
Pandas中实现词频统计次数,该怎么写?
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python铂金交流群有个叫【dcpeng】的粉丝问了一个Pandas中实现词频统计次数的问题,这里拿出来给大家分享下,一起学习下。
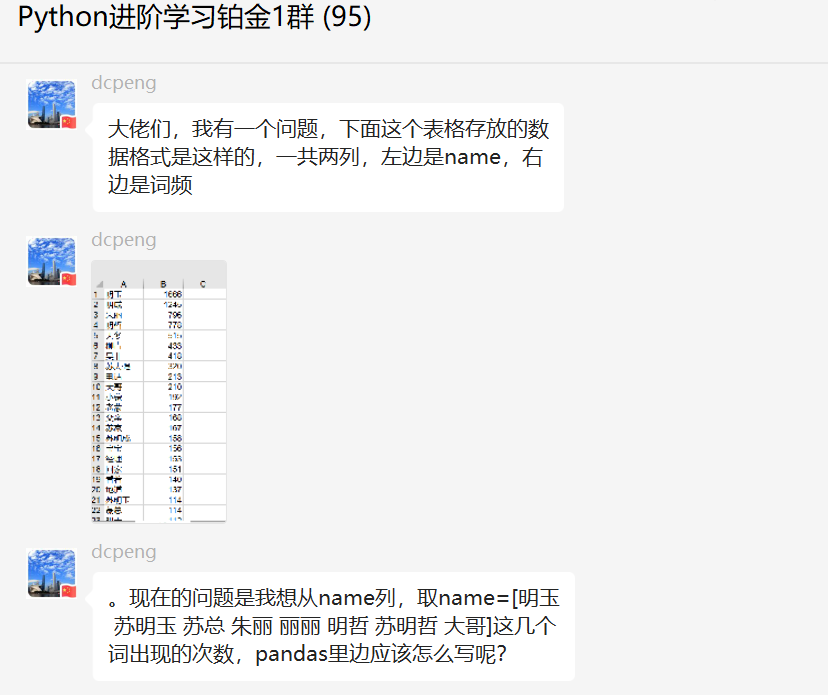
下图是原始数据:
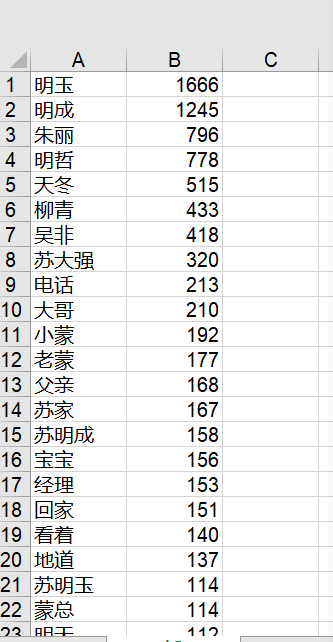
他自己写的部分代码,如下:
df = pd.read_excel('./data.xls', names=['name', 'count'])
names = ['明玉', '苏明玉', '苏总', '朱丽', '丽丽', '明哲', '苏明哲', '大哥', '明成', '苏明成', '大哥',
'苏大强', '老爹', '爸', '吴非', '苏家', '宝宝', '老蒙', '蒙总', '小蒙', '天冬', '石天冬',
'石大哥', '柳青', '蔡根花', '钟点工', '温玮光', ' 温总', '苏母']
二、解决过程
这里【月神】给出了一个代码,如下图所示:
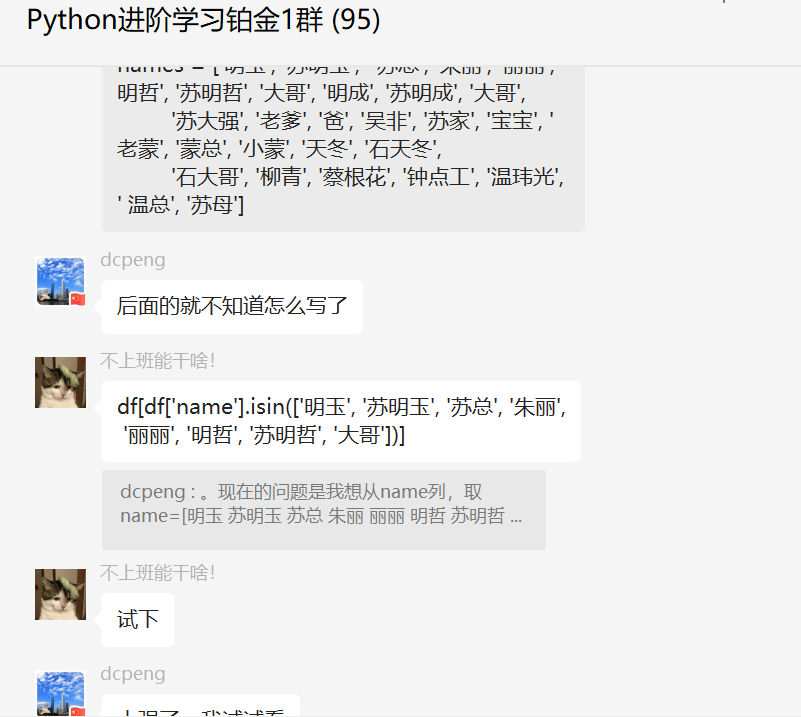
然后他自己修改下,就搞定了。
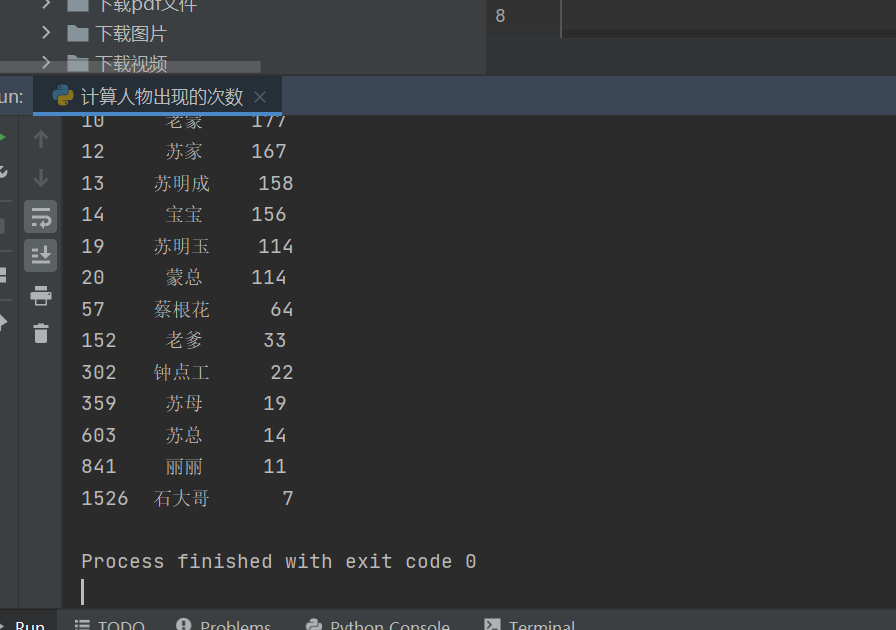 代码如下所示:
代码如下所示:
df = pd.read_excel('./data.xls')
names = ['明玉', '苏明玉', '苏总', '朱丽', '丽丽', '明哲', '苏明哲', '大哥', '明成', '苏明成', '大哥',
'苏大强', '老爹', '爸', '吴非', '苏家', '宝宝', '老蒙', '蒙总', '小蒙', '天冬', '石天冬',
'石大哥', '柳青', '蔡根花', '钟点工', '温玮光', ' 温总', '苏母']
print(df[df['name'].isin(names)])
不过事情还没有完成,后来又提新的需求了。
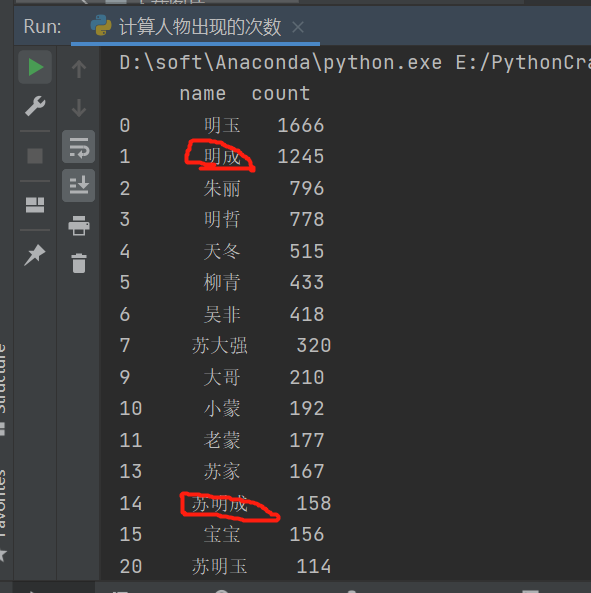
比如这种,他都是一个人,怎么把他处理到一块?

这里他自己想到了一个可行的思路。把人名整理到每一行,以空格分开,每一行代表一个人,之后逐行读取,然后传值到变量里边,df[df['name'].isin(names)],挨个输出就可以了,代码如下:
with open('人名.txt', 'r', encoding='utf-8') as f:
name_count = 0
for names in f:
name = names.strip().split()
count = df[df['name'].isin(name)]
# print(df[df['name'].isin(list(names))])
print(count['count'].sum())
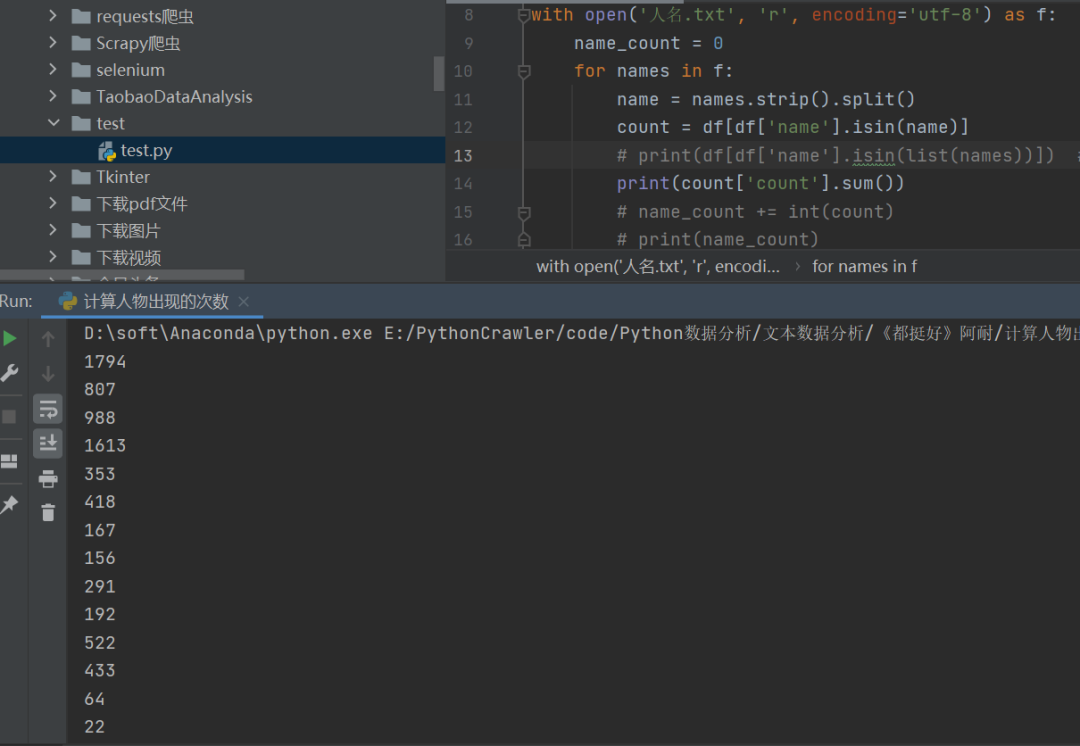
之后就可以进一步做词云图啥的了,巴适得很!

三、总结
大家好,我是皮皮。这篇文章主要分享了Pandas中实现词频统计次数的问题,文中针对该问题给出了具体的解析和代码演示,帮助粉丝顺利解决了问题。
最后感谢粉丝【dcpeng】提问,感谢【月神】给出的具体解析和代码演示,感谢【杨羊】、【沈复】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论