
OpenAI 推出网络爬虫 GPTBot,引发网站抵御潮:信息被爬走就很可能意味着永远无法删除

大数据文摘受权转载自AI前线
编译 | 核子可乐、Tina
不爬取你的页面数据,哪来几十亿美元的运营收入?
OpenAI 在没有正式宣布的情况下,于本周发布了一项网站爬虫规范。
网络爬虫通常用于扫描网站内容以训练其大型语言模型 (LLM),OpenAI 在一篇新的博客文章中表示:“使用 GPTBot 用户代理抓取的网页可能会用于改进未来的模型”,特别是 GPT-4 和潜在的 GPT-5。

在此之前,OpenAI 刚提交了“GPT-5”商标申请。三周之后,该公司推出了新的爬虫以及使用规范。OpenAI 在博文中表示,内容发布者和网站所有者可以据此拒绝为其提供素材。
网站需要加强防御
目前还不清楚 OpenAI 的爬虫在网上潜伏了多久,尽管有些人怀疑 OpenAI 可能已经有一个机器人在数月或数年时间里一直在秘密收集每个人的在线数据。现在该公司宣布了一种阻止 GPTBot 的方法,最新发布的技术文档描述了如何通过用户代理令牌和字符串来识别 OpenAI 的网络爬虫 GPTBot。在发送至服务器进行网页请求的 HTTP 标头中,OpenAI 公司的软件会明确使用这些令牌与字符串。
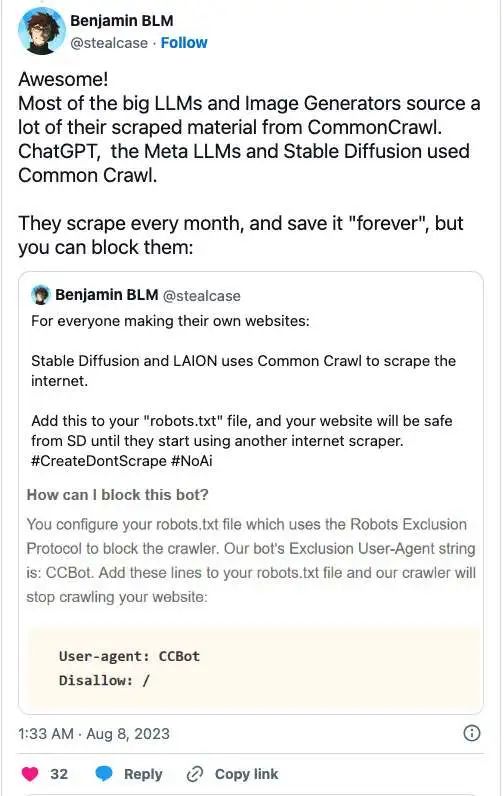
因此,内容发布者可以在自己 Web 服务器的 robots.txt 文件中添加新条目,告知爬虫可以做什么、不能做什么。当然,这是假设 GPTBot 会老老实实遵守机器人排除协议,毕竟也有不少机器人会对规则熟视无睹。例如,以下 robts.txt 键 / 值对就会指示 GPTBot 远离 root 目录和网站上的其他全部内容。
User-agent: GPTBotDisallow: /
对此,搜索引擎优化顾问 Prasad Dhumal 本周在 Twitter 上写道:“最后,在吸收了所有受版权保护的内容来构建他们的专有产品之后,OpenAI 为你提供了一种方法来防止你的内容被用来进一步改进他们的产品。”
另外,值得注意的是,一旦被大模型爬虫爬取,也意味着你的数据无法从公共数据集中删除。例如比较有名的公共数据集 Common Crawl,常被用于训练 OpenAI 的 ChatGPT、谷歌的 Bard 或 Meta 的 LLaMA ,专家表示,如果你的数据或内容被爬取进去,那意味着它永久成为了该训练集的一部分。但 CommonCrawl 等服务确实允许类似的 robots.txt ,但网站所有者需要在数据被收集之前实施这些更改。
然而,OpenAI 坚称开放网站数据收集入口,能够帮助该公司提高 AI 模型的实际质量,而且爬取的内容也不会涉及敏感信息。这话似乎可信,毕竟 OpenAI 和微软最近已经因此而官司缠身。
这家机器学习超级实验室在文档中指出,“使用 GPTBot 用户代理爬取的网页,可能会被用于改进未来模型,且付费专区、已知涉及个人身份信息(PII)或包含违反我们政策的文本来源均会被过滤删除。”
文档还提到,“允许 GPTBot 访问您的网站,可以帮助 AI 模型更加准确并提高其总体功能性与安全性。”
这人人为我、我为人人的口号一讲,似乎帮 OpenAI 节约时间和成本,使其模型能力更强、风险更低是件利他又利己的大好事。
可即便 OpenAI 承诺了自己在利用公共互联网数据训练大语言模型,仍有不少组织在努力限制自家信息通过网络被自动访问。毕竟 AI 软件厂商最喜欢借助网络上的各种信息为己所为,并借此建立起价值百万甚至数十亿美元的商业体系。所以部分企业已经采取行动,如果盈利一方不愿意拿出点分红,那他们就干脆关闭访问权限。
例如,Reddit 最近就修改了 API 条款,想更好地通过用户免费发布的内容获利。Twitter 日前也起诉了四家身份不明的实体,拒绝抓取其网站数据用于 AI 训练的行为。
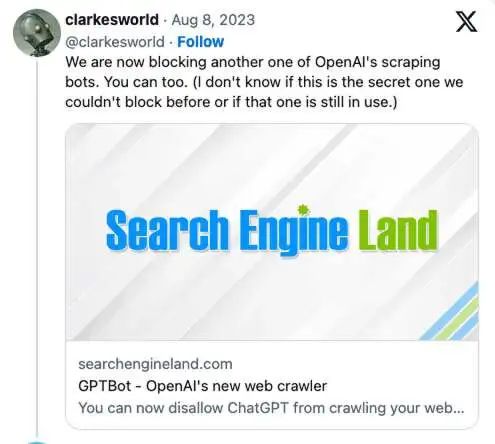
一些网站已经在加强对 GPTBot 的防御,比如外媒 The Verge 就已经添加了 robots.txt 标志,以阻止 OpenAI 模型抓取内容以添加到其大模型中。substack 博主 Casey Newton 也向他的读者询问是否应该阻止 OpenAI 收集他的内容。科幻杂志 Clarkesworld 的编辑 Neil Clarke 在 Twitter 上宣布将屏蔽 GPTBot。
建立合法路径才是正途!
OpenAI 没有立即回应,此次为什么要发布关于 GPTBot 的详细信息。但最近已经有多次针对该公司的诉讼,指控其未经客户许可而擅自使用可公开访问的数据 / 违反网站规定的许可条款。看来这两件事之间应该存在联系。
除了隐私诉讼之外,OpenAI、微软和微软子公司 GitHub 去年 11 月还因涉嫌利用受许可证保护的源代码训练 OpenAI 的 Codex 模型,并因在 GitHub Copilot 代码辅助服务中照搬这些代码而面临起诉。另有多位作家在上个月提起类似诉讼,指控 OpenAI 在未经许可的情况下利用他们的作品训练 ChatGPT。
谷歌、DeepMind 及其母公司 Alphabet 也未能幸免,同样因类似理由沦为被告。
考虑到爬取公共数据并借此训练 AI 模型所带来的法律不确定性,OpenAI 的竞争对手谷歌上个月提议重新设计爬虫协议的运作方式,尽量消弭愈演愈烈的数据归属权纠纷。
专为医疗保健行业提供 AI 助手的 Hyro 公司联合创始人兼 CEO Israel Krush 在采访中表示,目前网络爬虫的运作方式主要存在两个核心问题。
“首先就是默认发布者同意,对方如果不希望自己的网站成为爬取对象、信息被用于模型微调,只能主动选择拒绝。这个过程跟搜索引擎的运作方式存在很大区别,搜索引擎在爬取时只会引导用户访问内容发布网站的内容摘要。”
“而在 OpenAI 和 AI 助手这边,内容本体成为产品的直接组成部分,这样问题的性质就完全不同了。发布者必须主动拒绝才能免受爬取也着实引起了巨大的不满。”
Krush 表示,将爬取到的内容集成至他人产品中、甚至受到篡改,则可能引发另一个潜在问题。“第二个问题是,OpenAI 在声明中称将排除「以使用个人身份信息(PII)闻名的相关网站」,这样的表述有点令人费解。”
“以新闻出版商为例:他们的内容中肯定会存在某些身份识别信息。另外,即使那些似乎跟个人身份信息关系不大的网站,也或多或少涉及相关内容。而任何包含个人身份信息的内容都需要经过适当编辑。”
Krush 认为,模型的合规性问题和负责任立场需要匹配更强有力的保障措施,并强调他自己的公司就只会在获得明确许可时才爬取数据,且保证一切个人信息都得到妥善处理。
他总结道,“OpenAI 不该只关注那些被标记为包含个人身份信息的网站,而应当假设所有网站都可能涉及个人隐私,特别是各内容发布平台。他们应当采取积极主动的措施,确保爬取的信息不违反合规性要求。”
参考链接:
https://platform.openai.com/docs/gptbot
https://twitter.com/prasaddhumal_/status/1688517769158160384?s=20
https://twitter.com/stealcase/status/1688604248974475264
https://www.theregister.com/2023/08/08/openai_scraping_software/?td=rt-9cp
https://venturebeat.com/ai/capital-one-emphasizes-the-power-of-human-centered-design-at-vb-transform-2023/

点「在看」的人都变好看了哦!