
千行百业智能化落地,MMDeploy 助你一“部”到位

OpenMMLab 开源以来,每天都会收到社区用户的灵魂拷问:
”OpenMMLab 的算法如何部署?“
今天,OpenMMLab 本年度开源计划的压轴项目——
模型部署工具箱 MMDeploy
IS ALL YOU NEED!
(点击观看 一分钟读懂 MMDeploy )
从今天起,OpenMMLab 不仅能够提供高质量、前沿的人工智能模型,也将强势打通从算法模型到应用程序这 "最后一公里"!
项目链接
https://github.com/open-mmlab/mmdeploy
(赶紧使用起来吧!别忘了点小星星⭐哦!)

玩转多元智能化场景
模型部署是指把机器学习产生的训练模型部署到各类云、边、端设备上去,使之高效运行,从而将算法模型实际地应用到现实生活中的各类任务中去,实现 AI+ 的智能化转型。
OpenMMLab 最新部署工具 MMDeploy 具有以下特点——
全面对接 OpenMMLab 各算法体系,提供算法快速落地的通道;
建立了统一管理、高效运行、多后端支持的模型转换框架;
实现了高度可扩展的组件式 SDK 开发框架;
拥有灵活、开放、多样化的输出,满足不同用户的需求。
目前,我们已经支持 5 个算法库和 5 种后端推理引擎,囊括多种应用场景——
MMDeploy 所支持算法库:
检测(MMDetection)
分割(MMSegmentation)
分类(MMClassification)
编辑(MMEditing)
文字识别(MMOCR)
MMDeploy 所支持后端推理引擎:
ONNX Runtime
TensorRT
OpenPPL
ncnn
OpenVINO
后续我们将不断迭代,支持更多的算法库和后端引擎,也欢迎大家留言告诉我们你所需要的算法库名,开发者们一定快马加鞭满足社区同学需求!
同时更欢迎各推理引擎的开发者一起合作,将 OpenMMLab 繁荣的算法生态和硬件推理对接起来~
MMDeploy 整体架构
MMDeploy 以各算法库的模型为输入,把模型转换成推理后端要求的模型格式,运行在多样的设备中。
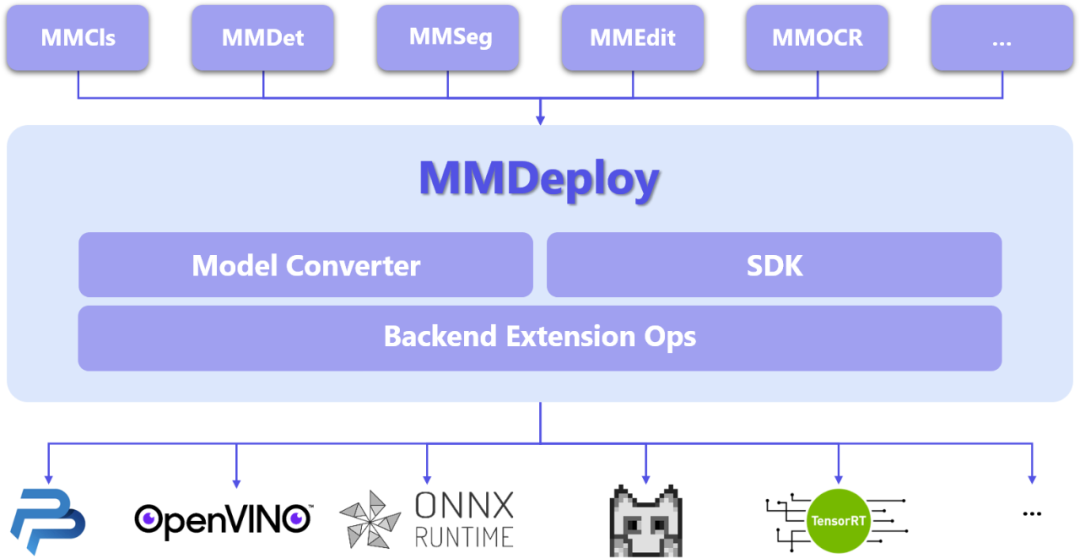
从具体模块组成看,MMDeploy 包含 2 个核心要素:模型转换器 ( Model Converter ) 和应用开发工具包(SDK)。
模型转换器
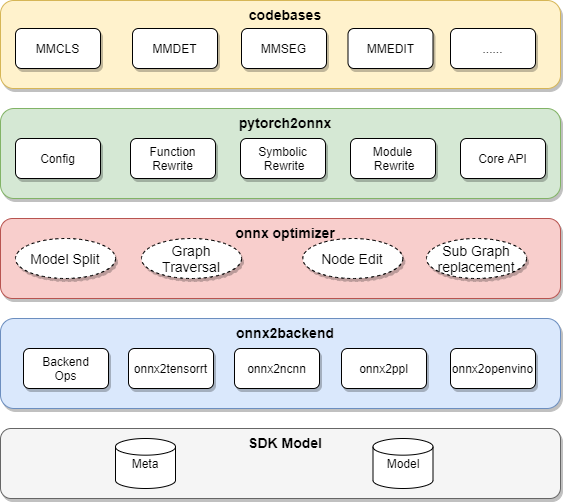
模型转换器 ( Model Converter ) 负责把各算法库的 PyTorch 模型转换成推理后端的模型,并进一步封装为 SDK 模型。
模型转换器的具体步骤为:
把 PyTorch 转换成 ONNX 模型
对 ONNX 模型进行优化
把 ONNX 模型转换成后端推理引擎支持的模型格式
(可选)把模型转换中的 meta 信息和后端模型打包成 SDK 模型
在传统部署流水线中,兼容性是最难以解决的瓶颈。针对这些问题,MMDeploy 在模型转换器中添加了模块重写、模型分块和自定义算子这三大功能。
模块重写
有效代码替换
针对部分 Python 代码无法直接转换成 ONNX 的问题,MMDeploy 使用重写机制实现了函数、模块、符号表等三种粒度的代码替换,有效地适配 ONNX。
模型分块
精准切除冗余
针对部分模型的逻辑过于复杂,在后端里无法支持的问题,MMDeploy 使用了模型分块机制,能像手术刀一样精准切除掉模型中难以转换的部分,把原模型分成多个子模型,分别转换。这些被去掉的逻辑会在 SDK 中实现。
自定义算子
扩展引擎能力
OpenMMLab 实现了一些新算子,这些算子在 ONNX 或者后端中没有支持。针对这个问题,MMDeploy 把自定义算子在多个后端上进行了实现,扩充了推理引擎的表达能力。
应用开发工具包 SDK
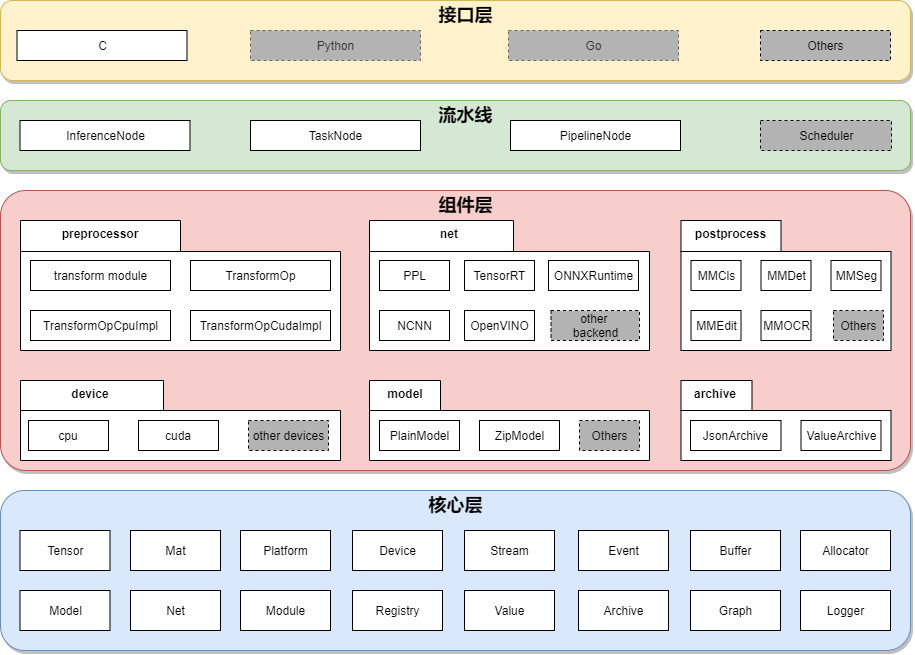
接口层
SDK 为每种视觉任务均提供一组 C API。目前开放了分类、检测、分割、超分、文字检测、文字识别等几类任务的接口。
SDK 充分考虑了接口的易用性和友好性。每组接口均只由 ‘创建句柄’、‘应用句柄’、‘销毁数据’ 和 ‘销毁句柄’ 等函数组成。用法简单、便于集成。
流水线层
SDK 把模型推理统一抽象为计算流水线,包括前处理、网络推理和后处理。对流水线的描述在 SDK Model 的 meta 信息中。使用 Model Converter 转换模型时,加入 --dump-info 命令,即可自动生成。
不仅是单模型,SDK 同样可把流水线拓展到多模型推理场景。比如在检测任务后,接入识别任务。
组件层
组件层为流水线中的节点提供具体的功能。SDK 定义了3类组件:
设备组件(Device)
对硬件设备以及 runtime 的抽象
模型组件(Model)
支持 SDK Model 不同的文件格式
任务组件(Task)
模型推理过程中,流水线的最小执行单元。
其中任务组件分为:
- 预处理(preprocess):与 OpenMMLab Transform 算子对齐,比如 Resize、Crop、Pad、Normalize等等。每种算子均提供了 cpu、cuda 两种实现方式。
- 网络推理引擎(net):对推理引擎的封装。目前,SDK 可以接入5种推理引擎:PPL.NN, TensorRT, ONNX Runtime, NCNN 和 OpenVINO。
- 后处理(postprocess):对应与 OpenMMLab 各算法库的后处理功能。
核心层
核心层是 SDK 的基石,定义了 SDK 最基础、最核心的数据结构。
作为 OpenMMLab 大家庭的部署侧全能工具包,MMDeploy 协助开发者们将优质的模型部署到设备上高效运行,架起了模型从研发到落地的桥梁,让算法在实际生产中发挥出更大价值。
还等什么?!
千行百业智能化落地
MMDeploy 助你一“部”到位!
欢迎社区小伙伴使用,期待 Star、Issue、PR!
欢迎使用
项目地址
https://github.com/open-mmlab/mmdeploy
快速入门文档链接
英文:
https://github.com/open-mmlab/mmdeploy/blob/master/docs/en/get_started.md
中文:
https://github.com/open-mmlab/mmdeploy/blob/master/docs/zh_cn/get_started.md