
神奇的SQL之联表细节:MySQL JOIN的执行过程(二)
点击关注上方“SQL数据库开发”,
设为“置顶或星标”,第一时间送达干货 SQL专栏 SQL基础知识第二版
SQL高级知识第二版
神奇的SQL之联表细节:MySQL JOIN的执行过程(一)中,我们讲到了 JOIN 的部分内容,像:驱动表、JOIN 大致流程等。还没看的小伙伴赶紧去补课!下面是这篇的主要内容:
BKA(Batched Key Access)
ON 和 WHERE
数据库:MySQL 5.7.1
存储引擎:InnoDB
建表和初始化数据
-- 查看版本和存储引擎SELECT VERSION();
SHOW ENGINES;
SHOW VARIABLES LIKE '%storage_engine%';-- 表创建与数据初始化DROP TABLE IF EXISTS tbl_user;CREATE TABLE tbl_user (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键', user_name VARCHAR(50) NOT NULL COMMENT '用户名',
sex TINYINT(1) NOT NULL COMMENT '性别, 1:男,0:女',
create_time datetime NOT NULL COMMENT '创建时间',
update_time datetime NOT NULL COMMENT '更新时间',
remark VARCHAR(255) NOT NULL DEFAULT '' COMMENT '备注', PRIMARY KEY (id)
) COMMENT='用户表';DROP TABLE IF EXISTS tbl_user_login_log;CREATE TABLE tbl_user_login_log (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键', user_name VARCHAR(50) NOT NULL COMMENT '用户名',
ip VARCHAR(15) NOT NULL COMMENT '登录IP',
client TINYINT(1) NOT NULL COMMENT '登录端, 1:android, 2:ios, 3:PC, 4:H5',
create_time datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (id)
) COMMENT='登录日志';INSERT INTO tbl_user(user_name,sex,create_time,update_time,remark) VALUES('何天香',1,NOW(), NOW(),'朗眉星目,一表人材'),
('薛沉香',0,NOW(), NOW(),'天星楼的总楼主薛摇红的女儿,也是天星楼的少总楼主,体态丰盈,乌发飘逸,指若春葱,袖臂如玉,风姿卓然,高贵典雅,人称“天星绝香”的武林第一大美女'),
('慕容兰娟',0,NOW(), NOW(),'武林东南西北四大世家之北世家慕容长明的独生女儿,生得玲珑剔透,粉雕玉琢,脾气却是刚烈无比,又喜着火红,所以人送绰号“火凤凰”,是除天星楼薛沉香之外的武林第二大美女'),
('苌婷',0,NOW(), NOW(),'当今皇上最宠爱的侄女,北王府的郡主,腰肢纤细,遍体罗绮,眉若墨画,唇点樱红;虽无沉香之雅重,兰娟之热烈,却别现出一种空灵'),
('柳含姻',0,NOW(), NOW(),'武林四绝之一的添愁仙子董婉婉的徒弟,体态窈窕,姿容秀丽,真个是秋水为神玉为骨,芙蓉如面柳如腰,眉若墨画,唇若点樱,不弱西子半分,更胜玉环一筹; 摇红楼、听雨轩,琵琶一曲值千金!'),
('李凝雪',0,NOW(), NOW(),'李相国的女儿,神采奕奕,英姿飒爽,爱憎分明'),
('周遗梦',0,NOW(), NOW(),'音神传人,湘妃竹琴的拥有者,云髻高盘,穿了一身黑色蝉翼纱衫,愈觉得冰肌玉骨,粉面樱唇,格外娇艳动人'),
('叶留痕',0,NOW(), NOW(),'圣域圣女,肤白如雪,白衣飘飘,宛如仙女一般,微笑中带着说不出的柔和之美'),
('郭疏影',0,NOW(), NOW(),'扬灰右使的徒弟,秀发细眉,玉肌丰滑,娇润脱俗'),
('钟钧天',0,NOW(), NOW(),'天界,玄天九部 - 钧天部的部主,超凡脱俗,仙气逼人'),
('王雁云',0,NOW(), NOW(),'尘缘山庄二小姐,刁蛮任性'),
('许侍霜',0,NOW(), NOW(),'药王谷谷主女儿,医术高明'),
('冯黯凝',0,NOW(), NOW(),'桃花门门主,娇艳如火,千娇百媚');INSERT INTO tbl_user_login_log(user_name, ip, client, create_time) VALUES('薛沉香', '10.53.56.78',2, '2019-10-12 12:23:45'),
('苌婷', '10.53.56.78',2, '2019-10-12 22:23:45'),
('慕容兰娟', '10.53.56.12',1, '2018-08-12 22:23:45'),
('何天香', '10.53.56.12',1, '2019-10-19 10:23:45'),
('柳含姻', '198.11.132.198',2, '2018-05-12 22:23:45'),
('冯黯凝', '198.11.132.198',2, '2018-11-11 22:23:45'),
('周遗梦', '198.11.132.198',2, '2019-06-18 22:23:45'),
('郭疏影', '220.181.38.148',3, '2019-10-21 09:45:56'),
('薛沉香', '220.181.38.148',3, '2019-10-26 22:23:45'),
('苌婷', '104.69.160.60',4, '2019-10-12 10:23:45'),
('王雁云', '104.69.160.61',4, '2019-10-16 20:23:45'),
('李凝雪', '104.69.160.62',4, '2019-10-17 20:23:45'),
('许侍霜', '104.69.160.63',4, '2019-10-18 20:23:45'),
('叶留痕', '104.69.160.64',4, '2019-10-19 20:23:45'),
('王雁云', '104.69.160.65',4, '2019-10-20 20:23:45'),
('叶留痕', '104.69.160.66',4, '2019-10-21 20:23:45');SELECT * FROM tbl_user;SELECT * FROM tbl_user_login_log;DROP TABLE IF EXISTS tbl_range_access;CREATE TABLE tbl_range_access (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
a INT(11) NOT NULL COMMENT '测试索引',
name VARCHAR(50) NOT NULL COMMENT '姓名',
age TINYINT(3) NOT NULL COMMENT '年龄', PRIMARY KEY (id), INDEX i_a(a)
) COMMENT='mrr测试';INSERT INTO tbl_range_access(a,name,age) VALUES(5,'123654', 23),
(8, 'asdf',20),
(1,'lljl',19),
(4, '98459',64),
(7,'zhangsan', 45),
(9,'lisi',46),
(2,'zhaoqian',25),
(6,'hello', 23),
(3,'world',100),
(10,'666',66),
(88, '888',88);SELECT * FROM tbl_range_access;
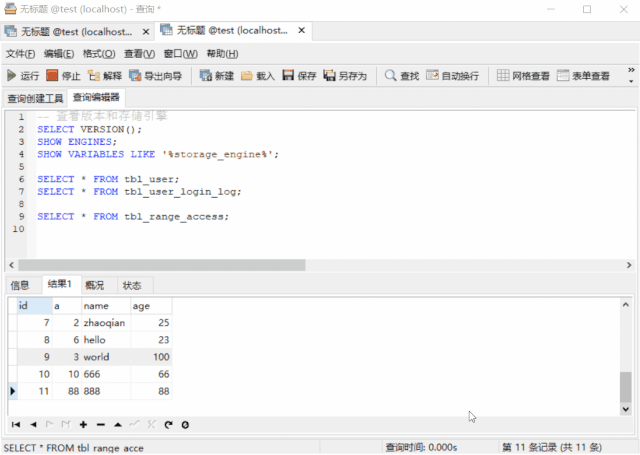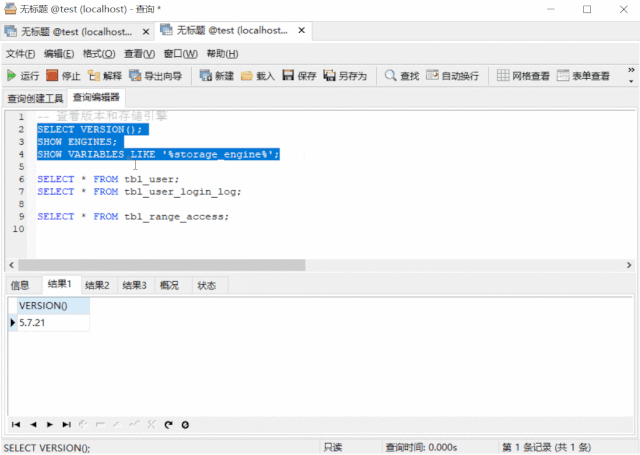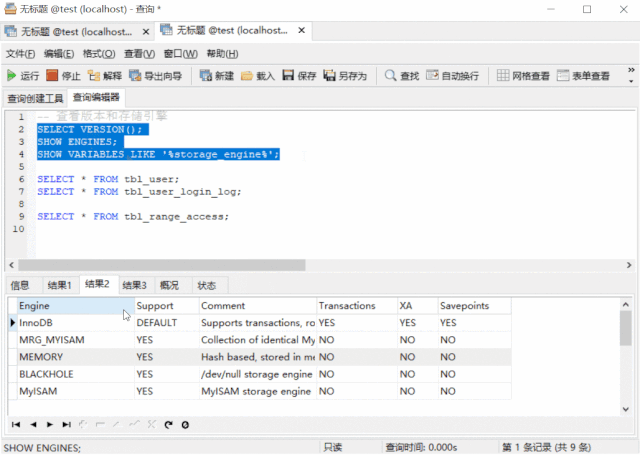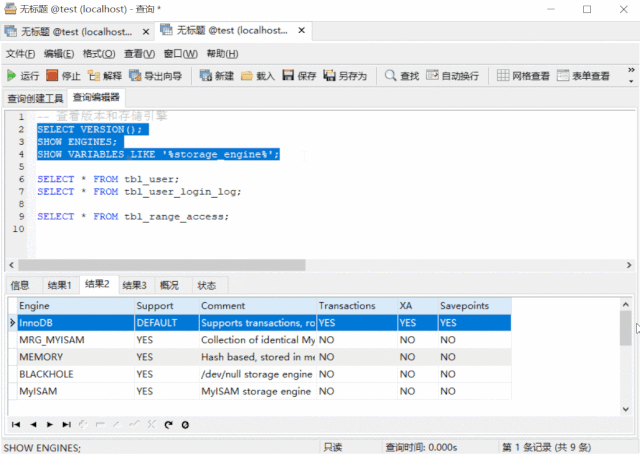
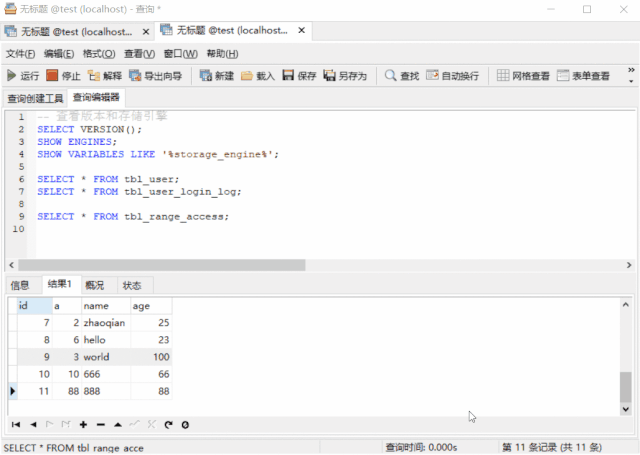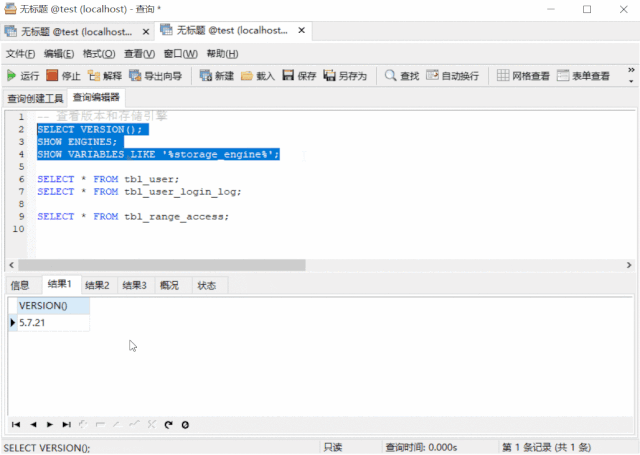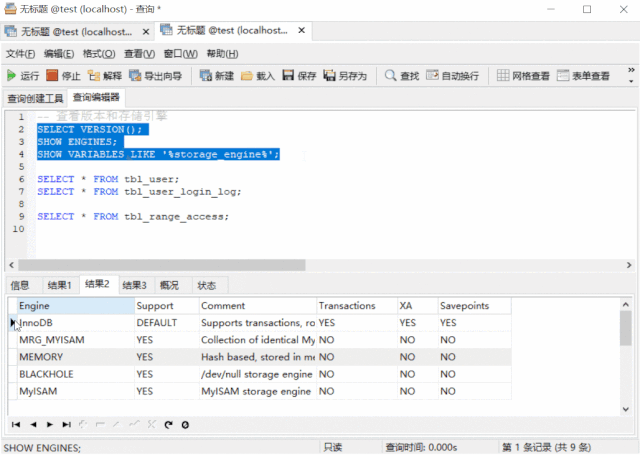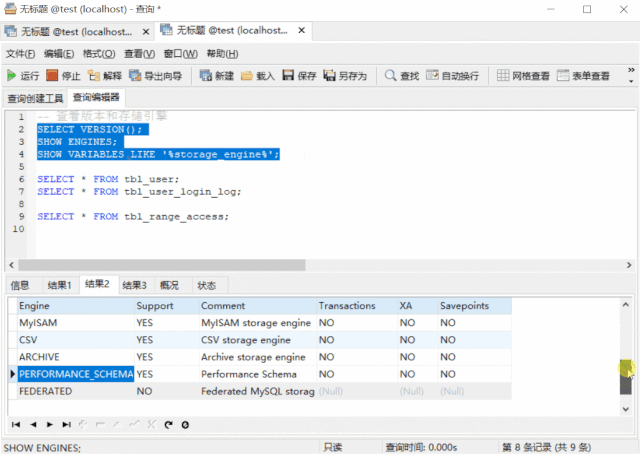
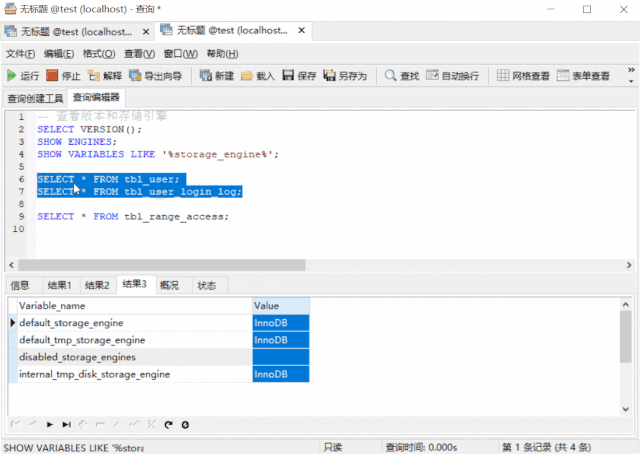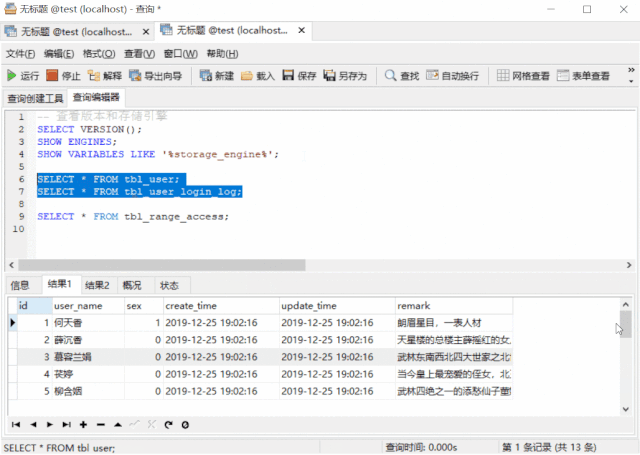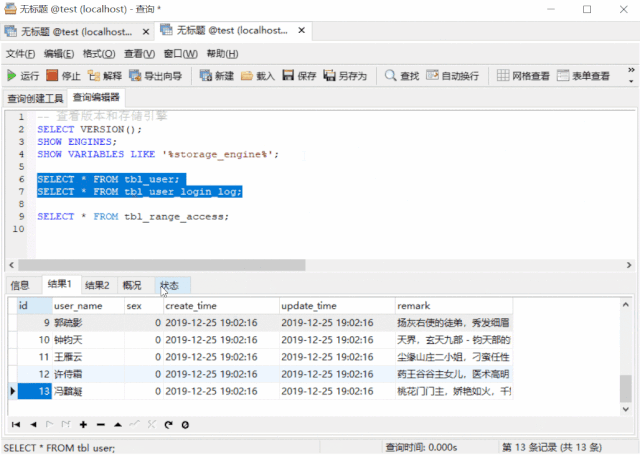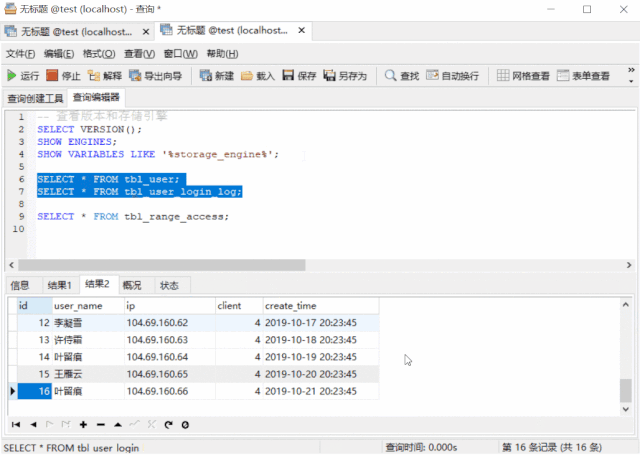
表 tbl_range_access 的数据要多一点,像上面示例只有 11 条记录,那么即使 a 字段上有索引, SELECT * FROM tbl_range_access WHERE a BETWEEN 4 AND 9; 也不会走索引,执行计划如下:

数据太少,优化器觉得走索引,然后回表查询数据,还不如直接走聚簇索引全表查询来的快,所以没有选择走索引 i_a
既然数据太少,我们就多造点数据,运行 data-init 下的 RangeAccessTest.java 中的 batchAddData 方法就好,轻轻松松 10W 到手! 此时执行计划如下

讲 BKA 之前了,我们不得不先看下 MRR,它是 BKA 的重要支柱。
全称 Multi-Range Read ,是对多行 IO 查询进行优化的一种策略,详情可看 MySQL 的 mrr-optimization 或者 MariaDB 的 Multi Range Read Optimization(MySQL 和 MariaDB 是什么关系? 呃,这么说吧,他们是一个爹的儿子)。简单点来说,MRR 是优化器将随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销的一种手段
什么是读盘与落盘(IO)?
当前绝大多少情况下,MySQL 的数据是存在机械硬盘(SATA 盘)上的,极少数情况下是存在固态硬盘(SSD)上的;读盘指的是从磁盘读取数据的过程,落盘指的是从内存持久化到磁盘的过程
为什么顺序读盘比随机读盘快?
这不是绝对的,多数情况下是这样的;至于为什么,这涉及到机械硬盘的硬件知识了,包括其组织结构,以及磁盘的读盘过程,另外还需要了解 MySQL 数据的落盘与读盘(页为单位),内容太多,就不在本篇讲了。
1. 使用场景
不是任何情况下 MySQL 都会使用 MRR 的,只是在某些情况下会用 MRR 来进行优化。
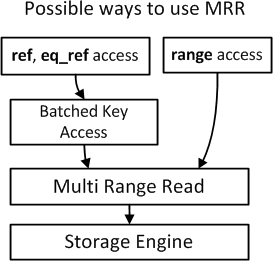
摘自 Multi Range Read Optimization
MySQL 中的 NDB 也会用到 MRR,一般而言,我们无需关注,我们只关注上图中的情况就行了。理论之后来点案例,完美!
2. range access
表 tbl_range_access 的 a 字段上我们已经建了索引 i_a ,我们来个范围查询,看下执行计划 EXPLAIN SELECT * FROM tbl_range_access WHERE a BETWEEN 4 AND 9; 如下

此时没有用到 MRR,执行此查询时,磁盘 IO 访问模式将遵循下图中的红线
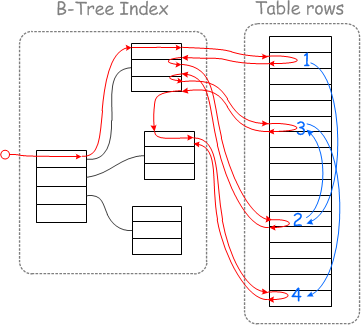
因为是 SELECT * ,所以通过索引 i_a 先找到主键 ID,然后通过主键 ID 回表(从聚簇索引)查询完整记录;a 在索引 i_a 中是有序的,但不保证主键在 i_a 中也是有序的(关于 MySQL 的索引,推荐大家去看:MySQL的索引),这就导致回表的过程是随机 IO
为什么 MySQL 没有采用 MRR 来保证回表的过程是顺序 IO 呢?
mrr-optimization 中有这么一段话:
Two optimizer_switch system variable flags provide an interface to the use of MRR optimization. The mrr flag controls whether MRR is enabled. If mrr is enabled (on), the mrr_cost_based flag controls whether the optimizer attempts to make a cost-based choice between using and not using MRR (on) or uses MRR whenever possible (off). By default, mrr is on and mrr_cost_based is on
mrr 和 mrr_cost_based 的默认值是 on ;我简单画个图,大家就明白这两个开关的作用了
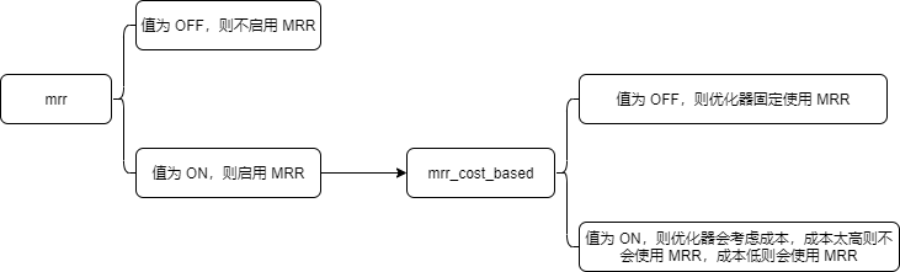
上面的示例之所以没使用 MRR,是优化器觉得使用 MRR 反而提升了成本,还不如不使用。
我们强制优化器使用 MRR:
-- 查看所有开关及其默认值
SELECT @@optimizer_switch;
-- mrr_cost_based设置成off,强制优化器使用
mrr SET optimizer_switch='mrr_cost_based=off';我们再来看看执行计划是什么样的

此时用到 MRR,执行此查询时,磁盘 IO 访问模式将遵循下图中的红线
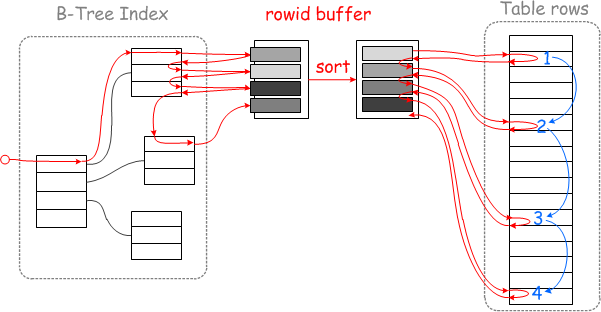
此时回表查询的主键是有序的,会采用顺序 IO 来读取数据,从而提高查询效率。
MySQL 中有个 rowids_buffer,用来缓存从索引 i_a 中查询到的数据记录(包含字段 a 和主键 ID),缓存满了或者索引查完了,再对缓存中记录按照主键 id 进行排序,再用排序后的主键 id 进行回表,使得回表查询的过程是顺序 IO
是不是感觉 MRR 有点像二级索引与主键的 JOIN 操作,有这感觉就对了,后面的 BKA 也就好理解了
BKA 全称是:Batched Key Access ,是对INL优化后的一种联表算法,类似与 BNL 对 SNL 的优化,但又有些不同,具体我们往下看
先在表 tbl_user 新增一个索引 ALTER TABLE tbl_user ADD index i_aaa(user_name); ,此时查看执行计划 EXPLAIN SELECT * FROM tbl_user_login_log tl LEFT JOINtbl_user tu ON tl.user_name = tu.user_name; 如下图

此时的联表算法就是 INL,因为表 tbl_user_login_log 的 user_name 是无索引的,那么从表 tbl_user_login_log 取出的 user_name 的值就是无序的,再去关联 tbl_user ,就会随机匹配索引 i_aaa ,类似下图
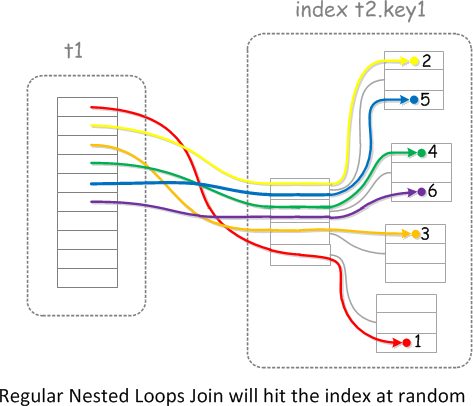
是不是有点类似于前面讲过的回表随机 IO ?
BKA 功能默认是关闭的( batched_key_access=off ),开启它
SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';我们再来看执行计划

从tbl_user_login_log 查询到的 user_name 的值先放到 join buffer,当 join buffer 满了或者数据查完了,再对 join buffer 里面的值进行排序,然后再去关联 tbl_user ,此时就会顺序匹配索引 i_aaa ,类似下图
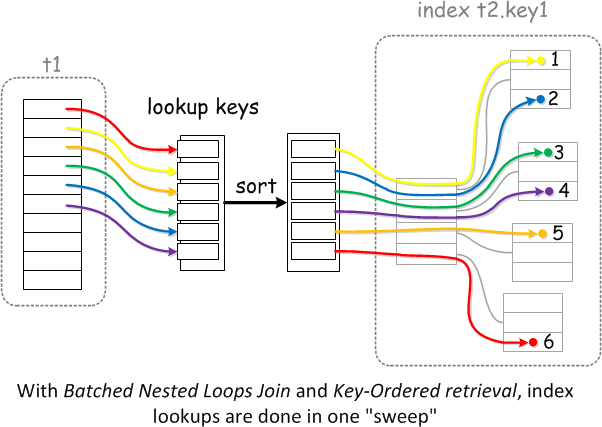
如果需要回表,那么 MySQL 会按之前讲到过的回表流程再优化一次
MRR 相关的 3 个开关的默认值是这样的 mrr=on,mrr_cost_based=on,batched_key_access=off
mrr=on 表示 mrr 功能是开启的,开启并不代表一定会使用,但不开启则一定享受不到 mrr 带来的优化
mrr_cost_based=on 表示优化器会基于成本考虑来决定是否使用 mrr,使用 mrr 反而使成本变高,那为什么使用 mrr ?只有 mrr 确实是带来了效率上的提升,那么使用它才有意义,但是成本的计算又是优化器来完成的,而且是一个比较复杂的过程,一定能保证优化器的成本计算是准确的吗?100%准确肯定不敢保证,但经过这么多年的沉淀,绝大多数情况下,优化器的成本计算是准确的,所以 mrr_cost_based 建议就采用默认值 on ,由优化器来决定是否采用 mrr
batched_key_access=off 表示默认不启用 BKA,说实话,我没太理解这么做的意图;既然是否使用 mrr 交由优化器来决定了,没什么不把是否使用 BKA 也交由优化器来决定?我能猜到的可能原因之一是基本用不到 ,为什么这么说? 我们回想下 BKA 会在什么情况下使用: 驱动表在关联的字段上无索引,而被驱动表在关联的字段上有索引 ,而如果驱动表在关联的字段上有索引了,还有必要进行缓存、排序、再关联被驱动表吗 ? 很显然不必了,因为索引的字段本来就是有序的了;而实际应用中,关联的字段,不管是驱动表还是被驱动表,往往是同时存在索引的,而不是一个存在索引而另一个不存在索引。这只是我个人的猜想,望知道的大神能解惑下,小弟不胜感激!
mrr 带来的性能上的提升就是将随机 IO 优化成 顺序 IO,从而提高查询效率
mrr 的使用场景比较有限, range access 和基于 req、eq_ref access 的 BKA,至于其他不适用的场景,我们可以结合 mrr 的特性分析出原因
mrr 相关的 3 个开关的默认值不建议改动,这可是 MySQL 这么多年的经验总结
作者:青石路
来源:博客园
本文为转发分享,转载请联系原作者授权
最后给大家分享我写的SQL两件套:《SQL基础知识第二版》和《SQL高级知识第二版》的PDF电子版。里面有各个语法的解释、大量的实例讲解和批注等等,非常通俗易懂,方便大家跟着一起来实操。
有需要的读者可以下载学习,在下面的公众号「数据前线」(非本号)后台回复关键字:SQL,就行
数据前线

后台回复关键字:1024,获取一份精心整理的技术干货
后台回复关键字:进群,带你进入高手如云的交流群。
推荐阅读