
k8s调度器启动流程分析 | 视频文字稿
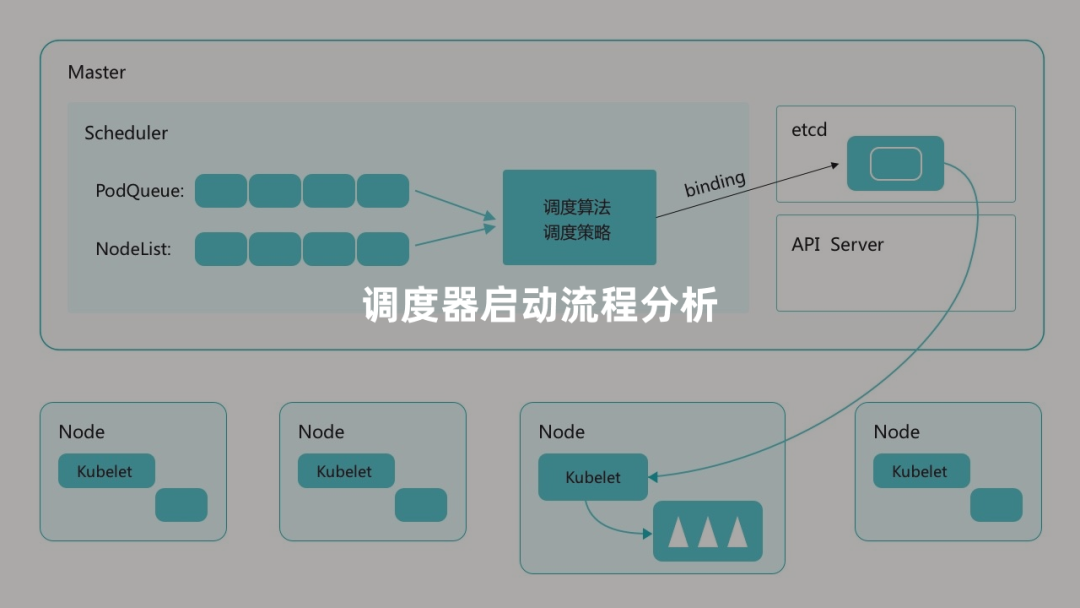
本文主要对 Kubernetes 调度器(v1.19.3版本)初始化启动过程进行分析。kube-scheduler 组件有很多可以配置的启动参数,其核心也是通过 cobra 开发的一个 CLI 工具,所以要掌握 kube-scheduler 的启动配置,需要我们对 cobra 有一个基本的了解,kube-scheduler 主要有两种类型的配置参数:
调度策略相关的参数,例如启用那些调度插件,以及给某些调度插件配置一些参数 通用参数,就是一些普通的参数,比如配置服务端口号等等
这里我们主要是了解调度器的核心调度框架和算法,所以主要关注第一种参数即可。
参数配置
kube-scheduler 的启动入口位于 cmd/kube-scheduler/scheduler.go 文件,该文件中就包含一个 main 入口函数:
// cmd/kube-scheduler/scheduler.go
func main() {
rand.Seed(time.Now().UnixNano())
// 初始化 Cobra.Command 对象
command := app.NewSchedulerCommand()
// 将命令行参数进行标准化(_替换成-)
pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
// 初始化日志
logs.InitLogs()
defer logs.FlushLogs()
// 执行命令
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
其中最核心的就是通过 app.NewSchedulerCommand() 或者一个 Cobra 的 Command 对象,然后最下面调用 command.Execute() 函数执行这个命令,所以核心就是 NewSchedulerCommand 函数的实现:
// cmd/kube-scheduler/app/server.go
// Option 配置一个 framework.Registry
type Option func(runtime.Registry) error
// NewSchedulerCommand 使用默认参数和 registryOptions 创建一个 *cobra.Command 对象
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
// 获取默认的配置信息
opts, err := options.NewOptions()
if err != nil {
klog.Fatalf("unable to initialize command options: %v", err)
}
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: `......`,
// 真正执行的函数入口
Run: func(cmd *cobra.Command, args []string) {
if err := runCommand(cmd, opts, registryOptions...); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
},
......
}
......
return cmd
}
如果我们熟悉 Cobra 的基本用法的话应该知道当我们执行 Cobra 的命令的时候,实际上真正执行的是 Cobra.Command 对象中的 Run 函数,也就是这里的 runCommand 函数:
// cmd/kube-scheduler/app/server.go
if err := runCommand(cmd, opts, registryOptions...); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
其中有两个非常重要的参数 opts 与 registryOptions,opts 是一个 Options 对象,该参数包含所有的运行 Scheduler 需要的参数:
// cmd/kube-scheduler/app/options/options.go
// Options 拥有所有运行 Scheduler 需要的参数
type Options struct {
// 默认值,如果设置了 ConfigFile 或 InsecureServing 中的值,这些设置将被覆盖
// KubeSchedulerConfiguration 类似与 Deployment 都是k8s的资源对象,这是这个对象是用于配置调度器使用的
ComponentConfig kubeschedulerconfig.KubeSchedulerConfiguration
SecureServing *apiserveroptions.SecureServingOptionsWithLoopback
// 可为 Healthz 和 metrics 配置两个不安全的标志
CombinedInsecureServing *CombinedInsecureServingOptions
Authentication *apiserveroptions.DelegatingAuthenticationOptions
Authorization *apiserveroptions.DelegatingAuthorizationOptions
Metrics *metrics.Options
Logs *logs.Options
Deprecated *DeprecatedOptions
// ConfigFile 指定是调度程序服务的配置文件的位置
ConfigFile string
// WriteConfigTo 将默认配置写入的文件路径
WriteConfigTo string
Master string
}
其中第一个参数 ComponentConfig kubeschedulerconfig.KubeSchedulerConfiguration 是我们需要重点关注的用于配置调度策略相关参数的地方,通过 NewOptions() 来获取默认配置参数:
// cmd/kube-scheduler/app/options/options.go
// NewOptions 返回一个默认的调度器应用 options 参数。
func NewOptions() (*Options, error) {
cfg, err := newDefaultComponentConfig()
if err != nil {
return nil, err
}
......
o := &Options{
ComponentConfig: *cfg,
......
}
......
return o, nil
}
上面是初始化 Options 的函数,这里我们只关心核心的 ComponentConfig 参数,该参数是通过函数 newDefaultComponentConfig() 来生成默认的配置:
// cmd/kube-scheduler/app/options/options.go
func newDefaultComponentConfig() (*kubeschedulerconfig.KubeSchedulerConfiguration, error) {
versionedCfg := kubeschedulerconfigv1beta1.KubeSchedulerConfiguration{}
// 可用于配置是否开启 Debug 相关特性,比如 profiling
versionedCfg.DebuggingConfiguration = *configv1alpha1.NewRecommendedDebuggingConfiguration()
kubeschedulerscheme.Scheme.Default(&versionedCfg)
cfg := kubeschedulerconfig.KubeSchedulerConfiguration{}
if err := kubeschedulerscheme.Scheme.Convert(&versionedCfg, &cfg, nil); err != nil {
return nil, err
}
return &cfg, nil
}
上面的函数会创建一个默认的 KubeSchedulerConfiguration 对象,用于配置调度器,默认配置参数通过 Options 构造完成后,在构造整个 cobra.Command 命令后会为其添加命令行参数:
// cmd/kube-scheduler/app/server.go
// NewSchedulerCommand 使用默认参数和 registryOptions 创建一个 *cobra.Command 对象
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
// 获取默认的配置信息
opts, err := options.NewOptions()
if err != nil {
klog.Fatalf("unable to initialize command options: %v", err)
}
cmd := &cobra.Command{
......
}
fs := cmd.Flags()
// 调用 Options 的 Flags 方法
namedFlagSets := opts.Flags()
verflag.AddFlags(namedFlagSets.FlagSet("global"))
globalflag.AddGlobalFlags(namedFlagSets.FlagSet("global"), cmd.Name())
// 将默认的所有参数添加到 cmd.Flags 中去
for _, f := range namedFlagSets.FlagSets {
fs.AddFlagSet(f)
}
......
return cmd
}
其中的 opts.Flags() 方法就是将默认的 Options 配置转换成命令行参数的函数:
// cmd/kube-scheduler/app/options/options.go
func (o *Options) Flags() (nfs cliflag.NamedFlagSets) {
fs := nfs.FlagSet("misc")
fs.StringVar(&o.ConfigFile, "config", o.ConfigFile, `The path to the configuration file. The following flags can overwrite fields in this file:
--address
--port
--use-legacy-policy-config
--policy-configmap
--policy-config-file
--algorithm-provider`)
fs.StringVar(&o.WriteConfigTo, "write-config-to", o.WriteConfigTo, "If set, write the configuration values to this file and exit.")
fs.StringVar(&o.Master, "master", o.Master, "The address of the Kubernetes API server (overrides any value in kubeconfig)")
o.SecureServing.AddFlags(nfs.FlagSet("secure serving"))
o.CombinedInsecureServing.AddFlags(nfs.FlagSet("insecure serving"))
o.Authentication.AddFlags(nfs.FlagSet("authentication"))
o.Authorization.AddFlags(nfs.FlagSet("authorization"))
o.Deprecated.AddFlags(nfs.FlagSet("deprecated"), &o.ComponentConfig)
options.BindLeaderElectionFlags(&o.ComponentConfig.LeaderElection, nfs.FlagSet("leader election"))
utilfeature.DefaultMutableFeatureGate.AddFlag(nfs.FlagSet("feature gate"))
o.Metrics.AddFlags(nfs.FlagSet("metrics"))
o.Logs.AddFlags(nfs.FlagSet("logs"))
return nfs
}
其中第一个参数 --config 就可以用来指定配置文件。到这里我们就获取到了调度器所有默认的配置参数了。
启动调度器
接下来分析真正运行调度器的 runCommand 函数的实现。
// cmd/kube-scheduler/app/server.go
// 运行调度器的真正函数
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
// 比如执行 --version 这样的操作,则打印版本后直接退出了
verflag.PrintAndExitIfRequested()
cliflag.PrintFlags(cmd.Flags())
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 根据命令行 args 和 options 创建完整的配置和调度程序
cc, sched, err := Setup(ctx, opts, registryOptions...)
if err != nil {
return err
}
// 如果指定了 WriteConfigTo 参数
if len(opts.WriteConfigTo) > 0 {
// 将配置写入到指定的文件中
if err := options.WriteConfigFile(opts.WriteConfigTo, &cc.ComponentConfig); err != nil {
return err
}
klog.Infof("Wrote configuration to: %s\n", opts.WriteConfigTo)
return nil
}
// 真正去启动调度器
return Run(ctx, cc, sched)
}
上面的函数首先判断是否是执行类似于 --version 这样的操作,如果是这打印后直接退出,然后根据命令行参数和选项通过 Setup 函数构造 CompletedConfig 配置和 Scheduler 调度器对象。
// cmd/kube-scheduler/app/server.go/
// 根据命令行参数和选项构造完整的配置和调度器对象
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
// 校验命令行选项
if errs := opts.Validate(); len(errs) > 0 {
return nil, nil, utilerrors.NewAggregate(errs)
}
// 获取调度器Config对象,该对象拥有一个调度器所有的上下文信息
c, err := opts.Config()
if err != nil {
return nil, nil, err
}
// 获取 completed 配置
cc := c.Complete()
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
recorderFactory := getRecorderFactory(&cc)
// 创建调度器
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
cc.PodInformer,
recorderFactory,
ctx.Done(),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
)
if err != nil {
return nil, nil, err
}
return &cc, sched, nil
}
该函数首先调用 opts.Validate() 函数对所有参数进行校验,接着使用 opts.Config() 函数创建 *schedulerappconfig.Config 对象,该对象拥有一个调度器所有的上下文信息。
// cmd/kube-scheduler/app/options/options.go
// Config 返回一个调度器配置对象
func (o *Options) Config() (*schedulerappconfig.Config, error) {
......
c := &schedulerappconfig.Config{}
if err := o.ApplyTo(c); err != nil {
return nil, err
}
// 创建 kube 客户端
client, leaderElectionClient, eventClient, err := createClients(c.ComponentConfig.ClientConnection, o.Master, c.ComponentConfig.LeaderElection.RenewDeadline.Duration)
if err != nil {
return nil, err
}
......
c.Client = client
c.InformerFactory = informers.NewSharedInformerFactory(client, 0)
c.PodInformer = scheduler.NewPodInformer(client, 0)
c.LeaderElection = leaderElectionConfig
return c, nil
}
上面函数的核心是通过 o.ApplyTo(c) 函数将 Options 转换成了 *schedulerappconfig.Config 对象,
// cmd/kube-scheduler/app/options/options.go
// 将调度程序 options 转换成调度程序应用配置
func (o *Options) ApplyTo(c *schedulerappconfig.Config) error {
if len(o.ConfigFile) == 0 {
c.ComponentConfig = o.ComponentConfig
// 如果未加载任何配置文件,则应用 deprecated flags(这是旧的行为)
o.Deprecated.ApplyTo(&c.ComponentConfig)
if err := o.CombinedInsecureServing.ApplyTo(c, &c.ComponentConfig); err != nil {
return err
}
} else {
cfg, err := loadConfigFromFile(o.ConfigFile)
if err != nil {
return err
}
if err := validation.ValidateKubeSchedulerConfiguration(cfg).ToAggregate(); err != nil {
return err
}
c.ComponentConfig = *cfg
......
}
......
return nil
}
上面的转换函数会首先判断是否配置了 ConfigFile(也就是 --config 参数),如果配置了则会加载对应的配置文件转换成对应的 KubeSchedulerConfiguration 对象,然后校验有效性,如果都正常则将其赋给 schedulerappconfig.Config 的 ComponentConfig 属性;如果没有配置 ConfigFile,则使用旧的参数进行配置。
接着会去调用 scheduler.New() 函数去构造一个真正的调度器对象,该函数的具体实现如下所示:
// pkg/scheduler/scheduler.go
// 配置调度器
type Option func(*schedulerOptions)
var defaultSchedulerOptions = schedulerOptions{
profiles: []schedulerapi.KubeSchedulerProfile{
// Profiles 的默认插件是从算法提供程序配置的
{SchedulerName: v1.DefaultSchedulerName}, // 默认的调度器名称为 default-scheduler
},
schedulerAlgorithmSource: schedulerapi.SchedulerAlgorithmSource{
Provider: defaultAlgorithmSourceProviderName(), // 默认的算法源提供器名称为 DefaultProvider
},
percentageOfNodesToScore: schedulerapi.DefaultPercentageOfNodesToScore,
podInitialBackoffSeconds: int64(internalqueue.DefaultPodInitialBackoffDuration.Seconds()),
podMaxBackoffSeconds: int64(internalqueue.DefaultPodMaxBackoffDuration.Seconds()),
}
// 返回一个 Scheduler 对象
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
podInformer coreinformers.PodInformer,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
// 默认的调度器配置
options := defaultSchedulerOptions
for _, opt := range opts {
// 将默认的调度器配置调用 Option 重新配置一次
opt(&options)
}
......
var sched *Scheduler
// SchedulerAlgorithmSource 是调度程序算法的源
// 包含Policy与Provider两种方式,必须指定一个源字段,并且源字段是互斥的
source := options.schedulerAlgorithmSource
switch {
case source.Provider != nil:
// 从一个算法 provider 中创建配置,这是我们现在需要重点关注的方式
sc, err := configurator.createFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
case source.Policy != nil:
// 从用户指定的策略源中创建配置,这是以前的扩展方式
policy := &schedulerapi.Policy{}
......
default:
return nil, fmt.Errorf("unsupported algorithm source: %v", source)
}
......
// addAllEventHandlers 是在测试和 Scheduler 中使用的帮助程序函数,用于为各种 informers 添加事件处理程序
addAllEventHandlers(sched, informerFactory, podInformer)
return sched, nil
}
首先将默认的调度器配置通过传递的 Option 参数进行一一配置,然后重点就是根据应用过后的配置来判断调度算法的源是 Provider 还是 Policy 方式,我们现在的重点是调度框架,所以主要关注 Provider 这种配置,Policy 是以前的扩展调度器的方式。所以调度器的实例化核心是通过 configurator.createFromProvider(*source.Provider) 该函数来实现的。
// pkg/scheduler/factory.go
// 从一组已注册的插件集合中创建一个调度器
func (c *Configurator) create() (*Scheduler, error) {
var extenders []framework.Extender
var ignoredExtendedResources []string
if len(c.extenders) != 0 {
// Extender 方式扩展调度器
......
}
......
// Profiles 需要提供有效的 queue sort 插件
lessFn := profiles[c.profiles[0].SchedulerName].Framework.QueueSortFunc()
// 将优先级队列初始化为调度队列
podQueue := internalqueue.NewSchedulingQueue(
lessFn,
internalqueue.WithPodInitialBackoffDuration(time.Duration(c.podInitialBackoffSeconds)*time.Second),
internalqueue.WithPodMaxBackoffDuration(time.Duration(c.podMaxBackoffSeconds)*time.Second),
internalqueue.WithPodNominator(nominator),
)
......
// 创建一个 genericScheduler 对象,该对象实现了 ScheduleAlgorithm 接口,具体的调度实现就是这个对象实现的
algo := core.NewGenericScheduler(
c.schedulerCache,
c.nodeInfoSnapshot,
extenders,
c.informerFactory.Core().V1().PersistentVolumeClaims().Lister(),
c.disablePreemption,
c.percentageOfNodesToScore,
)
return &Scheduler{
SchedulerCache: c.schedulerCache,
Algorithm: algo,
Profiles: profiles,
NextPod: internalqueue.MakeNextPodFunc(podQueue),
Error: MakeDefaultErrorFunc(c.client, c.informerFactory.Core().V1().Pods().Lister(), podQueue, c.schedulerCache),
StopEverything: c.StopEverything,
SchedulingQueue: podQueue,
}, nil
}
// createFromProvider 从注册的算法提供器来创建调度器
func (c *Configurator) createFromProvider(providerName string) (*Scheduler, error) {
klog.V(2).Infof("Creating scheduler from algorithm provider '%v'", providerName)
// 获取算法提供器集合
r := algorithmprovider.NewRegistry()
// 获取指定算法提供器的插件集合
defaultPlugins, exist := r[providerName]
if !exist {
return nil, fmt.Errorf("algorithm provider %q is not registered", providerName)
}
for i := range c.profiles {
prof := &c.profiles[i]
plugins := &schedulerapi.Plugins{}
plugins.Append(defaultPlugins)
// Apply 合并来自自定义插件的插件配置
plugins.Apply(prof.Plugins)
prof.Plugins = plugins
}
return c.create()
}
通过上面的一些列操作后就实例化了真正的调度器对象,最后我们需要去启动一系列的资源对象的事件监听程序,比如 Pod、Node 等对象,上面实例化函数中通过 addAllEventHandlers(sched, informerFactory, podInformer) 来实现的,关于这些资源对象对应的 onAdd、onUpdate、onDelete 操作均在 pkg/scheduler/eventhandlers.go 文件中实现的,这样比如当创建一个 Pod 过后,我们的调度器通过 watch 就会在 onAdd 事件中接收到该操作,然后我们就可以根据 queue sort 插件将器加入到带调度队列中去开始调度了。
最后就是去调用 Run 函数来真正启动调度器了,首先会等待所有的 cache 同步完成,然后开始进行调度操作。
// cmd/kube-scheduler/app/server.go/
// Run 根据指定的配置执行调度程序,仅在出现错误或上下文完成时才返回
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
klog.V(1).Infof("Starting Kubernetes Scheduler version %+v", version.Get())
......
// 启动 healthz 以及 metrics 相关服务
......
// 启动所有 informers
go cc.PodInformer.Informer().Run(ctx.Done())
cc.InformerFactory.Start(ctx.Done())
// 调度之前等待所有 caches 同步完成
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// 开启了 leader election
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: sched.Run,
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// 如果没有开启 Leader election,这直接调用调度器对象的 Run 函数
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
// pkg/scheduler/scheduler.go
// 等待 cache 同步完成,然后开始调度
func (sched *Scheduler) Run(ctx context.Context) {
if !cache.WaitForCacheSync(ctx.Done(), sched.scheduledPodsHasSynced) {
return
}
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
在接下来的课程中我们就接着来分析是如何进行具体的 Pod 调度的。
 点击屏末 | 阅读原文 | 学习k8s开发课程
点击屏末 | 阅读原文 | 学习k8s开发课程