
干货 | Elasticsearch 词频统计的四种方案
1、词频相关实战问题
最近词频统计问题被问到的非常多,词频统计问题清单如下:
Q1:Elasticsearch可以根据检索词在doc中的词频进行检索排序嘛? Q2:求教 ES 可以查询某个索引中某个text类型字段的词频数量最大值和词所在文档数最大值么?例:索引中有两个文档
doc1:{"text":""} 分词结果有两个北京,一个南京
doc2:{"text":""} 分词结果有一个北京想要一下结果:北京:词频3,文档量2
南京:词频1,文档量1Q3:对某些文章的词频统计除了用fielddata之外还有没有效率比较高的解决办法呢?目前统计有时候会遇到十万级的文章数直接在通过聚合效率上不是特别理想。
如上三个问题都可以归结为:Elasticsearch 文档词频统计问题。该问题在检索、统计领域应用的非常多。
那么 Elasticsearch 如何实现词频统计呢?有必要梳理一下。
2、词频统计探讨
之前的文章《Elasticsearch词频统计实现与原理解读》,解决的是:Q3 提及的某索引中特定关键词统计的问题。
解决方案是:text 字段开启 fielddata,咱们在《长津湖影评可视化》中词云的可视化本质也是这种方案。
那么,对于给定文档的词频统计呢?
原来开启 fielddata 的方案就可以实现,举例如下:
DELETE message_index
PUT message_index
{
"mappings": {
"properties": {
"message": {
"analyzer": "ik_smart",
"type": "text",
"fielddata": "true"
}
}
}
}
POST message_index/_bulk
{"index":{"_id":1}}
{"message":"沉溺于「轻易获得高成就感」的事情:沉溺于有意无意地寻求用很小付出获得很大「huibao」的偏方,哪怕huibao是虚拟的"}
{"index":{"_id":2}}
{"message":"过度追求“短期huibao”可以先思考这样一个问题:为什么玩王者荣耀沉溺我们总是停不下来huibao"}
{"index":{"_id":3}}
{"message":"过度追求的努力无法带来超额的huibao,就因此放弃了努力。这点在聪明人身上尤其明显。以前念本科的时候身在沉溺"}
POST message_index/_search
{
"size": 0,
"query": {
"term": {
"_id": 1
}
},
"aggs": {
"messages": {
"terms": {
"size": 10,
"field": "message"
}
}
}
}
无非在聚合的时候,加上query 语句指定了特定 id 进行检索。
这种方法的缺点在于:正如 Q3 所说,聚合效率低。
看过上次直播的同学,可能会闪现一种想法,写入前打 tag 的方式能解决吗?
可以解决,但有个前提。先画个图解释一下:
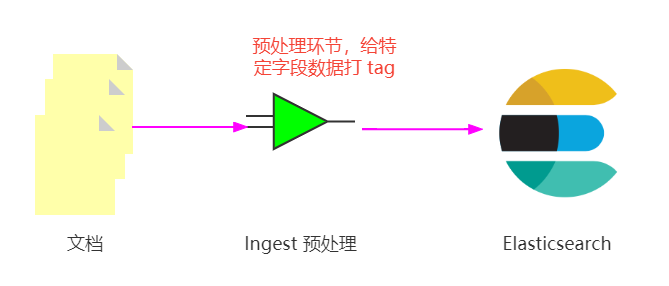
这个打 tag 的字段非全量,而是特定的指定脚本处理的部分。下一小节详细实现一把。
其实,除了开启 fielddata 和 打 tag 之外,在 Elasticsearch 中有 termvectors 接口也能实现文档词频统计。下一小节一并实现。
3、词频统计实现
3.1 text 开启 fielddata 后聚合方案
第 2 部分已有实现说明,不再赘述。
3.2 写入前打 tag,写入后聚合统计方案
还是用第 2 部分的数据,说明如下:
PUT _ingest/pipeline/add_tags_pipeline
{
"processors": [
{
"append": {
"field": "tags",
"value": []
}
},
{
"script": {
"description": "add tags",
"lang": "painless",
"source": """
if(ctx.message.contains('成就')){
ctx.tags.add('成就')
}
if(ctx.message.contains('王者荣耀')){
ctx.tags.add('王者荣耀')
}
if(ctx.message.contains('沉溺')){
ctx.tags.add('沉溺')
}
"""
}
}
]
}
POST message_index/_update_by_query?pipeline=add_tags_pipeline
{
"query": {
"match_all": {}
}
}
POST message_index/_search
{
"size":0,
"aggs": {
"terms_aggs": {
"terms": {
"field": "tags.keyword"
}
}
}
}
实现后,结果如下:
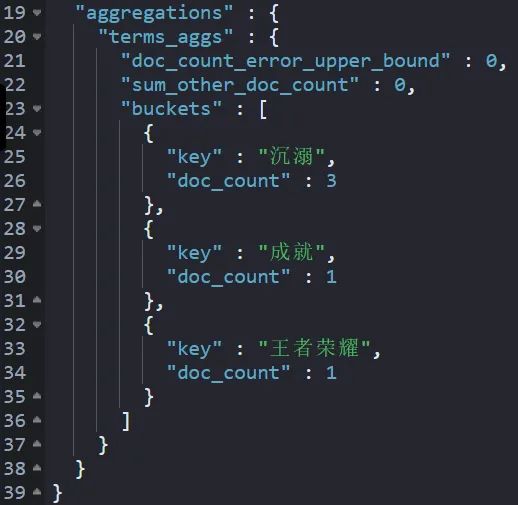
这种统计的依然是:关键词(key)和文档(doc_count)的统计关系。
什么意思呢?
"key":“沉溺”,“doc_count”:3 本质含义是:“沉溺”在三个不同的文档中出现了。
细心的读者会发现,文档 1 中“沉溺”出现了2次,这种打 tag 统计是不准确的。
3.3 term vectors 统计
PUT message_index
{
"mappings": {
"properties": {
"message": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"store": true,
"analyzer": "ik_max_word"
}
}
}
}
解释一下:
term_vector: 检索特定文档字段中分词单元的信息和统计信息。 store: 默认未开启存储,需要手动设置为true。
with_positions_offsets_payloads 是Lucene 的参数之一,释义如下:
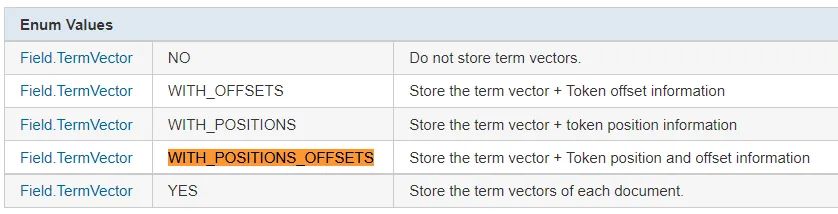
可以理解为:存储分词单元(term vector)、位置(Token position)、偏移值(offset)、有效负载(payload,猜测是ES 新增的)。
默认会统计词频信息,默认term information 为true。此外,还有 term statistics 和 field statistics 类型供设置和实现不同的统计,详细内容参考官方文档即可。
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-termvectors.html
执行:
GET message_index/_termvectors/1?fields=message
后的返回结果如下:
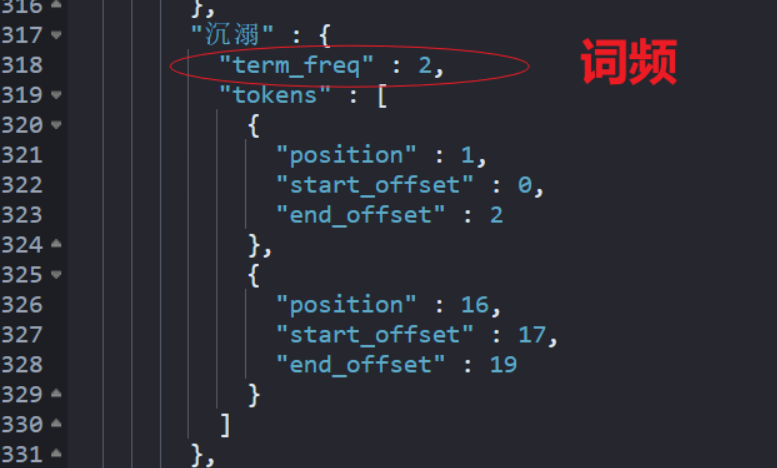
这种基于特定文档的词频统计是传统意义上我们理解的词频统计。
默认情况下,term vectors是实时的,而不是接近实时的。可以通过将 realtime 参数设置为 false 来更改。实时就意味着可能会有性能问题。
3.4 先分词,后 term vectors 统计
在我担心仅 termvectors 可能带来的性能问题的时候,我想到了如下的解决方案。
前提:写入之前除了存储 message 字段,加了一个分词结果组合字段,该字段每个词用空格做分隔。
message 字段的前置分词需要自己调用 analyzer API 实现。
有了切词后的字段,再做统计会更快。
具体实现如下:
DELETE message_ext_index
PUT message_ext_index
{
"mappings": {
"properties": {
"message_ext": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"store": true,
"analyzer": "whitespace"
}
}
}
}
POST message_ext_index/_bulk
{"index":{"_id":1}}
{"message_ext":"沉溺 于 轻易 获得 高 成就感 的 事情 沉溺 有意 无意 地 寻求 用 很小 付出 获得 很大 huibao 的 偏方 哪怕 huibao 是 虚拟 的"}
GET message_ext_index/_termvectors/1?fields=message_ext
强调一下:message_ext 使用的 whitespace 分词器。
4、小结
关于词频统计,本文给出四种方案。只有第3、4种方案结合termvectors 实现是严格意义上的词频统计,其他两种是词频-文档关系的统计。
考虑到方式3的实时分词可能的性能问题,扩展想到方案4前置分词的方式,能有效提高统计效率。本质也是空间换时间。
你的实战中如何实现的词频统计呢?欢迎留言说一下你的实现方式和思考。
参考
https://titanwolf.org/Network/Articles/Article?AID=7c417f9f-5bde-4519-9bd5-39957d184a07
https://discuss.elastic.co/t/word-count-frequency-per-field/159910
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-termvectors.html
推荐
更短时间更快习得更多干货!
已带领70位球友通过 Elastic 官方认证!
中国仅通过百余人
