
VictorialMetrics源码分析之插入指标数据
为了调试方便,这里我们将 VictorialMetrics 代码使用 Goland 打开。每个组件的入口位于 app/,比如 vmstorage 组件的入口位于 app/vmstorage/main.go:
为了对 VM 整个流畅分析,我们可以直接在 IDE 中来启动这些组件。
直接在 vmstorage 入口的 main 函数上点击 Run 'go build main.go' 即可启动该组件:
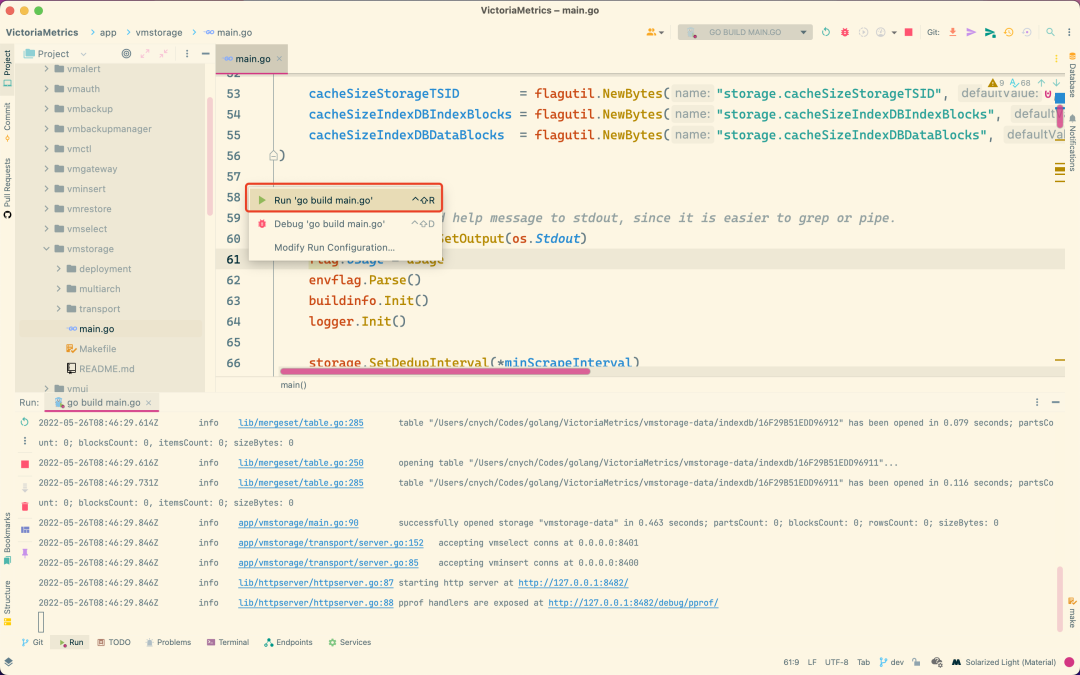
通过日志记录可以看出 vmstorage 会在 8401 端口监听 vmselect 的连接请求,在 8400 端口监听 vminsert 的连接请求,其本身的服务会通过 8482 端口进行暴露。启动后会在根目录下面创建一个名为 vmstorage-data 的数据目录,该目录就是用来保存 VM 的数据的,其中 data 目录是监控指标数据目录,indexdb 目录是索引数据目录,snapshots 是快照目录,flock.lock 为文件锁文件,用于 VM 进程锁住文件,不允许别的进程进行修改目录或文件,如下所示:
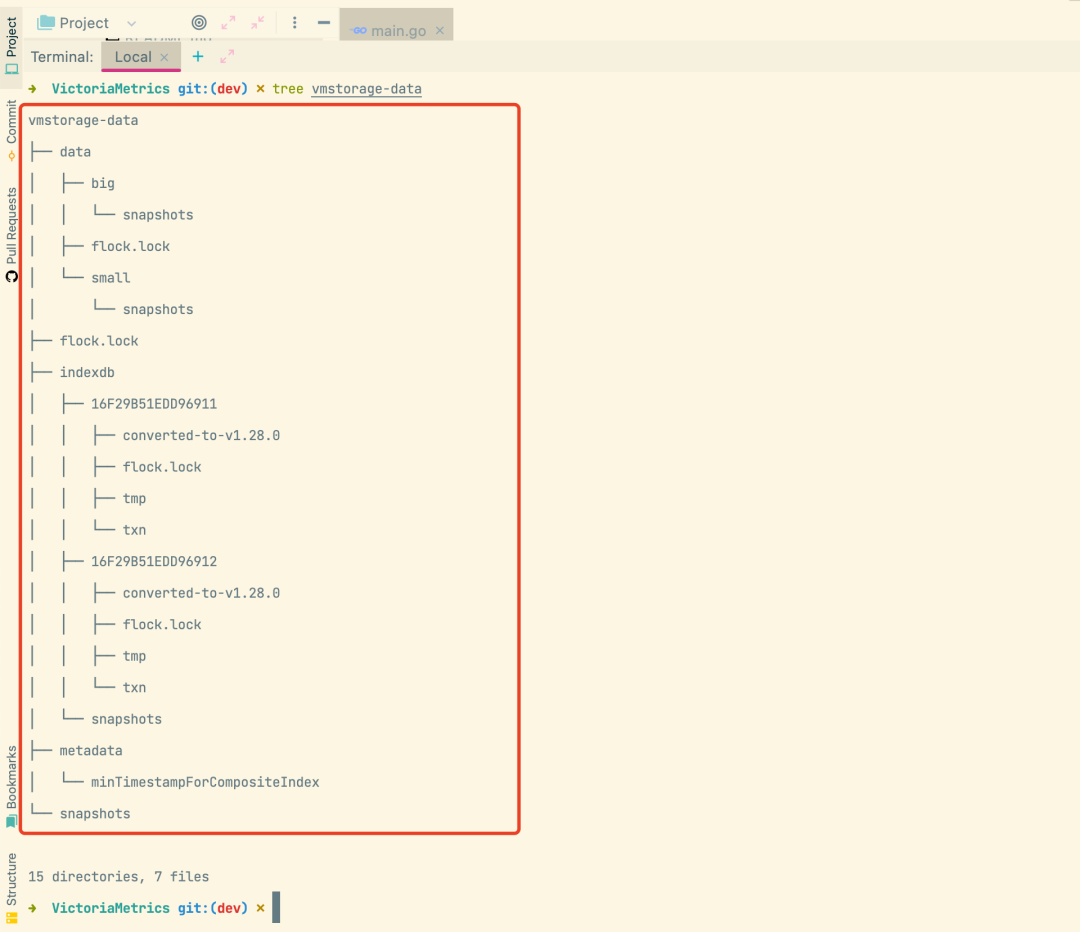
数据目录 data 下面包含两个最主要的目录big 目录和small 目录,这两个目录的结构是一样的。
small 目录:内存中的数据先持久化到目录,压缩比例高,会定期检测判断是否满足 merge 条件,合并多个小文件。 big 目录:small 过大后会合并到 big 目录,压缩比例极高。
索引目录 indexdb 下面包含两个目录 16F29B51EDD96911、16F29B51EDD96912,这两个目录分别表示当前正在使用的索引目录,和前面一次使用的索引目录,为什么需要保留前面一次使用的呢?
这是因为 VM 中会配置自动轮换的周期,比如可以配置1天、1周、1月等等,那么这个周期到了后索引数据就要轮换,就相当于会创建一个新的目录作为最新的索引数据目录,但是如果你直接将前面一个到期的索引删除,那么现在就没有任何索引了,此时如果有大量的插入或者查询操作的话比如就需要去生成大量的索引,而生成索引的是非常消耗资源的,索引会造成系统性能急剧下降,保留前面一个索引可以来判断新的数据是否能命中前面的缓存,如果命中了则直接将之前的索引拷贝到最新的索引中来,这样就大大提高了索引的效率,索引我们需要保留两个索引,之前的索引则会删除掉。
索引的名称是根据系统的纳秒时间戳原子+1后生成的16进制数据:
// lib/storage/storage.go
func nextIndexDBTableName() string {
n := atomic.AddUint64(&indexDBTableIdx, 1)
return fmt.Sprintf("%016X", n)
}
var indexDBTableIdx = uint64(time.Now().UnixNano())
启动 vmstorage 的时候就会去打开索引,默认路径为
// lib/storage/storage.go
// 打开索引数据表 path=vmstorage-data/indexdb
func (s *Storage) openIndexDBTables(path string) (curr, prev *indexDB, err error) {
//索引目录不存在则创建
if err := fs.MkdirAllIfNotExist(path); err != nil {
return nil, nil, fmt.Errorf("cannot create directory %q: %w", path, err)
}
d, err := os.Open(path)
if err != nil {
return nil, nil, fmt.Errorf("cannot open directory: %w", err)
}
defer fs.MustClose(d)
// 搜索最近的两个表,最后一个表示活跃状态的,前面一个包含备份数据
fis, err := d.Readdir(-1)
if err != nil {
return nil, nil, fmt.Errorf("cannot read directory: %w", err)
}
var tableNames []string
for _, fi := range fis {
if !fs.IsDirOrSymlink(fi) {
// 不是目录则跳过
continue
}
tableName := fi.Name()
if !indexDBTableNameRegexp.MatchString(tableName) {
// 名称不符合规范也有跳过
continue
}
// 剩下的就是所有的表名称了
tableNames = append(tableNames, tableName)
}
// 对表名进行排序
sort.Slice(tableNames, func(i, j int) bool {
return tableNames[i] < tableNames[j]
})
// 如果表名个数小于2,则创建
if len(tableNames) < 2 {
// 如果没有表名,则先创建前面一个表名
if len(tableNames) == 0 {
// 生成前面一个表名
prevName := nextIndexDBTableName()
tableNames = append(tableNames, prevName)
}
//生成后面的一个表名(在前面表名的基础上做原子+1操作的16进制数据)
currName := nextIndexDBTableName()
tableNames = append(tableNames, currName)
}
// Invariant: len(tableNames) >= 2
// 如果操过2个表,则只保留最后两个表,其他不需要了,没意义,因为过期了
for _, tn := range tableNames[:len(tableNames)-2] {
pathToRemove := path + "/" + tn
logger.Infof("removing obsolete indexdb dir %q...", pathToRemove)
fs.MustRemoveAll(pathToRemove)
logger.Infof("removed obsolete indexdb dir %q", pathToRemove)
}
// 持久化变更
fs.MustSyncPath(path)
// 打开最后两个表
currPath := path + "/" + tableNames[len(tableNames)-1]
logger.Infof("1.prepare open index db currPath %s", currPath)
curr, err = openIndexDB(currPath, s, 0)
if err != nil {
return nil, nil, fmt.Errorf("cannot open curr indexdb table at %q: %w", currPath, err)
}
prevPath := path + "/" + tableNames[len(tableNames)-2]
logger.Infof("2.prepare open index db prevPath %s", prevPath)
prev, err = openIndexDB(prevPath, s, 0)
if err != nil {
curr.MustClose()
return nil, nil, fmt.Errorf("cannot open prev indexdb table at %q: %w", prevPath, err)
}
return curr, prev, nil
}
当索引目录不存在的时候会创建该目录,然后去该目录中查找最近的两个索引,如果没有两个索引,则去生成对应的索引目录,索引的名称就是上面的纳秒时间戳原子+1后的16进制数据,然后通过 openIndexDB 函数分别打开这两个索引。
openIndexDB 函数用于打开指定路径的索引,其实就是生成一个 indexDB 对象,indexDB 结构体定义如下所示:
// lib/storage/index_db.go
// indexDB 代表一个 index db.
type indexDB struct {
// 原子计数器必须位于结构体的顶部,以便在32位架构上正确对齐8个字节
// See https://github.com/VictoriaMetrics/VictoriaMetrics/issues/212 .
refCount uint64
// 新创建的时间序列的计数器,可用于确定时间序列的 churn rate。
newTimeseriesCreated uint64
// 在轮换后从以前的 indexDB 重新填充的时间序列的计数器。
timeseriesRepopulated uint64
// MetricID -> TSID 条目 miss 的数量
// 该值比率如果较高则证明 indexDB 损坏了
missingTSIDsForMetricID uint64
// date range 搜索的调用数
dateRangeSearchCalls uint64
// date range 搜索的命中数
dateRangeSearchHits uint64
// 全局搜索调用次数
globalSearchCalls uint64
// MetricID -> MetricName 条目 miss 的数量
// 高比率可能意味着由于不干净的关机导致索引数据库损坏。
// 之后必须自动恢复db
missingMetricNamesForMetricID uint64
// 标记为删除
mustDrop uint64
// 标识索引的 生成 ID(可以看成是第几代索引),并用于同步来自不同 indexDB 的数据
generation uint64
// indexDB 轮换的unix时间戳(以秒为单位)。
rotationTimestamp uint64
// 索引名称
name string
// Table 表结构
tb *mergeset.Table
// 相当于之前的一个 indexDB
extDB *indexDB
extDBLock sync.Mutex
// 用于快速查找 TagFilters -> TSIDs 的缓存
tagFiltersCache *workingsetcache.Cache
// 父级存储引用
s *Storage
// (date, tagFilter) -> loopsCount 的缓存
// 用于减少匹配一组过滤器时的工作量。
loopsPerDateTagFilterCache *workingsetcache.Cache
// 索引搜索的对象池
indexSearchPool sync.Pool
}
openIndexDB 函数实现代码如下所示,整体比较简单,就是去构造一个 indexDB 对象,索引路径的最后一段(也就是文件夹的名称)转换成10进制的数据就会用来表示 indexDB 的 generation:
// lib/storage/index_db.go
// openIndexDB 从指定路径打开索引 db 文件
//
// path 路径的最后一段应该是一个唯一的16进制数据,会被用作 indexDB.generation
//
// 当在 indexdb 轮换期间创建新的 indexdb 时,ipenIndexDB 被调用时
// rotationTimestamp 必须设置为当前的 unix 时间戳。
func openIndexDB(path string, s *Storage, rotationTimestamp uint64) (*indexDB, error) {
if s == nil {
logger.Panicf("BUG: Storage must be nin-nil")
}
// 获取路径的最后一段,也就是索引表(文件夹)的名称
name := filepath.Base(path)
// 将16进制数据转换成10进制的数据,用来表示 indexDB.generation
gen, err := strconv.ParseUint(name, 16, 64)
logger.Infof("Open Index DB path %s, and gen %d", name, gen)
if err != nil {
return nil, fmt.Errorf("failed to parse indexdb path %q: %w", path, err)
}
tb, err := mergeset.OpenTable(path, invalidateTagFiltersCache, mergeTagToMetricIDsRows)
if err != nil {
return nil, fmt.Errorf("cannot open indexDB %q: %w", path, err)
}
// 不要将 tagFiltersCache 保存在文件中,因为它非常不稳定。
mem := memory.Allowed()
db := &indexDB{
refCount: 1,
generation: gen,
rotationTimestamp: rotationTimestamp,
tb: tb,
name: name,
tagFiltersCache: workingsetcache.New(mem / 32),
s: s,
loopsPerDateTagFilterCache: workingsetcache.New(mem / 128),
}
return db, nil
}
构造 indexDB 对象中最核心部分就是获取 Table 表对象了,通过 mergeset.OpenTable 函数来实现。要搞清楚这个 Table 表是什么,首先我们需要去看下其结构定义:
// lib/mergeset/table.go
// Table 代表 mergeset 表.
type Table struct {
// 原子更新的计数器必须在结构体最前面,这样在32位架构上可以正确地对齐到8字节。
// See https://github.com/VictoriaMetrics/VictoriaMetrics/issues/212
activeMerges uint64
mergesCount uint64
itemsMerged uint64
assistedMerges uint64
mergeIdx uint64
path string
// 将数据刷新到存储的回调
flushCallback func()
flushCallbackWorkerWG sync.WaitGroup
needFlushCallbackCall uint32
// block 准备好的回调
prepareBlock PrepareBlockCallback
partsLock sync.Mutex
// 包含的 part 列表
parts []*partWrapper
// rawItems 包含最近添加的尚未转换为 parts 的数据。
// 出于性能原因,未在搜索中使用 rawItems
rawItems rawItemsShards
snapshotLock sync.RWMutex
flockF *os.File
stopCh chan struct{}
// 使用 syncwg 而不是sync,因为可以从并发 goroutine 调用 Add/Wait。
partMergersWG syncwg.WaitGroup
rawItemsFlusherWG sync.WaitGroup
convertersWG sync.WaitGroup
// 使用 syncwg 而不是sync,因为可以从并发 goroutine 调用 Add/Wait。
rawItemsPendingFlushesWG syncwg.WaitGroup
}
OpenTable 函数实现如下所示,首先会判断表目录是否存在,不存在就创建这个目录,然后创建 flock.lock 文件防止并发打开,然后就是核心的 openParts 函数打开表的 part 列表:
// lib/mergeset/table.go
// OpenTable 在指定路径上打开一个 table
//
// 每次将新数据批次刷新到底层存储并对搜索可见时,都会调用可选的 flushCallback 回调。
//
// 在将准备好的 block 块刷新到持久存储之前,在合并期间调用可选的 prepareBlock 回调。
//
// 如果该表还不存在,则创建该表。
func OpenTable(path string, flushCallback func(), prepareBlock PrepareBlockCallback) (*Table, error) {
path = filepath.Clean(path)
logger.Infof("opening table %q...", path)
startTime := time.Now()
// 如果表还不存在,那么为它创建一个目录
if err := fs.MkdirAllIfNotExist(path); err != nil {
return nil, fmt.Errorf("cannot create directory %q: %w", path, err)
}
// 创建 flock.lock 文件,防止并发打开
flockF, err := fs.CreateFlockFile(path)
if err != nil {
return nil, err
}
// 打开表 parts
pws, err := openParts(path)
if err != nil {
return nil, fmt.Errorf("cannot open table parts at %q: %w", path, err)
}
tb := &Table{
path: path,
flushCallback: flushCallback,
prepareBlock: prepareBlock,
parts: pws,
mergeIdx: uint64(time.Now().UnixNano()),
flockF: flockF,
stopCh: make(chan struct{}),
}
// 初始化 rawItems
tb.rawItems.init()
// 开始执行 partMerges 的工作
tb.startPartMergers()
// 开始执行 rawItems 刷新的工作
tb.startRawItemsFlusher()
// 更新表相关的指标数据
var m TableMetrics
tb.UpdateMetrics(&m)
logger.Infof("table %q has been opened in %.3f seconds; partsCount: %d; blocksCount: %d, itemsCount: %d; sizeBytes: %d",
path, time.Since(startTime).Seconds(), m.PartsCount, m.BlocksCount, m.ItemsCount, m.SizeBytes)
tb.convertersWG.Add(1)
go func() {
tb.convertToV1280()
tb.convertersWG.Done()
}()
// 如果有刷新回调则执行回调
if flushCallback != nil {
tb.flushCallbackWorkerWG.Add(1)
go func() {
// 每10秒调用一次 flushCallback,以提高缓存的效率
// 缓存由 flushCallback 重置
tc := time.NewTicker(10 * time.Second)
for {
select {
case <-tb.stopCh: // 停止
tb.flushCallback()
tb.flushCallbackWorkerWG.Done()
return
case <-tc.C:
// 如果需要刷新,则调用刷新回调
if atomic.CompareAndSwapUint32(&tb.needFlushCallbackCall, 1, 0) {
tb.flushCallback()
}
}
}
}()
}
return tb, nil
}
openParts 返回的就是一个包装的 part 列表 partWrapper,里面除了 part 的引用之外,还包括在内存中的 inmemoryPart 的引用。
// lib/mergeset/table.go
type partWrapper struct {
p *part
mp *inmemoryPart
refCount uint64
isInMerge bool
}
func openParts(path string) ([]*partWrapper, error) {
// 从备份还原后,可能会丢失路径,所以需要的时候就创建它
if err := fs.MkdirAllIfNotExist(path); err != nil {
return nil, err
}
d, err := os.Open(path)
if err != nil {
return nil, fmt.Errorf("cannot open difrectory: %w", err)
}
defer fs.MustClose(d)
// 执行剩余的事务和清理 /txn 和 /tmp 目录。
// 尚未创建快照,使用 fakeSnapshotLock
var fakeSnapshotLock sync.RWMutex
if err := runTransactions(&fakeSnapshotLock, path); err != nil {
return nil, fmt.Errorf("cannot run transactions: %w", err)
}
// 清理事务目录 txn,然后重新创建
txnDir := path + "/txn"
fs.MustRemoveAll(txnDir)
if err := fs.MkdirAllFailIfExist(txnDir); err != nil {
return nil, fmt.Errorf("cannot create %q: %w", txnDir, err)
}
// 清理临时数据目录 tmp,然后重新创建
tmpDir := path + "/tmp"
fs.MustRemoveAll(tmpDir)
if err := fs.MkdirAllFailIfExist(tmpDir); err != nil {
return nil, fmt.Errorf("cannot create %q: %w", tmpDir, err)
}
fs.MustSyncPath(path)
// 获取所有的 parts
fis, err := d.Readdir(-1)
if err != nil {
return nil, fmt.Errorf("cannot read directory: %w", err)
}
var pws []*partWrapper
for _, fi := range fis {
if !fs.IsDirOrSymlink(fi) {
// 跳过非目录的
continue
}
fn := fi.Name()
if isSpecialDir(fn) {
// 跳过一些特殊的目录
continue
}
partPath := path + "/" + fn
if fs.IsEmptyDir(partPath) { // 如果为空目录
// 删除空目录,该目录可以在NFS上不干净关闭后保留下来。
// See https://github.com/VictoriaMetrics/VictoriaMetrics/issues/1142
fs.MustRemoveAll(partPath)
continue
}
// 打开 Part
p, err := openFilePart(partPath)
if err != nil {
mustCloseParts(pws)
return nil, fmt.Errorf("cannot open part %q: %w", partPath, err)
}
// 将 Part 放进包装的 partWrapper 中去
pw := &partWrapper{
p: p,
refCount: 1,
}
pws = append(pws, pw)
}
return pws, nil
}
openParts 的过程其实就是去构造表的过程,比如重置事务目录 txn、临时数据目录 tmp,当第一次启动的时候可以看出 parts 是为空的,索引 openParts 会返回一个空的切片。那么什么时候才会有 part 数据产生呢?自然要等到有数据写入的时候,所以接下来我们要去启动 vminsert 这个组件。
首先同样需要在 IDE 中来启动 vminsert,但是在启动之前需要配置下启动参数,因为 vminsert 需要将数据传输到 vmstorage 中去的,在 app/vminsert/main.go 文件上右键选择 Modify Run Configuration...:
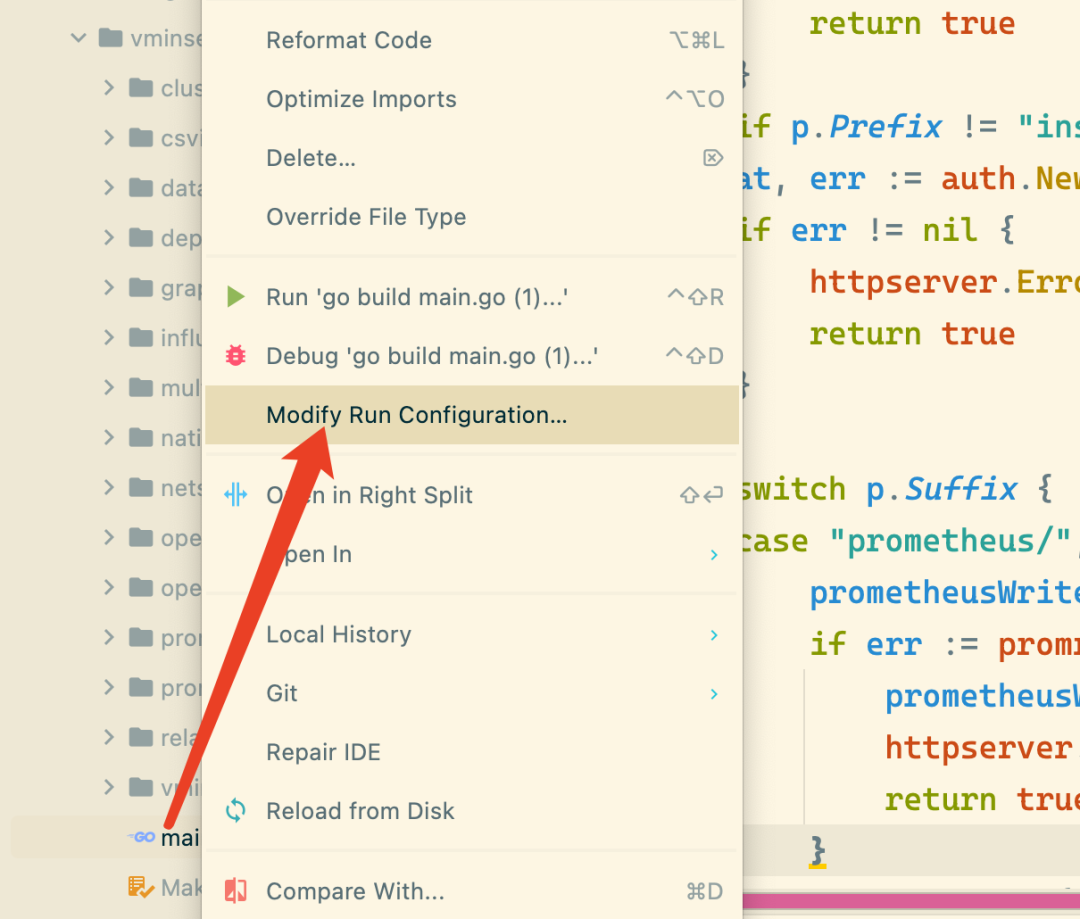
在配置对话框中的 Program arguments 行添加需要配置的参数,比如我们这里添加 -storageNode=127.0.0.1:8401,意思就是 vminert 接收到数据后会发送到后面的 storageNode 节点去:
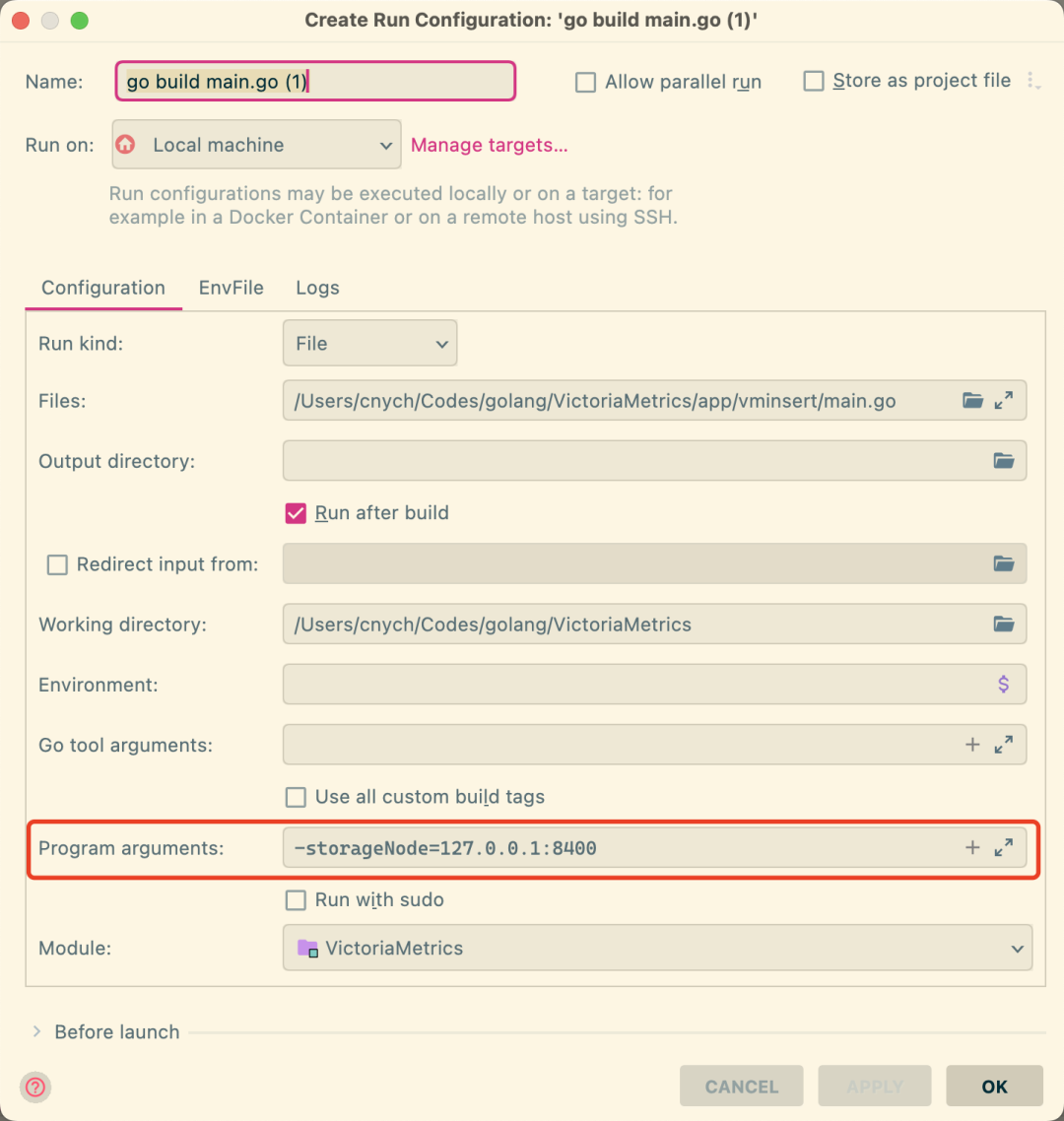
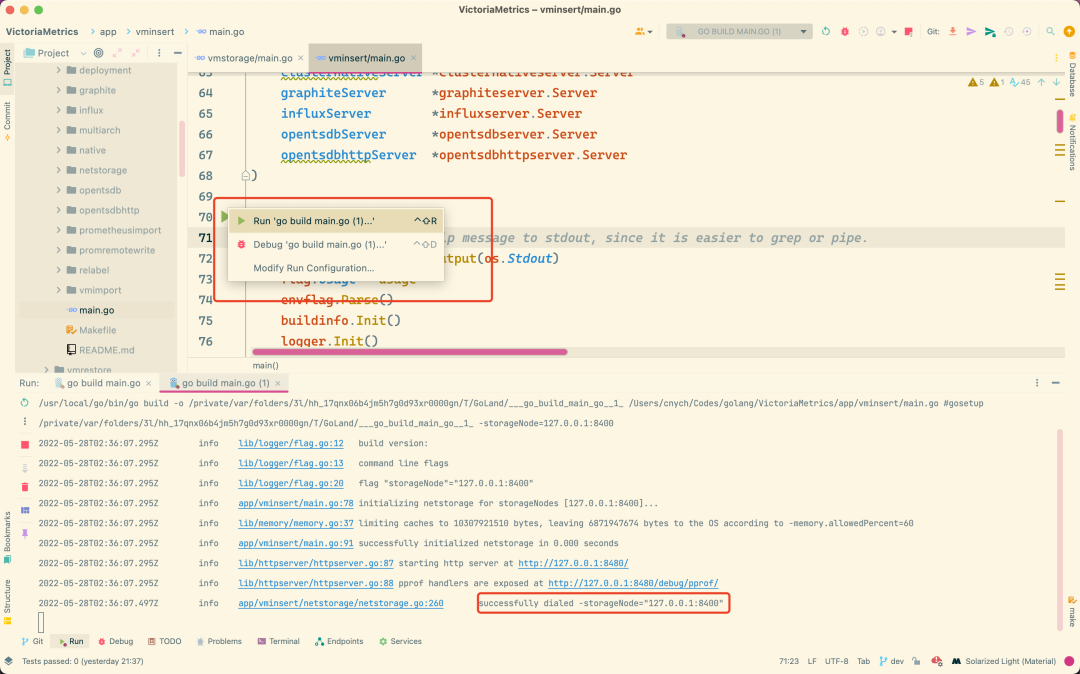
配置好后和前面一样再次去启动 app/vminsert/main.go 即可,如下所示。可以看到 vminsert 成功和 127.0.0.1:8400 建立了连接,也就是上面的 vmstorage 节点:
同样当连接建立后在 vmstorage 节点这边也有相应的日志体现,如下所示:
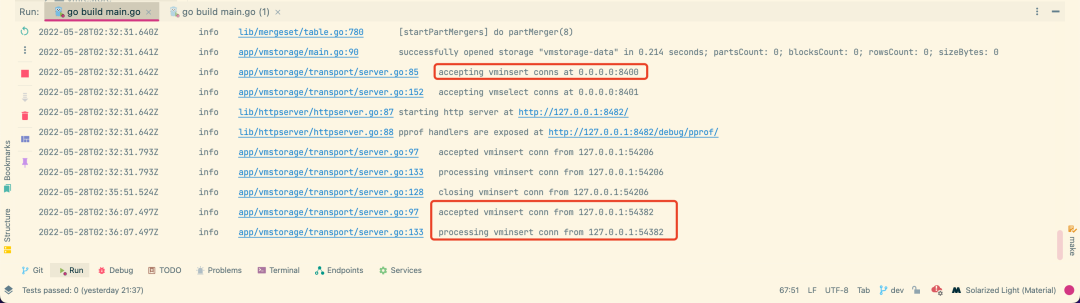
vmstorage 在 8400 端口上接收 vminsert 的请求,8401 端口上接收 vmselect 的请求,通过 transport.NewServer 去初始化 Server,然后分别在一个 goroutine 中去启动监听 vminsert、vmselect 的请求:
// app/vmstorage/main.go
srv, err := transport.NewServer(*vminsertAddr, *vmselectAddr, strg)
if err != nil {
logger.Fatalf("cannot create a server with vminsertAddr=%s, vmselectAddr=%s: %s", *vminsertAddr, *vmselectAddr, err)
}
go srv.RunVMInsert()
go srv.RunVMSelect()
我们可以先看看这里的 Server 是如何定义的:
// app/vmstorage/transport/server.go
// Server 用于处理来自 vminsert 和 vmselect 的连接
type Server struct {
// 将 stopFlag 移动到结构体顶部,以便在32位架构上修复对它的原子访问(内存对齐)。
// See https://github.com/VictoriaMetrics/VictoriaMetrics/issues/212
stopFlag uint64
// 存储引用
storage *storage.Storage
// vminsert和vmselect的网络监听器
vminsertLN net.Listener
vmselectLN net.Listener
vminsertWG sync.WaitGroup
vmselectWG sync.WaitGroup
// 用于跟踪vminsert与vmselect的活跃连接
vminsertConnsMap ingestserver.ConnsMap
vmselectConnsMap ingestserver.ConnsMap
}
// NewServer 实例化 Server.
func NewServer(vminsertAddr, vmselectAddr string, storage *storage.Storage) (*Server, error) {
// 初始化网络监听器
vminsertLN, err := netutil.NewTCPListener("vminsert", vminsertAddr, nil)
if err != nil {
return nil, fmt.Errorf("unable to listen vminsertAddr %s: %w", vminsertAddr, err)
}
vmselectLN, err := netutil.NewTCPListener("vmselect", vmselectAddr, nil)
if err != nil {
return nil, fmt.Errorf("unable to listen vmselectAddr %s: %w", vmselectAddr, err)
}
if err := encoding.CheckPrecisionBits(uint8(*precisionBits)); err != nil {
return nil, fmt.Errorf("invalid -precisionBits: %w", err)
}
s := &Server{
storage: storage,
vminsertLN: vminsertLN,
vmselectLN: vmselectLN,
}
// 初始化活跃连接Map
s.vminsertConnsMap.Init()
s.vmselectConnsMap.Init()
return s, nil
}
// lib/ingestserver/conns_map.go
// ConnsMap 用于跟踪活跃的连接
type ConnsMap struct {
mu sync.Mutex
m map[net.Conn]struct{}
isClosed bool
}
Server 里面主要了包含 vminsert 和 vmselect 的监听器,还有专门用来跟踪活跃连接的 ConnsMap,其实就是一个 Map,Server 初始化后会通过一个 goroutine 执行 RunVMInsert:
// app/vmstorage/transport/server.go
// RunVMInsert 运行接受 vminsert 连接的服务器
func (s *Server) RunVMInsert() {
logger.Infof("accepting vminsert conns at %s", s.vminsertLN.Addr())
for {
// 等待并返回到监听器的下一个连接
c, err := s.vminsertLN.Accept()
if err != nil {
if pe, ok := err.(net.Error); ok && pe.Temporary() {
continue
}
if s.isStopping() {
return
}
logger.Panicf("FATAL: cannot process vminsert conns at %s: %s", s.vminsertLN.Addr(), err)
}
logger.Infof("accepted vminsert conn from %s", c.RemoteAddr())
// 将该连接c添加到ConnsMap中
if !s.vminsertConnsMap.Add(c) {
// 关闭连接
_ = c.Close()
return
}
// vminsert连接数+1
vminsertConns.Inc()
s.vminsertWG.Add(1)
go func() {
defer func() {
// 处理完过后清理连接
s.vminsertConnsMap.Delete(c)
vminsertConns.Dec()
s.vminsertWG.Done()
}()
// 不需要响应压缩
// vmstorage 只会发送小的 packets 给 vminsert
compressionLevel := 0
// VMInsertServer 为 vminsert 执行服务器端握手的协议
// 得到的是一个带 buffer 的 net.Conn(BufferedConn)
bc, err := handshake.VMInsertServer(c, compressionLevel)
if err != nil {
if s.isStopping() {
// c 在服务器内停止,必须关闭
return
}
logger.Errorf("cannot perform vminsert handshake with client %q: %s", c.RemoteAddr(), err)
_ = c.Close()
return
}
defer func() {
if !s.isStopping() {
logger.Infof("closing vminsert conn from %s", c.RemoteAddr())
}
_ = bc.Close()
}()
// 真正处理 vminsert 连接的逻辑
logger.Infof("processing vminsert conn from %s", c.RemoteAddr())
if err := s.processVMInsertConn(bc); err != nil {
if s.isStopping() {
return
}
vminsertConnErrors.Inc()
logger.Errorf("cannot process vminsert conn from %s: %s", c.RemoteAddr(), err)
}
}()
}
}
RunVMInsert 用来不断接收监听器的连接,获取到连接 c 过后记得添加到 ConnsMap 中去,表示当前连接是活跃连接,然后要开另外一个 goroutine 去处理连接,在连接处理完成后要在 goroutine 退出之前要记得清理连接,从 ConnsMap 移出掉,真正处理连接的过程是先通过 handshake.VMInsertServer 创建一个带有 buffer 的 net.Conn 连接,真正处理连接的逻辑是通过 processVMInsertConn 来完成的。
// app/vmstorage/transport/server.go
func (s *Server) processVMInsertConn(bc *handshake.BufferedConn) error {
return clusternative.ParseStream(bc, func(rows []storage.MetricRow) error {
vminsertMetricsRead.Add(len(rows))
return s.storage.AddRows(rows, uint8(*precisionBits))
}, s.storage.IsReadOnly)
}
可以看到上面的函数是通过 clusternative.ParseStream 来进行处理的,该函数解析从 vminsert 发送到 bc 的数据,并对解析的行数据执行回调。我们可以先来看下这个函数的具体实现:
// lib/protoparser/clusternative/streamparser.go
// ParseStream 解析从 vminsert 发送到 bc 的数据,并对解析的行数据执行回调。
// 如果存储无法接受新数据,则可选函数 isReadOnly 必须返回 true。在这种情况下,从 bc 读取的数据不被接受,只读状态被发回 bc。
//
// 对于来自 req 的流数据,可以多次并发调用回调。
//
// 回调在返回后不应阻塞。
func ParseStream(bc *handshake.BufferedConn, callback func(rows []storage.MetricRow) error, isReadOnly func() bool) error {
var wg sync.WaitGroup
var (
callbackErrLock sync.Mutex
callbackErr error
)
for {
// 不要使用 unmarshalWork pool,因为每个 unmarshalWork 结构通常占用大量内存(超过 consts.MaxInsertPacketSize 字节)。该 pool 将导致内存使用量增加。
uw := &unmarshalWork{}
// 设置回调 callback
uw.callback = func(rows []storage.MetricRow) {
// 执行回调
if err := callback(rows); err != nil {
processErrors.Inc()
callbackErrLock.Lock()
if callbackErr == nil {
callbackErr = fmt.Errorf("error when processing native block: %w", err)
}
callbackErrLock.Unlock()
}
}
uw.wg = &wg
var err error
// readBlock 从 vminsert 的 bc 连接中读取下一个数据块。
uw.reqBuf, err = readBlock(uw.reqBuf[:0], bc, isReadOnly)
if err != nil {
wg.Wait()
if err == io.EOF {
// Remote end gracefully closed the connection.
return nil
}
return err
}
blocksRead.Inc()
wg.Add(1)
// 获取数据后将数据传递到 unmarshalWorkCh 通道中,unmarshal workers 会在其他 goroutine 中进行处理
common.ScheduleUnmarshalWork(uw)
}
}
在上面的 ParseStream 函数中会通过 readBlock 函数不断从 bc 连接中读取数据块,readBlock 中获取到数据后会发送 ack 给到客户端的 vminsert,表示传递的网络数据已经正确获取到。当获取到数据后会传递到 unmarshalWorkCh 通道中,unmarshal workers 会在其他 goroutine 中去进行处理。
// lib/protoparser/common/unmarshal_work.go
// StartUnmarshalWorkers 启动 unmarshal workers.
func StartUnmarshalWorkers() {
if unmarshalWorkCh != nil {
logger.Panicf("BUG: it looks like startUnmarshalWorkers() has been alread called without stopUnmarshalWorkers()")
}
gomaxprocs := cgroup.AvailableCPUs() //获取 CUP 核数
unmarshalWorkCh = make(chan UnmarshalWork, gomaxprocs) // 初始化channel通道,长度与核数相等
unmarshalWorkersWG.Add(gomaxprocs)
for i := 0; i < gomaxprocs; i++ {
go func() { // 启动N个 goroutine,数量与 CPU 核数一样
defer unmarshalWorkersWG.Done() // waitgroup 完成
for uw := range unmarshalWorkCh {
uw.Unmarshal() // 执行具体的业务逻辑
}
}()
}
}
而上面的 StartUnmarshalWorkers() 函数在 vmstorage 的 main 函数中就调用了,所以我们只需要做的就是往 unmarshalWorkCh 通道传数据过去即可。
// app/vmstorage/main.go
func main() {
......
common.StartUnmarshalWorkers()
srv, err := transport.NewServer(*vminsertAddr, *vmselectAddr, strg)
......
}
真正执行具体的业务逻辑是 Unmarshal() 函数:
// lib/protoparser/clusternative/streamparser.go
// 真正处理 vminsert 传过来的数据的业务逻辑
func (uw *unmarshalWork) Unmarshal() {
reqBuf := uw.reqBuf // vminsert 传过来的数据
for len(reqBuf) > 0 {
// 限制传递给回调的行数,以减少处理大行数据包时的内存使用。
// 将 reqBuf 转换成插入存储中的指标数据列表 []MetricRow
mrs, tail, err := storage.UnmarshalMetricRows(uw.mrs[:0], reqBuf, maxRowsPerCallback)
uw.mrs = mrs
if err != nil {
parseErrors.Inc()
logger.Errorf("cannot unmarshal MetricRow from clusternative block with size %d (remaining %d bytes): %s", len(reqBuf), len(tail), err)
break
}
rowsRead.Add(len(mrs))
// 调用回调
uw.callback(mrs)
reqBuf = tail
}
wg := uw.wg
wg.Done()
}
const maxRowsPerCallback = 10000
上面的函数中先将从 vminsert 传过来的数据通过 storage.UnmarshalMetricRows 函数转换成可以直接存入到 vmstorage 存储中的 MetricRow 列表,转换完成后调用 callback 去进行处理,这样就可以回到前面的 processVMInsertConn 函数中了,clusternative.ParseStream 的第二个参数就是回调函数。
// app/vmstorage/transport/server.go
func (s *Server) processVMInsertConn(bc *handshake.BufferedConn) error {
return clusternative.ParseStream(bc, func(rows []storage.MetricRow) error {
vminsertMetricsRead.Add(len(rows))
return s.storage.AddRows(rows, uint8(*precisionBits))
}, s.storage.IsReadOnly)
}
最后就是通过 s.storage.AddRows 函数去处理添加转换过后的 MetricRow 列表,这也是真正的将数据存入到本地存储的入口函数了。
现在我们知道了服务的 vmstorage 如何去接收客户端 vminsert 传过来的数据了,那么 vminsert 中是如何来发送网络请求的呢?未完待续.....