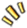关于Facebook故障的分析和反思
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
今天美国东部标准时间上午11点51分开始,Facebook出现故障,最终六个小时以后才恢复。很多平台(CloudFlare[1],ThousandEye[2])都做了故障归因. 本文的第一部分简要的概括一下故障原因,以翻译整理这两个参考网站资料为主, 第二个部分主要是从技术上和协议上分析分析一些缺陷, 最后一部分则是从管理的视角来看待基础架构团队的风险控制和激励机制。
Facebook瘫痪原因
按照好基友的说法,遇到如此大规模的瘫痪不是DNS就是BGP出了问题。但是很抱歉,这次是两个一起出了问题.
[UTC 15:40] ThousandEye监控到Facebook应用出现DNS失效的情况,然后 继而出现Authoritative DNS服务器不可达的情况:
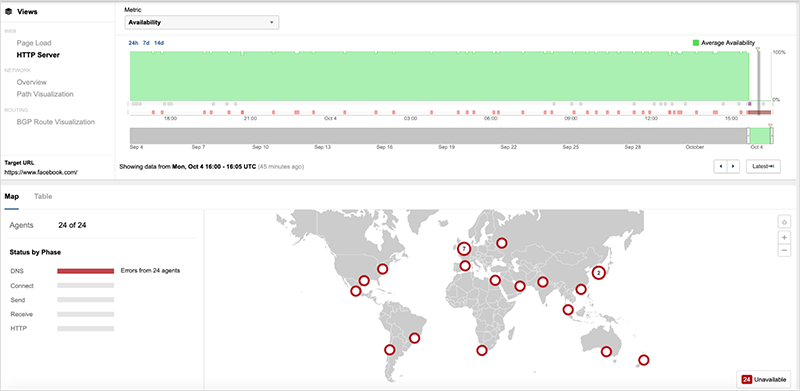
而Cloudflare在自身解析FB DNS服务出现故障后,怀疑是自己的DNS服务(1.1.1.1)故障,并在进一步的归因分析中发现Facebook在UTC 1540时产生了大量的BGP更新:
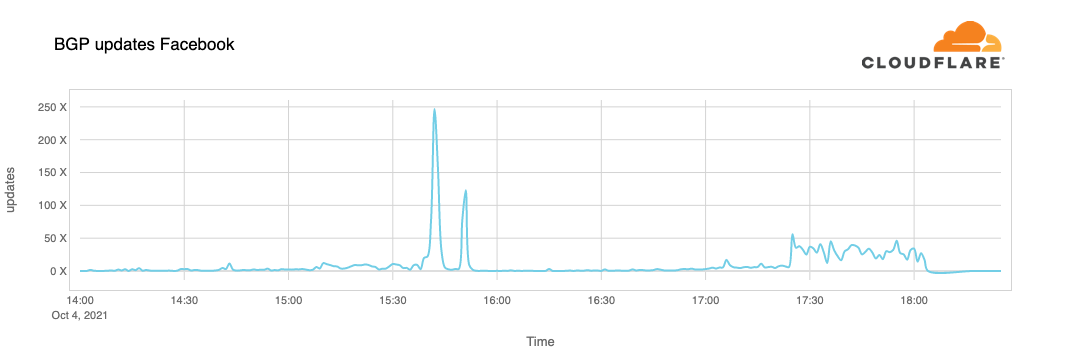
进一步分析BGP消息发现了大量的路由并撤销了关于DNS服务器的路由:

[UTC 17:40] ThousandEye也分析发现,这些关于DNS服务器的路由,在事故前是129.134.30.0/23 129.134.30.0/24 129.134.31.0/24的明细路由。但事故发生时它们可达的路由变成了129.134.0.0/17,并且数据包通过TraceRoute发现丢弃在FB的边界路由器上,大概率断定是人为配置错误,很有可能是流量调度时搞错了。
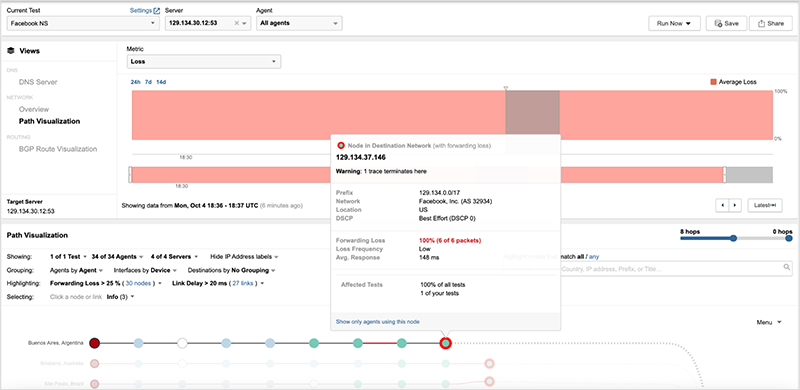
而另两个DNS服务器的路由已经被撤销,导致路由在运营商边界就不可达了
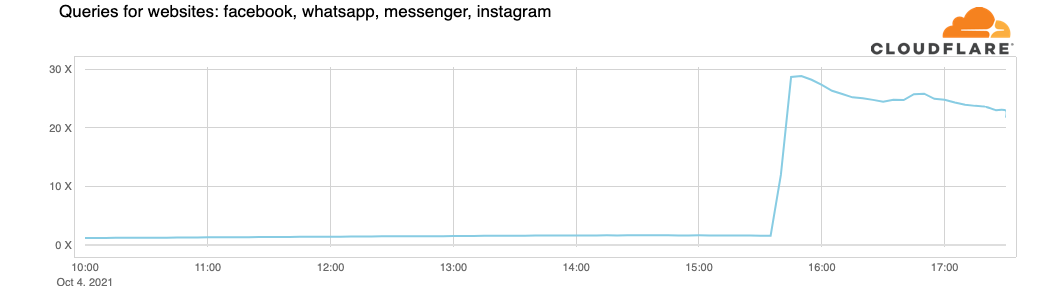
Cloudflare在后续的时间中发现,关于FB的DNS请求放大了30倍:
[UTC 21:00] CloudFlare发现FaceBook开始通过BGP通告了一些路由,直到21:17通告大量路由后,流量基本恢复.

任何一起大事故都是一系列偶然因素的叠加,从BGP路由的变化来看,很有可能是在做流量工程的时候,将路由发布错了,极大概率又和BGP FlowSpec有关,但是一个值得反思的问题是过去几个小时静悄悄的没有任何路由器的更新发出,有传言称是DNS挂了导致门禁系统挂了,从而无法进入机房恢复数据。
关于故障的反思.1 BGP
关于BGP带来的重大事故已经不止一次发生了,BGP作为整个互联网的基石,其协议用了30年了,BGP协议源于1989年1月第12次IETF会议, 由Len Bosack, Kirk Lougheed 和Yakov Rekhter提出实现一种所谓的边界网关协议(Board Gateway Protocol", 其后在三张餐巾纸上完成了BGP设计的草稿. 然后在会议结束后的不到一个月的时间, 他们提出了两个BGP的实现方案, 并在1989年6月发布了RFC1105.
协议设计之初的想法比较简单, 第一个想法在路由信息中包含相关的路径属性, 并且使用它来提供无环路的路由. 第二个想法是采用增量更新来尽量减少路由信息在两个路由器之间的交互. 第三个想法则是通过TCP来保证可靠传输. 最后一个想法则是使用TLV的方式来定义数据结构, 这样使得协议拥有了很好的扩展性.
但是30年后,其主要的问题是其通信和计算机制已经不能满足大量路由(接近1M前缀)的需求了。TCP带来的Head Of line Blocking导致了BGP通信过程中收敛缓慢。4Byte-ASN和IPv4地址交易带了路由前缀大量更新。数据中心内针对BGP-EVPN的扩展和使用BGP FlowSpec使得协议栈越来越复杂。互联网上各种魔改的开源BGP(FRR-OpenBGP/GoBGP)使得协议互通时出现Bug的几率急剧上升。当然最严重的问题是:BGP状态机和TCP的耦合:
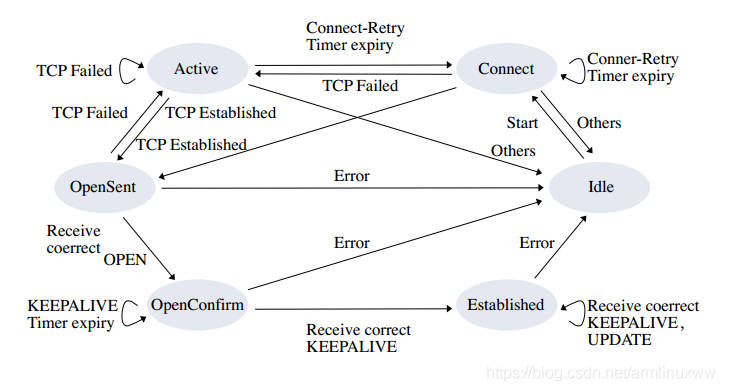
其实早在10多年前我就看到了这个问题,简单的修复方式是使用MultiThread构建多个BGP Peering的会话来发送不同的Address-Family信息,另一种是针对路径上的一些问题,使用MultiHoming和MultiStreaming的方式,也就是使用BGP Over SCTP的处理方式,并且在10多年前就写了相应的RFC-Draft
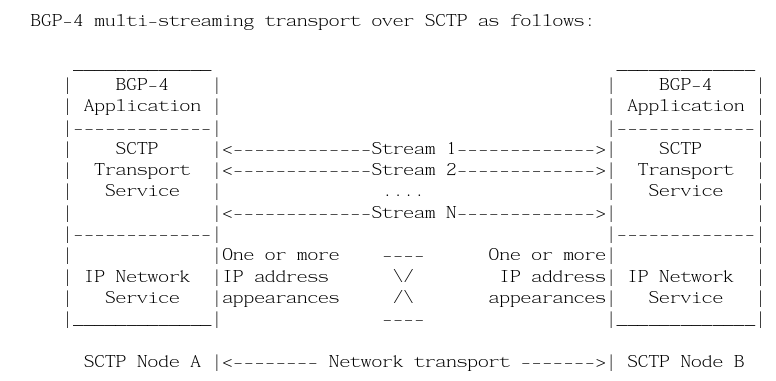
但是最终因为当时BGP并未承载如此大的流量以及SCTP协议栈本身的失败,所以搁置了.
BGP另一个问题是其低效的一致性收敛算法。BGP协议设计时还是刚到486的年代,自然有一些自身的限制和容量的取舍,eBGP防环可以通过AS_PATH,而iBGP不同,因为出于防环的考虑,iBGP收到更新后不能将其传给其它iBGP对等体,因此必须要将AS内部的路由器进行iBGP Fullmesh连接。事实上, 对于一个大型的运营商其内部可能有数以百计的BGP路由器并需要全互联形成iBGP对等体.
这样的部署方式对于运营商来说是不切实际并不被接受的. 因此Tony Bates和Ravi Chandra在1996年6月提
出了RFC1966: Route Reflector 作为一种避免iBGP Fullmesh的备选方案。而提出BGP-RR的Ravi Chandra就是支持我搞ML在网计算的大佬:

现在说大爷的BGP-RR有问题,好像有点尴尬。但是事实如此,毕竟国内好多运营商还专门拿我们做的某款路由器来做整个骨干网的RR,所以里面大大小小的问题我都清楚,调TCP-Stack,优化QoS这些都干过...
结论: 其实不光我说的,以前阿里的依群总也讲过BGP这样的协议发展了20、30年了也急需做一些变革了。而这些变革就在分布式一致性上,也就是我为什么建议在域内使用ETCD代替BGP路由并构建Ruta控制平面[3]的根本原因。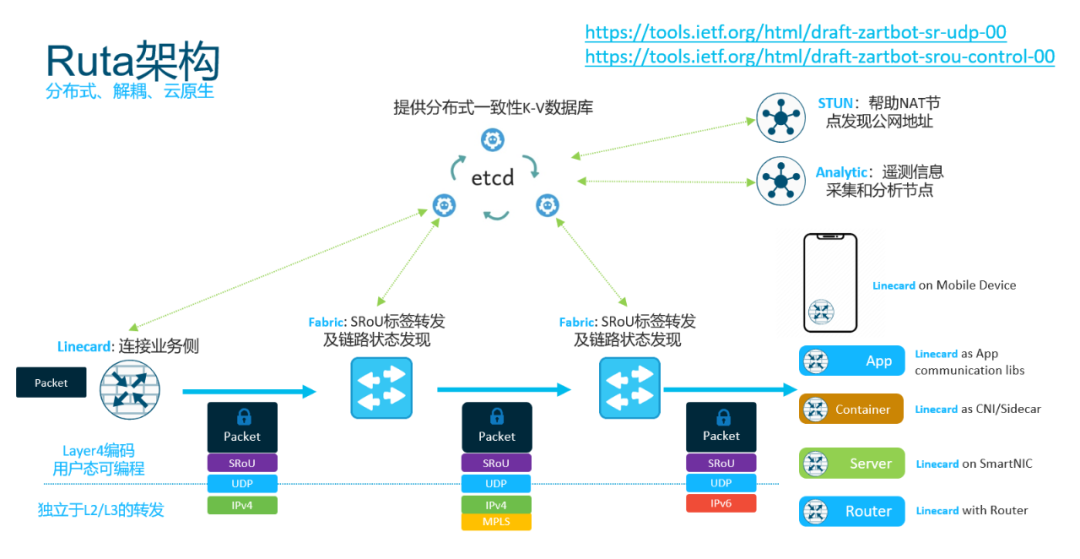
在域内将iBGP的一致性转换为分布式K-V数据库同步的处理方式.
另一方面你们可以看到NSDI'21上Google发布的Orion[4] Google便是使用其分布式数据库来保存路径信息和域内的一致性。而Ruta同样如此,采用ETCD来实现。
Google便是使用其分布式数据库来保存路径信息和域内的一致性。而Ruta同样如此,采用ETCD来实现。
具体关于控制面协议设计,去看今年早些时候写的一文吧
关于故障的反思.2 互联
当然BGP的失效有可能是中间某个运营商的错误配置导致的,虽然这次FB的故障是FB自身,但是下次有哪个运营商发布错了劫持了Facebook DNS地址呢?
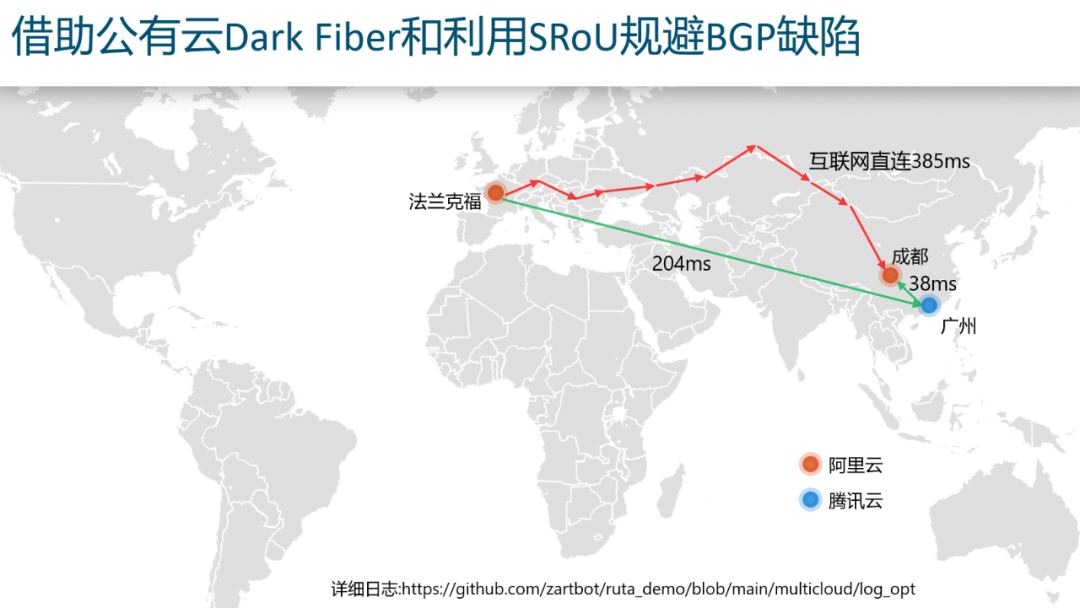
然后由于公有云和很多传统运营商都有Peering,可以让本地网络可以尽快的接到云上,这样就规避了传统的Internet路由使用BGP跨越多个运营商的缺陷,在不改变Internet架构的同时,构建了一个Overlay将部分云节点构成了Transit-AS
关于故障的反思.3 DNS
DNS其实某种意义上来看也是一种基于域名的路由协议,这也是我前几个月要自己开发一个开源项目ZaDNS的原因,传统的主机只能选择一主一备两个DNS服务器,然后通常我们又因为很多场景需要基于不同的Domain查询不同的DNS服务器,因此有了基于DNS的Domain Based Routing的需求。另一方面针对CDN失效避免和CDN优化需要进行可达性探测,还有针对网络安全需要做ZTNA或者基于ML算法的DNS域名或者Bad Reputation Record的过滤,这些都一起实现好了开源出来了:
项目地址:
github.com/zartbot/zadns
关于故障的反思.4 监控
针对BGP的监控比较容易,有现成的BGP Monitor Protocol, 另一个比较有用的就是快速的TraceRoute,ThousandEye算是比较成功的一家了。当然TraceRoute和探针测量本来就很简单:
TraceRoute我自己开源了一个并行的快速探测软件:
github.com/zartbot/ztrace
而针对Internet的测量和统计,也有相应的最佳实践:
关于故障的反思.5 激励
基础架构团队主要是为整个业务提供算力、网络等各种资源,基础设施建设本来就是重资产支出的部门,简单的来说一个纯花钱的部门如何进行业绩评估和激励。从运营的角度不出事故永远看不到这群人的重要性,而6小时的故障损失也一定程度上衡量了这种部门的关键性。
其实我们从另一个角度来看, 银行揽储的部门是不是有额外的奖金?但是这些部门也是纯花钱的部门,毕竟揽储来的钱不得付利息啊?那么为啥都是花钱一个有激励,一个没有呢?关键就是针对计算弹性的资源提供方如何进行转移定价的问题。
内部资金转移定价(FTP)是指,商业银行内部资金中心与业务经营单位按照一定规则全额有偿转移资金,达到核算业务资金成本或收益等目的的一种内部经营管理模式。业务经营单位每笔负债业务所筹集的资金,均以该业务的FTP价格全额转移给资金中心;每笔资产业务所需要的资金,均以该业务的FTP价格全额向资金管理部门购买。对于资产业务,FTP价格代表其资金成本,需要支付FTP利息;对于负债业务,FTP代表其资金收益,可以从中获取FTP利息收入。
FTP能够科学评价绩效、优化配置资源、合理引导定价、集中管理市场风险等,具体而言:一是以合理的资金成本或资金收益为基础,逐步构建银行对产品、对客户、对个人的科学评价体系;二是以资金成本的准确计量为基础,逐步建立和完善银行资源配置机制、产品定价机制以及经风险调整后的绩效评估机制;三是通过科学的产品FTP定价,剥离经营单位的市场风险,建立由专业化团队集中管理市场风险的经营管理模式;四是通过FTP推广,逐步推进资金管理体制改革,以及扁平化、事业部方式的全行条线为主的组织架构改革。而对于数字化资产我们同样可以实施相应的FTP,为解决基础架构部门和业务及应用部门相互利益分配会有很大的好处,从而进一步从财务核算上激励双方进行技术创新

基于FTP的机制还有一个好处是在基础架构建设过程中,通过完整的端到端成本核算,能够有利于激发团队进行关键性的节点的创新和风险补偿机制。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈