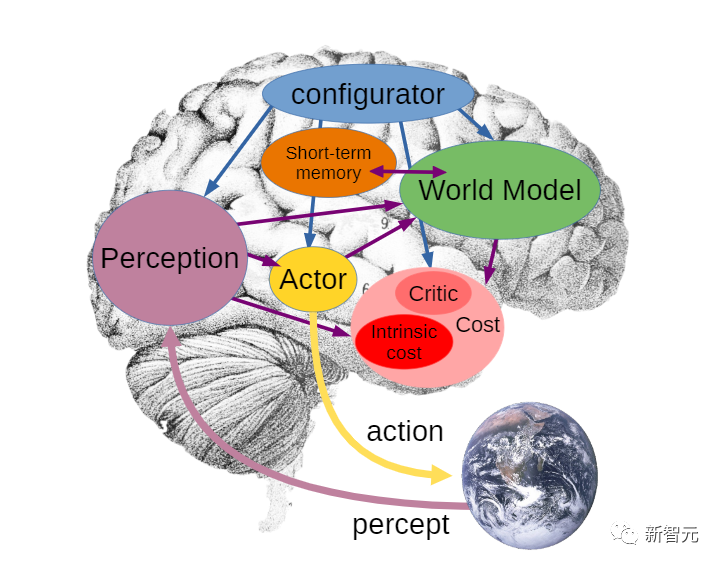
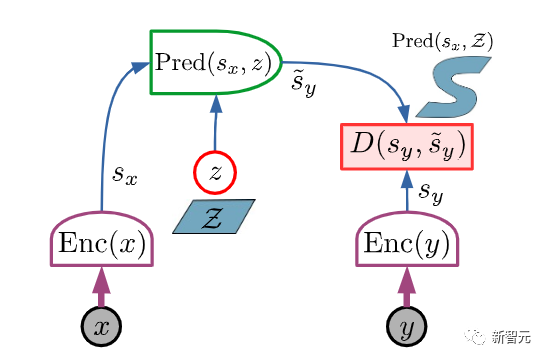
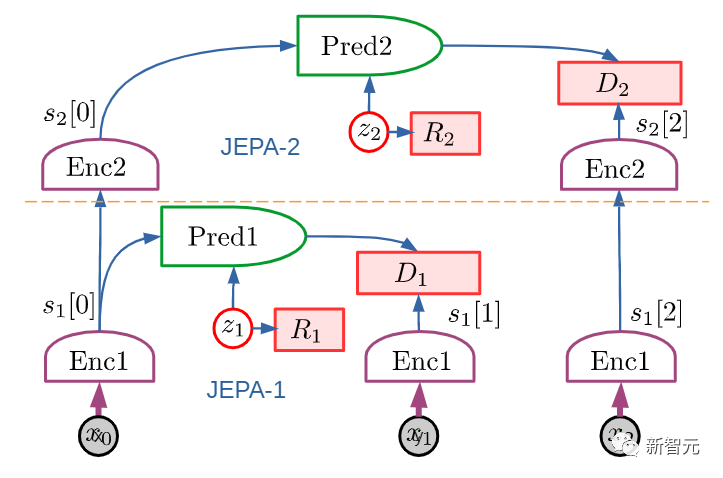
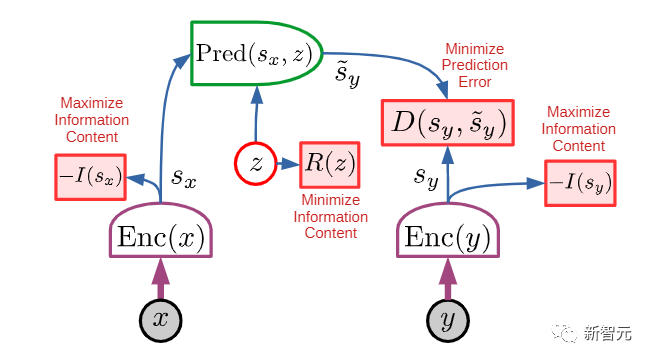
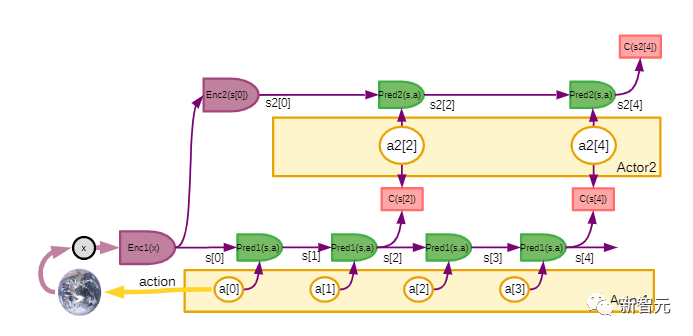
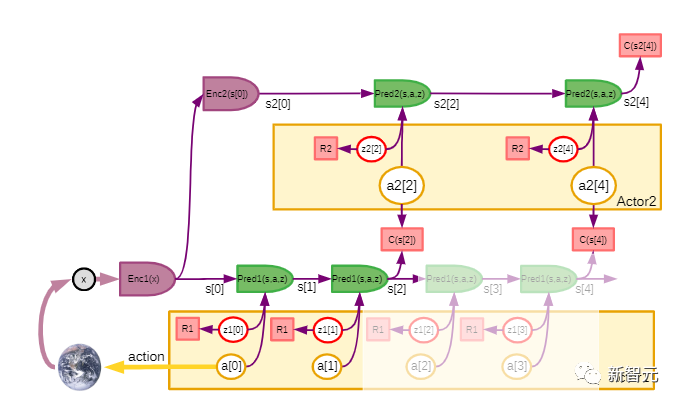
文中结合了一些概念,如可配置的预测世界模型,通过内在动机驱动的行为,以及用自监督学习训练的分层联合嵌入架构。LeCun表示,这篇文章的主要观点,就是他一个多月前在Facebook博客上已经陈述过的一些观点。他认为,不存在「AGI」这种东西。不如现实一点 ,追求达到 「人类水平的AI」(HLAI)。目前我们正在朝着HLAI取得一些进展,扩大模型的规模有点用,但还不够,因为目前我们仍然缺少一些基本概念。其中一些新概念可能 「就在眼前」(如广义自监督学习)。但我们不知道需要多少这样的新概念。现在我们只是看到其中最显而易见的那部分概念。因此,无法预测要花多长时间才能达到人类水平的AI。1、提出了一个整体认知架构,其中所有模块都是可区分的,其中许多模块是可训练的。自主智能(autonomous intelligence)的系统架构2、提出了一种用于学习表示层次结构的预测世界模型的非生成架构 JEPA 和分层 JEPA:联合嵌入预测架构 (JEPA) 由两个编码分支组成3. 一种非对比的自我监督学习范式,它产生的表征同时具有信息性和可预测性JEPA 的主要优点在于可以使用非对比方法进行训练4. 一种使用 H-JEPA 作为预测世界模型基础的方法,用于不确定性下的分层规划。LeCun表示,虽然AGI搞不成,但上面这些工具和方法可能会让我们离「人类水平的自主智能」更近一些。另外他还说,这些架构、思路和方法有些不是他首先提出来的,他只是将其整合成了一套互相相关的架构,免不了有参考文献忘记列出,欢迎指正。LeCun 表示,本文提出的架构不是专门设计来模拟人类和其他动物的自主智能、推理和学习,但确实有一些相似之处。该架构中的许多模块,在哺乳动物中都有对应的模块:比如具有相似功能的大脑、感知模块对应于视觉、听觉和其他感觉区域以及一些相关区域。本文中的架构构建了单一的世界模型引擎。LeCun认为,这不仅可以通过硬件重用提供计算优势,还可以让知识在多个任务之间共享。一直以来,存在一个假设,即「人类大脑中存在一个单一的、可配置的世界模型引擎」。这可能解释了为什么人类本质上可以一次执行单一的「有意识的」推理和规划任务。动物和人类情感的基础是瞬时情绪(如痛苦、快乐、饥饿等),这可能是大脑结构的作用效果,其意义是类似于所提的架构中的「内在成本」模块。其他情绪,如恐惧或高兴,可能是大脑结构预期结果的结果。本文提出的这类自主智能体将会拥有类似于情感的东西。就像动物和人类一样,机器的情感是内在成本的产物。人们普遍认为,目前的AI系统都不具备任何程度的常识,甚至连家猫的常识都没有。而动物似乎能够获得足够的关于世界如何运作的背景知识,从而表现出一定程度的常识。LeCun推测,常识可能会从学习世界模型中产生,它会捕捉到世界上观察的自我一致性和相互依赖性,允许代理填补缺失的信息,并发现违反其世界模型的行为。近年来,大型语言模型,尤其是Transformer架构,在文本生成和智能对话方面取得了惊人的成功。这在AI社区引发了一场辩论——是否可以通过扩大这些架构的规模,来实现人类级别的AI。LeCun认为,并不行,主要有两个原因:首先,当前的模型操作的是「标记化」数据,并且是生成的。这些数据受到生成模型、潜在变量自由模型和对比方法的限制。生成模型难以表示连续空间中复杂的不确定性。其次,目前的模型只能进行非常有限的推理。在这样的模型中动态地指定目标基本上是不可能的。在大多数强化学习设置中,奖励是由环境提供给智能体的。换句话说,训练的内在成本是环境本身,是一个未知函数。一个纯粹的强化学习系统,甚至需要大量的试验来学习相对简单的任务。而如果要通过预测世界状态来训练模型,奖励显然是不够的,因为系统中的大多数参数被训练来预测世界上的大量观测。参考资料:
https://openreview.net/forum?id=BZ5a1r-kVsf
https://www.facebook.com/yann.lecun/posts/10158256523332143