谷歌量子计算团队再发Nature!逻辑错误抑制实现100倍增长,或为容错量子计算机研发铺平道路

大数据文摘授权转载自学术头条
作者:库珀
编审:寇建超
谈起量子计算,大多数人只有模糊的概念,这是一项高深且极具革命性的计算技术,能完成目前世界上最先进的传统计算机不可能完成,或者需要极长时间才能完成的计算任务。
2019 年,Nature 曾以封面的形式刊登了一篇谷歌量子计算首次实现量子优越性的论文,在实验中,谷歌量子计算机基于 54 量子位处理器,只用了 200 秒就完成了世界第一超算需要计算1万年才能算出的结果,揭示了量子计算机的巨大潜能。

量子计算机最突出的优势是可以对数据进行同时处理计算,但其发展瓶颈也很明显,例如目前量子比特数不够多,纠错容错技术也有待完善,这些因素都大大限制了量子计算的普及实用。因此,包括各国工业界、学术界和国家实验室的科研人员都在寻求减少量子计算机错误的方法。
就在今天,谷歌量子人工智能(Google AI Quantum)团队的一篇论文再次刊登在 Nature 杂志上,研究人员基于谷歌量子处理器“悬铃木”(Sycamore)实现了量子计算错误抑制的指数级增长。

(来源:Nature)
研究数据表明,研究人员将重复码基于的量子比特数量从 5 个提高到 21 个,对逻辑错误的抑制实现了最多 100 倍的指数级增长,这种错误抑制能力在 50 次纠错实验中均表现稳定,或为可推进容错量子计算机的研发铺平道路。
尽管实验中提及的错误率还没达到实现量子计算机潜力的阈值,但这一研究成果已经证明了量子纠错(quantum error-correction,QEC)可以成功将错误率控制在一定范围内。研究人员认为“悬铃木”架构或已逼近这一阈值,结果令人振奋。
改善错误率的路径
改善错误率的路径
实现量子计算的潜力需要足够低的逻辑错误率,许多应用程序要求错误率低至 1/(10^15),即 10的负 15 次方,但目前最先进的量子平台的物理错误率通常才接近 1/(10^3)。
而量子纠错通过将量子逻辑信息分布在许多物理量子位上,使得错误可以被检测和纠正,从而有望弥合这一鸿沟。
编码的逻辑量子位状态上的错误可以随着物理量子位数量的增长而指数地被抑制,但前提是物理错误率低于某个阈值并且在计算过程中保持稳定。
在这项研究中,研究人员实现了嵌入在超导量子比特的二维网格中的一维重复码,证明了位翻转或相位翻转错误的指数抑制,当量子比特数从 5 增加到 21 时,逻辑错误减少了 100 倍以上。
许多量子纠错体系结构是建立在稳定码的基础上的,其中逻辑量子位是在多个物理量子位的联合状态下编码的,研究人员称之为数据量子位。
称为测量量子位的附加物理量子位与数据量子位隔行扫描,并用于周期性地测量所选数据量子位组合的奇偶性。这些投射稳定器测量将数据量子态的不希望的扰动变成离散误差,研究人员通过寻找奇偶性的变化来跟踪这些误差,然后可以对奇偶校验值流进行解码,以确定发生的最可能的物理错误。
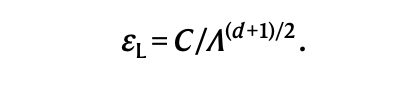
图|每轮纠错的逻辑错误概率比例缩放公式(来源:Nature)
以前的许多实验已经证明了稳定码在各种平台上的运行原理,如核磁共振、离子阱和超导量子位等。然而,这些结果不能外推到大系统中的指数误差抑制,除非对串扰等非理想特性有很好的理解。此外,指数误差抑制以前没有用循环稳定器测量来证明,这是容错计算的一个关键要求。
研究人员此次在测量过程中也引入了误差机制,如状态泄漏、加热和数据量子位退相干,并运行了两个稳定器代码。在重复码中,量子位在一维链中的量子位和数据量子位之间交替,每个量度量子位检查其两个相邻量子位的奇偶性,所有量子位检查相同的基,以便逻辑量子位不受错误的影响。
改进的“悬铃木”处理器
改进的“悬铃木”处理器
在硬件方面,研究人员基于“悬铃木”(Sycamore)处理器来实现量子纠错,它由一个二维的量子位阵列组成,其中每个量子比特可调谐地耦合到四个最近的邻域,即表面代码所需的连接性。
该处理器具有改进的读出电路设计,允许以更少的串扰进行更快的读出,并且每量子位的读出误差减少 2 倍,和它的前身一样,这个处理器有 54 个量子位,但研究人员最多使用了 21 个量子位,因为只有处理器的一个子集连接起来了。
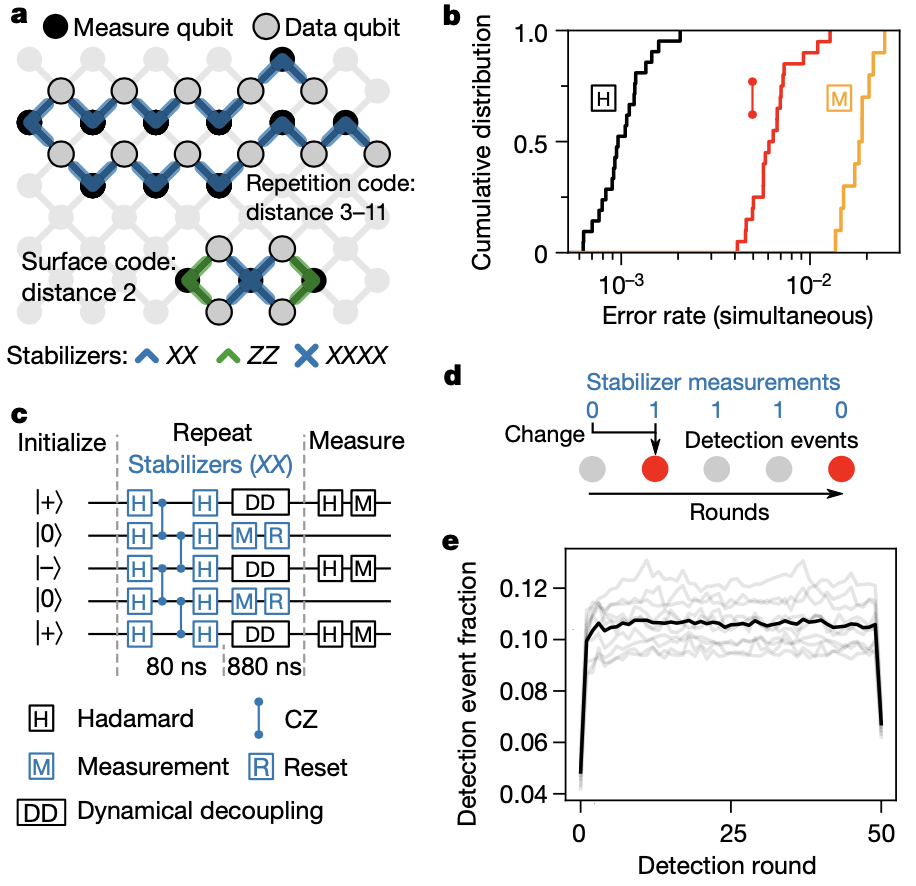
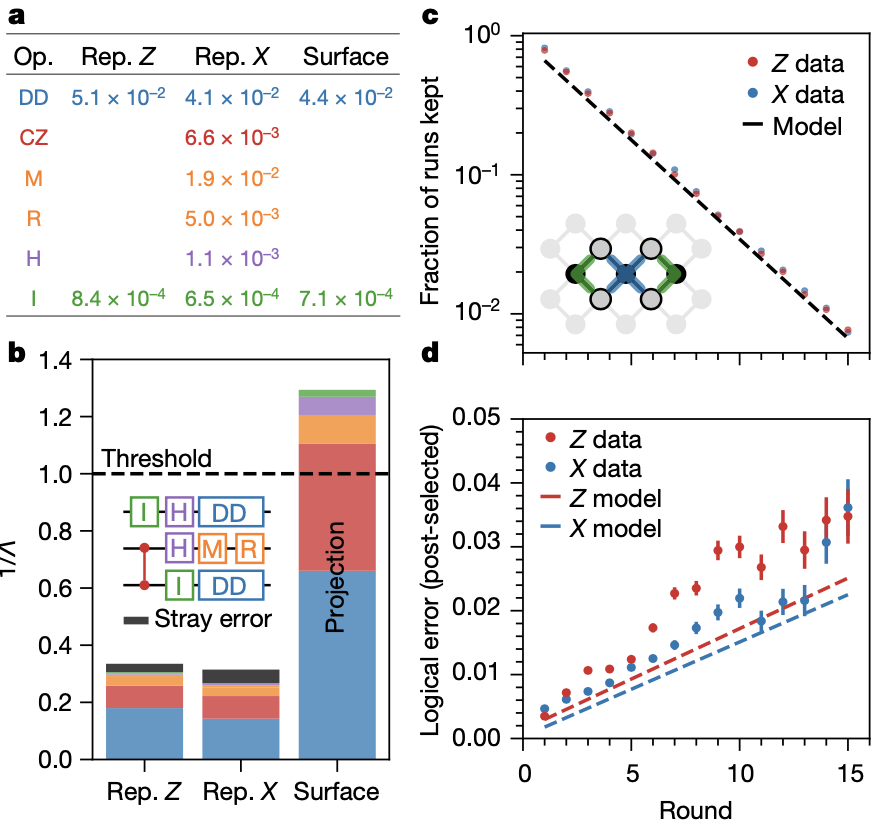
图|“悬铃木”上的稳定器电路概念图,构成稳定器电路的操作错误率以及相位翻转码电路示意图等(来源:Nature)
据论文描述,此次实验利用了“悬铃木”结构的门校准的最新进展。
首先,研究人员通过将每个量子位的频率扫过读出谐振器的频率,从激发态(包括非计算态)中移除布居。这种复位操作附加在量子纠错电路中的每次测量之后,并在 280ns 内产生误差低于 0.5% 的基态;
然后,他们利用两个量子位元的联合态(1,1)和(0,2)之间的直接交换来实现一个 26ns 受控 Z(CZ)门,可调量子比特-量子比特耦合允许这些CZ门以高并行度执行,并且在重复代码中同时执行多达10个CZ门;
最后,使用量子纠错的结果来校准每个 CZ 门的相位校正,同时利用交叉熵对标,结果发现发现 CZ 门泡利平均误差为 0.62%。
研究人员将重复码实验的重点放在位相翻转码上,在位相翻转码中,数据量子位占据了对能量弛豫和退相都很敏感的叠加态,这使得它的实现比位相翻转码更具挑战性,也更能预测表面码的性能。在测量和复位期间,数据量子位被动态解耦,以保护数据量子位免受各种退相源的影响。
研究人员分析实验数据的第一步是将测量结果转化为错误检测事件,即相邻回合之间相同测量量子位的测量结果变化,他们将检测事件的每个可能时空位置(即特定量子位和圆)称为检测节点,对于 50 轮 21 量子位相位翻转码中的每个检测节点,他们都绘制了在该节点上观察到检测事件的实验分数。
在第一轮和最后一轮检测中,检测事件的分数与其他轮相比有所降低。在这两个时间边界回合中,通过比较第一个稳定器测量和数据量子位初始化来发现检测事件。因此,在时间边界回合中的测量量子位读出期间,数据量子位不受消相干的影响,这说明了多回合运行量子纠错对准确基准性能的重要性。
除了这些边界效应,研究人员还观察到平均检测事件分数为 11%,并且在所有 50 轮实验中都是稳定的,这是量子纠错可行性的关键发现。
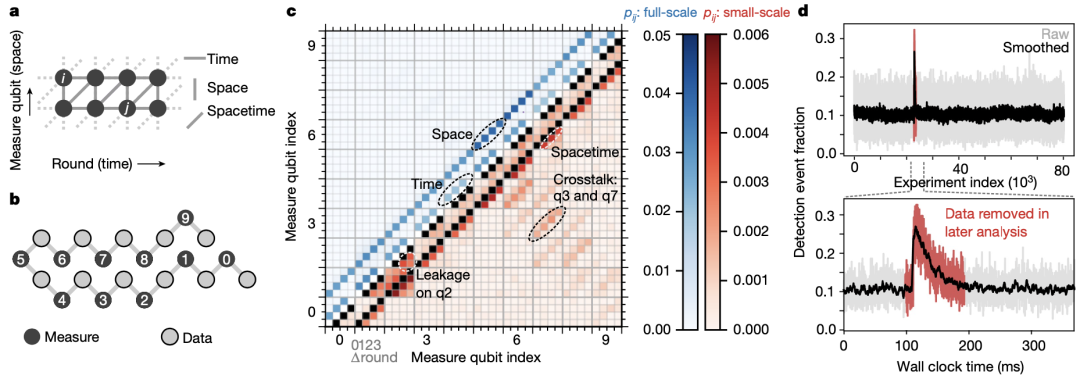
图|错误检测分析(来源:Nature)
接下来,研究人员描述了检测事件之间的成对相关性。通过计算任意一对检测节点之间的相关概率来检验“悬铃木”处理器是否符合期望,正如预期的那样,最明显的相关性要么是类空间的,要么是类时间的。
此外,他们还观察到一些偶发事件大大降低了重复代码的性能,未来通过改进设备设计或屏蔽来缓解这些事件,对于实现具有超导量子比特的大规模容错计算机至关重要。
图|错误和表面码(来源:Nature)
重要的研究方向
重要的研究方向
为了更好地理解本研究中的重复编码结果和设备的投影表面编码性能,研究人员用去极化噪声模型模拟了实验,这意味着在每次操作后都有可能注入随机泡利误差(X、Y 或 Z),使用平均错误率计算每种操作类型的泡利错误概率。总的来说,∧ 的测量值比模拟值差约 20%,研究人员将其归因于泄漏和串扰误差等机制,但未包括在模拟中。
关于下一步研究,研究人员表示,必须提高“悬铃木”的整体性能才能观察到表面码的错误抑制。
展望未来,我们在实现可伸缩量子纠错的道路上依然存在许多挑战。但此次研究中的误差预算则指出了达到表面编码阈值所需的重要研究方向:在测量和复位过程中减少 CZ 门误差和数据量子位误差,跨过这个门槛将是量子计算的一个重要里程碑。
然而,实际的量子计算需要 ∧≈10(表示 1000:1 的合理物理与逻辑量子比特比),达到 ∧≈ 10 将需要大幅度降低操作错误率,并且需要进一步研究高能粒子等错误机制的缓解。
参考资料:
https://www.nature.com/articles/s41586-021-03588-y