
小样本图像生成新作 | Adobe团队
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
丰色 发自 凹非寺 量子位 报道 | 公众号 QbitAI
假如一位大师画了一些画,但是只有10幅,有没有可能利用这仅有的10幅训练出一个模型,产生N幅同样风格的作品来呢?
从目前的图像生成模型来看,似乎不行。
因为它们都需要至少数千张图像才能正常训练,10张真是“为难我胖虎”了。
但办法总比困难多。
来自Adobe Search等团队的研究人员们提出了一种新颖的GAN自适应框架。
该框架经过实验证明,能够发现小样本模型源域和目标域之间的对应关系,用10幅也能生成千变万化,质量也有的保证的图像!
怎么做到的?!
如何保证多样化和真实
要想解决有限的数据样本,就不得不提迁移学习。
它是一种不需要海量数据就能让计算机“举一反三”的方法,已在GAN的背景下进行了多种摸索。
然而这些方法中的大多数都是为具有一百多个训练图像的场景而设计的。
当可用图像的数量降低到只有几个时,结果势必导致过拟合或图像质量较差。
为了解决过拟合这个问题,研究人员在迁移学习的基础上引入了一种新的跨域距离一致性损失算法 (cross-domain distance consistency loss),它可以保持源图像之间的相似性和差异性。如下图第三行所示。

△将源模型(第一行)调整为小样本后,结果由于过拟合而垮掉(第二行)
跨域距离一致性损失算法怎么实现
自适应过程中过拟合的结果就是源域中的相对距离无法保持。如上图第二行所示。
研究人员假设,在自适应前后强制保持成对距离,将有助于防止崩溃。
为此,他们对一批N+1个噪声向量进行采样,并利用它们在特征空间中的成对相似性为每幅图像构造N路概率分布。
并从最新的对比学习中受到启发。
该方法将相似性转换为无监督表征学习的概率分布,以及感知特征损失,并表明在区分性网络的多个层次上的激活有助于保持相似性。
另外,研究人员觉得有必要应用图像级和图像块级对抗损失这两种不同的方式来避免对生成图像的多样性造成过度的惩罚:
对应该映射到真实样本的合成图像运用图像级的对抗损失,对于其他合成图像,则只运用图像块级的对抗损失。
这样,生成的样本中只有一小部分需要看起来像训练图像,而其余部分只需要捕获训练图像的块级特征。
这样,生成图像的多样性就大大增加了。
为了保证图像的质量,研究人员又提出了一个叫做“relaxed” 的判别器,它能使隐空间(latent space)的不同区域具有不同层次的真实感。
效果怎么样?
团队进行了以下三个方面的评估:
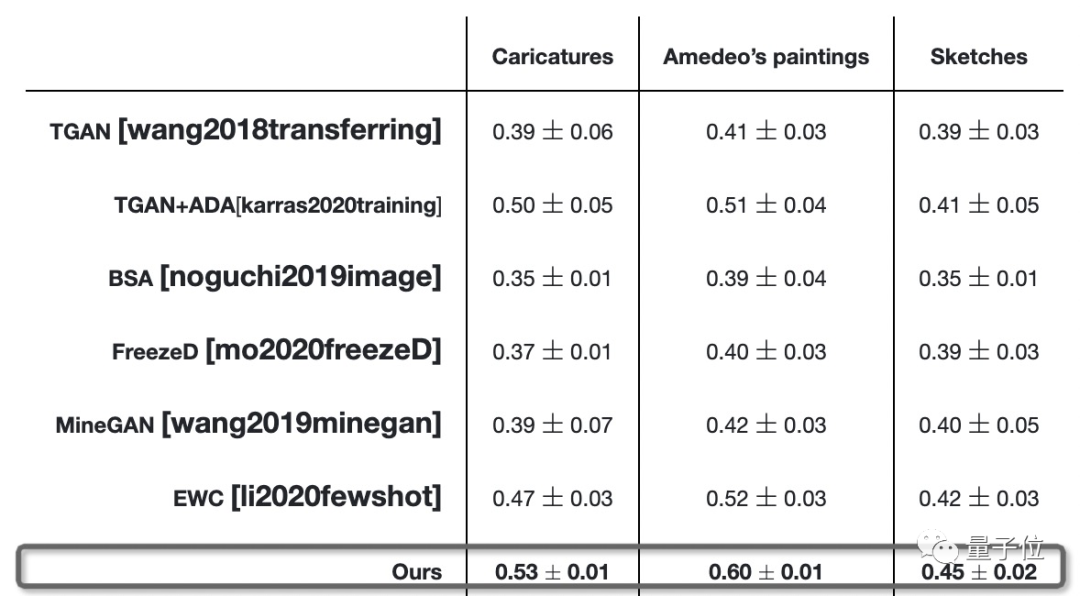
质量和多样性评估
定性比较发现,比起TGAN、MineGAN的过拟合,TGAN + ADA那离谱的旋转90度的失真等,
还是该研究团队的方法能够更贴切地捕捉原图的特征,生成各具特色的头像,
并照顾到其他方法没有顾及的细节(eg.草图中的帽子),多样性和质量一应俱全。

定量比较发现,该方法一致实现了更高的平均LPIPS(深度特征度量图像相似度的有效性)距离,这表明生成的图像更清晰。
源域和目标域间的对应关系
当源域和目标域相关时(eg. 人脸和人物漫画),使用该团队的方法生成的结果具有清晰的对应关系。任何细节(eg. 帽子/太阳镜)都在最终生成的草图和漫画中得以体现。(同见上面的大图)
当源域目标域不相关时,生成的结果仅模拟了目标域的外观。对于所有剩余细节,并不能准确地捕获目标分布。然而,仍然会出现部分级别的对应。eg. 教堂的窗户/门大致映射为漫画的眼睛。

这就有点鬼畜了哈。
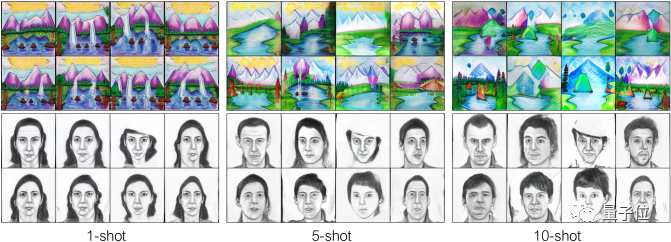
目标数据集规模对生成图像的质量和多样性的影响
上面所有结果都是由每个目标域10个训练图像生成的。
现在,研究人员分别以1、5、10个训练图像来实现Church→Landscape drawing(教堂变风景画)和FFHQ→sketch(人物到人物漫画)。
可以发现,只有一个样本时,该方法引起了细微变化,例如在生成的草图中,女士以不同的姿势出现,山和瀑布具有不同的形状。
训练图像增加为5个,这些草图中的人物有了性别与年龄大小等更明显的区分。
进一步增加训练样本的数量(到10个)后,可以为人物和风景引入更多细节,以至于在最终的外观上有了很大的差别。
也有瑕疵:红色汽车变橙色
虽然该团队的方法产生了令人信服的结果,但它并非没有局限性。
比如,下图中的“汽车变废弃汽车”中,红色汽车的颜色在其废弃形式中变为了橙色。
可能是因为10个训练图像中存在橙色汽车。
“FFHQ→太阳镜”中人物戴上墨镜,金色头发就变黑。

这表明,源域和目标域之间更好的对应关系还需进一步探索。
参考链接:
https://www.arxiv-vanity.com/papers/2104.06820/
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》