
Airflow 基础 | Airflow 基础系列-02:Executor 详解
本文引自https://www.astronomer.io/guides/airflow-executors-explained
对于是一个Airflow新手而言,Airflow Executor的概念可能会难以理解。即使作为成熟的Airflow用户和数据工程师,想要确定在实践中使用哪种Executor,也需要慎重的权衡各种因素。
为了让读者更好的理解Airflow Executor,本文将从以下2个方面进行阐述:
介绍Executor的核心功能,在Airflow架构中的地位和一些重要配置参数
介绍3种最常用的Executor: LocalExecutor,CeleryExecutor和KubernetesExecutor
什么是Executor
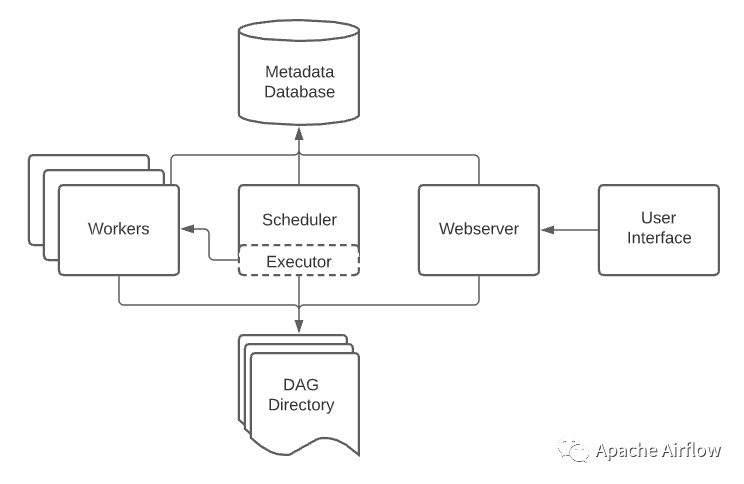
概念上来说,Executor代表了Airflow任务实例的运行机制。当一个DAG完成创建并触发一次DAG Run之后,为了确保该DAG中的各个task按期望的顺序正确执行,Airflow会执行以下步骤:
DAG中的所有task信息和依赖关系会保存在Airflow配置的元数据库中(可能是MySQL或者PostgreSQL)。
Scheduler会读取元数据库中的任务,根据DAG定义决定task执行顺序生成并启动执行计划,将task实例添加到调度队列中
Executor(从架构图上可以看到部署在Scheduler服务中)接收调度队列中的task实例,确认完成这个task实例需要哪些资源,并将task实例分发到指定资源上执行。
如上所述,对于不同Executor之间的区别,我们可以总结为用于运行task实例资源的区别。这种实例资源可以是分布式的(如Celery,Yarn或Kubernetes),也可以是本地化的(Local)。
常用的Executor
下面我们将着重介绍3种常用的Executor和他们的主要使用场景。
LocalExecutor
在Airflow中使用LocalExecutor是比较典型的单节点部署架构,Scheduler和所有执行Task的代码都运行在同一个节点上(可能是你的笔记本电脑或者一个EC2实例)。Airflow Worker以LocalWorker的形式并发运行Scheduler分发的task。
在使用LocalExecutor的情况下,我们不需要该节点外的其他资源即可运行DAG。由于LocalExecutor将所有工作负载都运行在一个节点上。其优缺点如下所述
优点
易于理解和部署
即使在单节点上依然具有并发能力
缺点
缺乏扩展性
存在单点失败可能性
基于以上特性,在测试或者开发环境下选择LocalExecutor是一个理想的选择。在生产环境下,考虑到系统鲁棒性和扩展性应该避免使用LocalExecutor。
CeleryExecutor
CeleryExecutor是一种易于水平扩展的Executor,基于Celery实现。Celery本身是一个Python分布式队列组件,在这里我们不对Celery相关的技术细节赘述,详情可参考Celery官方文档(https://docs.celeryproject.org/en/stable/)。CeleryWorker需要和一个Worker节点池(CeleryWorker)通过消息队列协同工作,以实现任务调度和运行的灵活性和可用性。假如Worker节点池中的节点宕机,CeleryExecutor能够通过将任务进行重新分发以实现故障恢复。
需要注意的是,使用CeleryExecutor时必须要部署一个消息队列中间件(例如RabbitMQ/Redis)才能使整个流程顺利工作。对于如何选择合适的消息队列中间件,也可以参考Celery官方文档中的相关介绍(https://docs.celeryproject.org/en/stable/getting-started/backends-and-brokers/index.html)。
总结来说,CeleryExecutor相较于LocalExecutor,在高可用性和水平扩展性上具有显著优势,是一种比较适合于生产环境部署的选择。但是由于使用CeleryExecutor时需要额外引入消息队列中间件,也会为系统的整体运维带来额外的成本。
KubernetesExecutor
KubernetesExecutor利用Kubernetes在资源管理、调度等领域的能力,实现Airflow任务实例的分发。关于Kubernetes相关的知识我们在此同样不做赘述,详情可参考Kubernetes官方文档(https://kubernetes.io/)。
KubernetesExecutor通过Kubernetes API启动pods以触发Airflow任务实例的运行,因此在使用时至少需要指定pod的资源用量(CPU/Memory),Service Account和运行镜像。由于Kubernetes具备较强的伸缩能力,在任务数量差别较大的时间段,我们可以通过动态扩缩容最大程度的实现资源的有效利用。
在使用Local和Celery两种Executor时,定期轮询检查每个task的状态(是running, queued还是failed)的工作由Scheduler独自承担。而在使用KubernetesExecutor时,而Scheduler仅仅需要借助Kubernetes的Watcher API订阅pods的事件日志,即可在任务实例失败时更新其状态,避免了大量的无效轮询操作。这样做在某些场景下可以有效降低Scheduler的工作负载。
综上所述,相比于Local和Celery两种Executor,KubernetesExecutor在资源利用、容错和任务精细化配置等方面,因依托于Kubernetes的强大能力而有着较大的优势。当然选择KubernetesExecutor也意味着运维人员需要在Kubernetes的知识储备上有较深的积累,存在一定的使用门槛。