
高可用架构设计之无状态服务
笑谈架构设计
事故的发生是量的积累的结果,任何事情都没有表面看起来那么简单,在软件运行的过程中,随着用户量的增加,不考虑高可用,迟早有一天会发生故障,不得事先考虑高可用设计,而高可用是一门庞大的学问

你想知道我在设计一个高可用系统会考虑哪些内容吗?在架构设计的过程中
考虑方案选型会带来哪些坑,最差的情况下需要考虑故障发生的紧急解决方案 需要监控系统,在故障发生时、发生时有所感知 需要自动化恢复方案,自动化提前处理预警方案 在代码层面需要考虑处理速度、代码性能、报错处理 还要考虑把故障降低到最小:服务降级、限流、熔断 等等
这篇文章主要介绍无状态服务在架构层面,如何保证可高用
★无状态服务:在任何时候服务都不存储数据(除缓存),可以任意销毁创建,用户数据不会发生丢失,可以任意切换到任何一个副本,不影响用户
”
无状态服务的高可用旨在任何情况下数据都不丢失,服务都不发生故障,在某些服务发生故障时保证影响最小,并可以快速恢复
可以从这几个方面考虑
冗余部署:至少多部署一个节点,避免单点问题 垂直扩展:增加单机性能 水平扩展:流量激增可快速扩容
冗余部署
在单点架构中,随着数据数据量增加,单点负载压力过大,容易产生服务崩溃不可用的情形,对于无状态服务,可以考虑部署多个节点的服务来分散压力
对于如何调度来临的请求,可以参考负载均衡的方式,尽可能的保证充分的利用服务器的资源
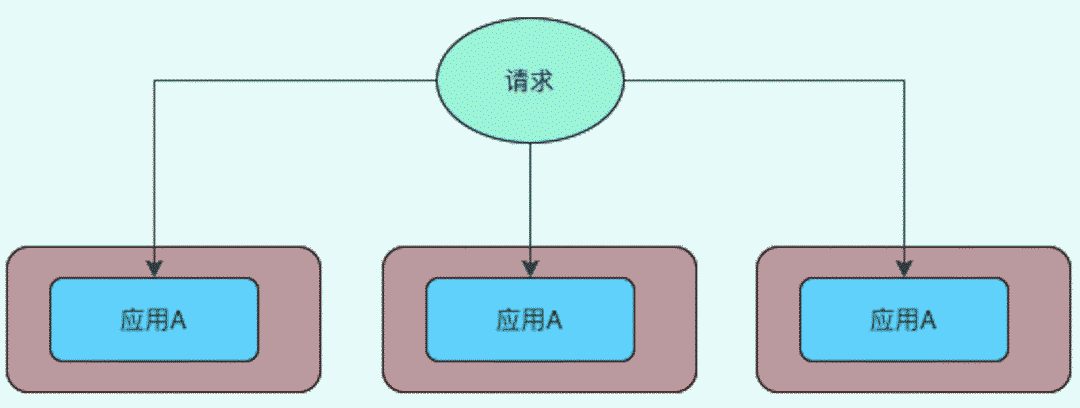
无状态服务:不需要存储数据的服务,即使节点挂掉再重启,不会发生数据丢失 负载均衡:把大量请求分散到不同节点上的一种算法
无状态服务的负载均衡
可以使用负载均衡中提供的四种算法
随机均衡算法:已知后端服务器列表,随机请求,数据量越大越趋近于均衡 轮询算法:轮流请求后端服务器
前两种算法存在的问题是后端服务器在负载压力不同或服务器配置不同时,不能保证压力小的多分配,压力大的小分配,于是引入
加权轮循算法:按照后端服务器的抗压能力,负载情况分配更高的权重,更容易命中,减少宕机风险,按权重顺序的分配到后端服务器上 加权随机法:和加权轮训算法一样,不同的是分配是按权重随机的,比如有多台权重一致的情况,随机访问,那就和随机算法有同样的问题,数据量大时才趋近于均衡,数据量小时有可能重复访问同一台权重一致的机器 [加权]最小连接数算法:这是最智能的一种算法,根据服务器当前的连接数来选取,更容易命中处理速度快的服务器
上面的算法使用于无状态应用,假如要保存通信状态,需要使用
源地址哈希算法:对源地址做hash,可以保证相同的请求最终都是落在同一台机器上,不需要重复建立连接
负载均衡算法如何选择?
首先抛弃随机算法,最简单的配置可以使用基本的轮训算法,它适用于服务器配置一致,比如使用虚拟机,可以动态调整服务器配置的场景,同时要保证专用虚拟机,上面不会部署其他应用的情况
但是服务器上往往会安装多个应用,那就要考虑在加权轮训和最小连接数中做选择
 加权轮训适用于短连接场景,比如HTTP服务,在k8s中因为每个pod都是独立的,默认service策略是非加权轮训
加权轮训适用于短连接场景,比如HTTP服务,在k8s中因为每个pod都是独立的,默认service策略是非加权轮训
最小连接数适用于长连接,比如FTP等
如果系统架构中考虑到无cookie功能的场景,可以用源地址hash算法,把源IP一直映射到同一台rs上,在k8s中叫会话保持模式,每次转发到同一个pod上
建议:
如果上了容器直接交给k8s来做调度,使用cookie做会话保持,算法使用默认轮训,具体调度未来k8s文章里会做详细介绍 使用长连接的应用(FTP、socket,或者用于下载连接),选择加权最小连接数 短连接应用(静态网站、微服务组件等),选择加权轮训,用cookie来做会话保持,减少session的设计,不仅会提高代码复杂度,也会增加服务端负载情况,不利于分布式应用
高并发应用的识别
主要指标QPS每秒处理响应数,比如每天有10w的pv
公式 (100000 * 80%) / (86400*20%) = 4.62 QPS(峰值QPS)
公式原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
比如我做的系统托管了最高5w台机器,每台机器每次分钟有一次PV,时间比较均匀那就是
((60*24)*50000)/(86400)=833 QPS
一般上百的量级就可以叫高并发了,网上查到的资料微博每天1亿多pv的系统一般也就1500QPS,5000QPS峰值。
除了QPS还有服务响应时间、并发用户数指标可以参考
在服务器负载高的时候,表现在处理速度变慢、网络断连、服务处理失败、异常报错等问题,具体问题要具体分析,不可一概而论
可以通过监控,来获得服务器性能状态,动态调整、重试,达到服务可用性的保证,减少维护成本,通常单纯服务器压力大的时候可以考虑垂直扩展
垂直扩展
垂直扩展是增加服务器单机的处理能力,主要有三种方式
服务器升配:集中在CPU、内存、swap、磁盘容量或者网卡等 硬件性能:磁盘SSD、调整系统参数等 架构调整:软件层面使用异步、缓存、无锁结构等
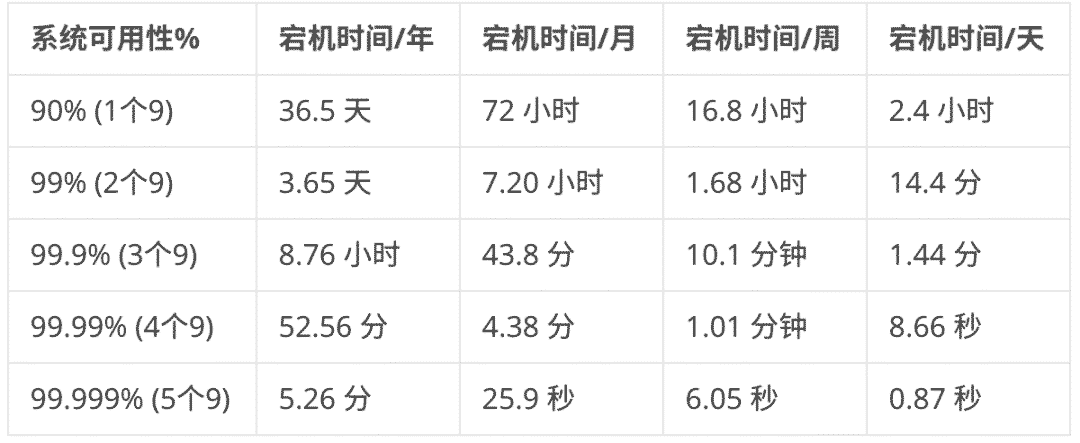
增强单机性能的方式是最快最容易的方式,但是单机性能之中是存在极限,同时单机部署时如果产生故障,对应用来说打击是致命的,我们应该保证应用时刻处于可用的状态,也就是俗话说的保证5个9的可靠性
水平自动伸缩
知道了单机的局限以后,考虑使用水平伸缩的方式
水平伸缩就是压力增加的时候,增加新的节点来分担压力,但仅仅多点部署还是不够的,对于持续增长的业务,始终有一天会突破服务的压力上限,如果遇到流量激增的场景,人工应对肯定会措手不及,所以需要一种自动伸缩的手段
对于私有云部署来说可以手动实现调度器,检测系统状态,连通iaas层实现伸缩 也可以直接使用云服务器提供的弹性伸缩服务 对于容器而言,可以在iaas层弹性伸缩的情况下或者有充足node节点的情况下,配置自动伸缩和调度的策略,预防单机故障
★名词解释:iaas 基础设施即服务,代表对服务器、存储、网络等硬件资源管理的服务
”
注意:弹性伸缩针对的业务场景是无状态服务
另外无状态机器不足以承载请求流量,需要进行水平扩展的阈值一般QPS是千级,同时在这里对数据库也会有压力,所以建议水平伸缩的服务器不要部署有状态服务
对于有状态服务压力分散在后续的文章会有所介绍
CDN和OSS
对于一个网站来说,用户交互页面,是一个特殊的服务,包含很多静态资源,比如图片、视频、页面(html/css/js),这些资源在用户请求的时候需要现场下载,下载速度决定了加载速度,在web服务故障的时候,同样应该对用户做出相应
在这一层面可以考虑使用CDN内容分发网络的方式,详见[xxx],把前端静态数据缓存到边缘服务器上
★名词解释:边缘服务器(边缘节点),可以理解为和用户交互的服务器,也可理解为靠近用户的服务器节点,因为靠近用户,减少了网络传输使用的时间
”
使用了CDN的web服务,可以把https证书绑定到cdn上,在回源策略可以配置回源超时、回源跟随301/302状态码等配置,还可以智能压缩网页、自定义错误页面,非常方便
oss是一种特殊的存储方案,以对象的形式进行存储,理论上可以存储无限的文件
考虑使用oss对象存储并结合cdn,把媒体资源存储在对象存储上面,也可以把冷数据压缩归档到oss上
常见的视频网站大多会用到oss,微博n年以前的数据应该就是归档到对象存储中了
总结
本文介绍的无状态服务常见的高可用架构设计,他们是
冗余部署
负载均衡的6种算法与算法选择
垂直扩展的好处与弊端
水平扩展与水平自动伸缩
哪些服务可以使用CDN和OSS
要注意无状态应用不应该存储session,也不存储数据
本文对负载均衡的6种算法做了介绍,但是没有介绍每个算法具体的实现方式,这个留给你下来研究,这些方案在实际使用的时候会有一定难度,服务不可用的故障原因任何一门都是博大精深的学问,程序员不仅是写代码

这里也仅仅写了无状态服务的部分高可用方案,不管是什么服务还是从代码层级的设计,你还知道哪些呢?
有时候比较苛刻的情况下,没有更多的服务器资源,如何在有限服务器的情况下提高更多的代码性能呢?
![]()