
Hive之同比环比的计算
关注公众号:大数据技术派,回复: 资料,领取1024G资料。
目录
同比环比的计算
测试数据
销售量的月年占比
同比环比
同比环比的计算
测试数据
1,2020-04-20,420
2,2020-04-04,800
3,2020-03-28,500
4,2020-03-13,100
5,2020-02-27,300
6,2020-01-07,450
7,2019-04-07,800
8,2019-03-15,1200
9,2019-02-17,200
10,2019-02-07,600
11,2019-01-13,300
CREATE TABLE ods_saleorder (
order_id int ,
order_time date ,
order_num int
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
;
LOAD DATA LOCAL INPATH '/Users/liuwenqiang/workspace/hive/saleorder.txt' OVERWRITE INTO TABLE ods.ods_saleorder;
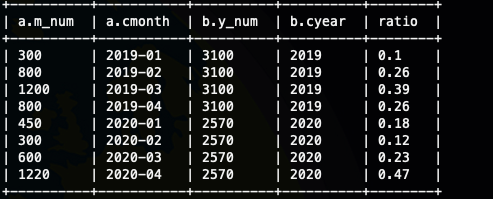
销售量的月年占比
关联实现
select
a.m_num,a.cmonth,b.y_num,b.cyear,round( m_num / y_num, 2 ) AS ratio
from(
select
sum(order_num) as m_num,
DATE_FORMAT(order_time,'yyyy-MM') as cmonth
from
ods_saleorder
group by
DATE_FORMAT(order_time,'yyyy-MM')
) a
inner join
(
select
sum(order_num) as y_num,
DATE_FORMAT(order_time,'yyyy') as cyear
from
ods_saleorder
group by
DATE_FORMAT(order_time,'yyyy')
) b
on
substring(a.cmonth,1,4)=b.cyear
;
窗口实现
SELECT
order_month,
num,
total,
round( num / total, 2 ) AS ratio
FROM
(
select
substr(order_time, 1, 7) as order_month,
sum(order_num) over (partition by substr(order_time, 1, 7)) as num,
sum(order_num) over (partition by substr( order_time, 1, 4 ) ) total,
row_number() over (partition by substr(order_time, 1, 7)) as rk
from ods_saleorder
) temp
where rk = 1;
同比环比
与上年度数据对比称"同比",与上月数据对比称"环比"。相关公式如下:
同比增长率计算公式
(当年值-上年值)/上年值x100%
环比增长率计算公式
(当月值-上月值)/上月值x100%
####lead lag 的实现
这里我们就用环比做个例子,同比类似
select
now_month,
now_num,
last_num,
round( (now_num-last_num) / last_num, 2 ) as ratio
FROM(
select
now_month,
now_num,
lag( t1.now_num, 1) over (order by t1.now_month ) as last_num
from
(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) t1
) t2;
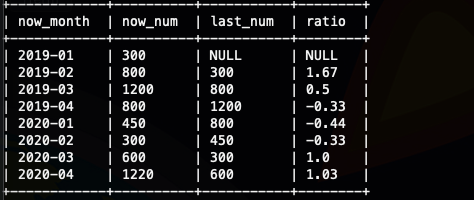
我们看到有null 值,这里我们可以使用,lag的默认值做一次优化
select
now_month,
now_num,
last_num,
-- 分母是0的话返回值是null
nvl(round( (now_num-last_num) / last_num, 2 ),0)as ratio
FROM(
select
now_month,
now_num,
lag( t1.now_num, 1,0) over (order by t1.now_month ) as last_num
from
(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) t1
) t2;
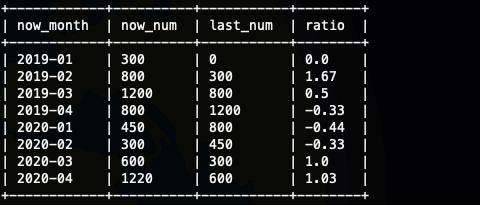
其实到这里我们就处理完了,但是这样真的对吗,我们看到'2020-01' 的last_num 是800 也就是'2019-04',其实到这里我们就明白了,我们的数据是不连续的,所以我们这样计算是不行的,如果每个月都齐全,都有数据lag(num,12)就可以。
那就只能做自关联了,这样的话我们可以对时间做精准的限制
自关联的实现
with a as (
select
now_month,
now_num,
substr(date(concat(now_month,'-','01')) - INTERVAL '1' month, 1, 7) as last_month
from(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) tmp
)
select
a1.now_month,a1.now_num,a1.last_month,a2.now_num,
nvl(round( (a1.now_num-a2.now_num) / a2.now_num, 2 ),0) as ratio
from
a a1
inner join
a a2
on
a1.last_month=a2.now_month
;
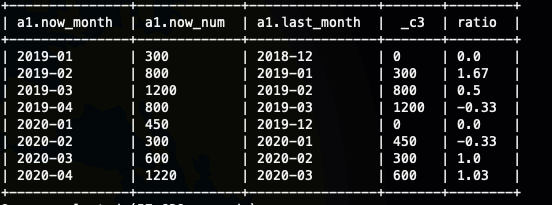
这里的时间计算INTERVAL 你也可以换成其他函数
with a as (
select
now_month,
now_num,
substr(add_months(concat(now_month,'-','01'),-1), 1, 7) as last_month
from(
select
substr(order_time, 1, 7) as now_month,
sum(order_num) as now_num
from ods_saleorder
group by
substr(order_time, 1, 7)
) tmp
)
select
a1.now_month,a1.now_num,a1.last_month,nvl(a2.now_num,0),
nvl(round( (a1.now_num-a2.now_num) / a2.now_num, 2 ),0) as ratio
from
a a1
left join
a a2
on
a1.last_month=a2.now_month
;
猜你喜欢
评论