
因Pandas版本较低,这个API实现不了咋办?
导读
前几天发表了一篇推文,分享了Pandas中非常好用的一个API——explode,然而今天又发生了戏剧性的一幕:因Pandas版本过低系统提示'Series' object has no attribute 'explode'!好吧,好用的东西永远都是娇贵的,这个道理没想到在代码中也适用。所以,今天就以此为题展开拓展分析,再输出一点Pandas干货……

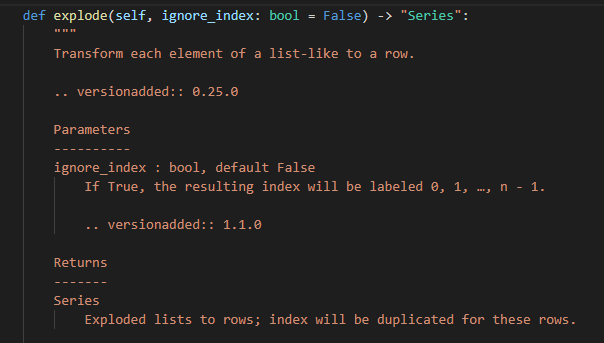
explode函数在0.25版本加入,其中ignore_index则是在1.1版本增加
既然explode无法直接使用,那么就必须尝试用其他方法实现相同的效果。这里首先给出执行explode后的目标效果:

观察explode执行后的目标效果,实际上颇有SQL中经典问题——列转行的味道。也就是说,B列实际上可看做是多列的聚合效果,然后在多列的基础上执行列转行即可。基于这一思路,可将问题拆解为两个子问题:
含有列表元素的单列分为多列
多列转成多行

至此,实际上是完成了单列向多列的转换,其中由于每列包含元素个数不同,展开后的长度也不尽一致,pandas会保留最长的长度,并将其余填充为空值(正因为空值的存在,所以原本的整数类型自动变更为小数类型)。值得一提,这里的空值在后续处理中将非常有用。
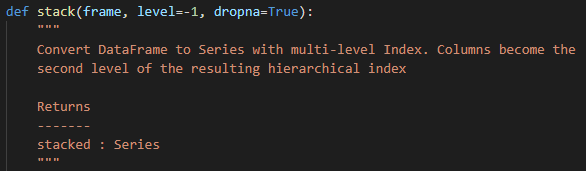
ok,那么可以预见的是在刚才获得的多列DataFrame基础上执行stack,将实现列转行堆叠的效果并得到一个Series。具体来说,结果如下:
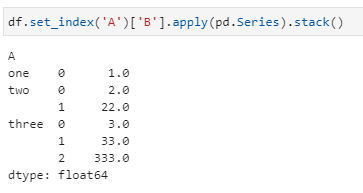

虽然以上实现不如直接一句explode来得优雅,但也着实实现了相同的效果,而且实际上更有成就感,不是吗!
相关阅读:
评论