
一文搞懂Hive的数据存储与压缩
行存储与列存储
行存储的特点
列存储的特点
常见的数据格式
TextFile
SequenceFile
RCfile
ORCfile
Parquet
测试
准备测试数据
存储空间大小
测试SQL 执行效率
总结
Hive 压缩
Hive中间数据压缩
最终输出结果压缩
常见的压缩格式
演示
总结
行存储与列存储
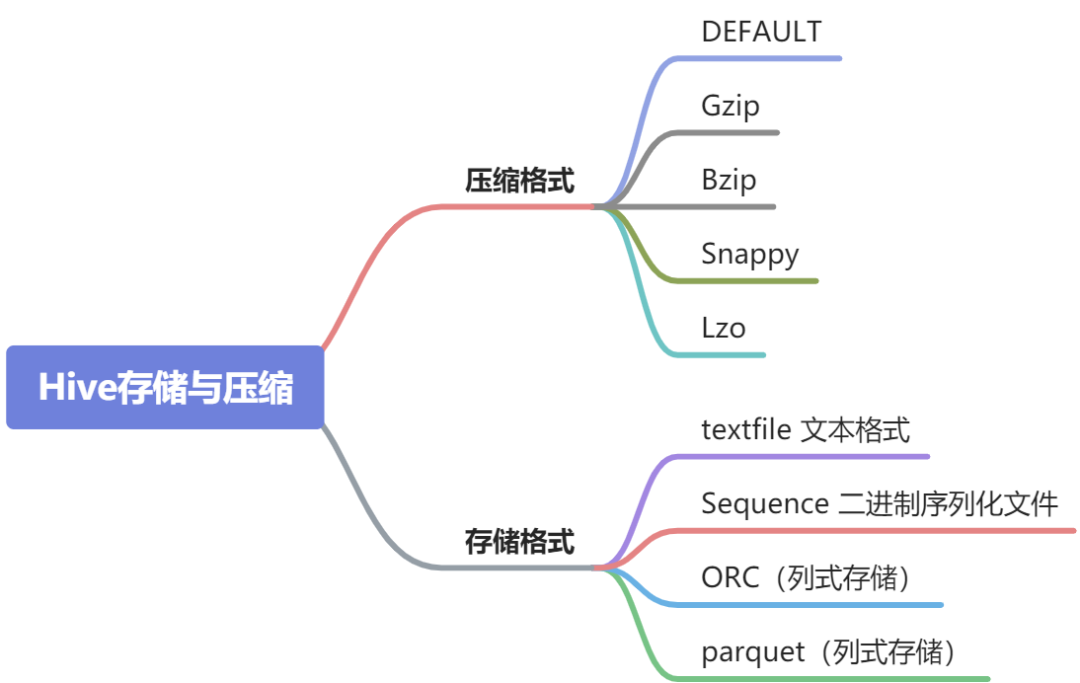
当今的数据处理大致可分为两大类,联机事务处理 OLTP(on-line transaction processing)联机分析处理 OLAP(On-Line Analytical Processing)=,OLTP 是传统关系型数据库的主要应用来执行一些基本的、日常的事务处理比如数据库记录的增、删、改、查等等而OLAP则是分布式数据库的主要应用它对实时性要求不高,但处理的数据量大通常应用于复杂的动态报表系统上
所以一般OLTP 都是使用行式存储的,因为实时性要求高,而且有大量的更新操作,OLAP 都是使用列式存储的,因为实时性要求不高,主要是要求性能好
行存储的特点
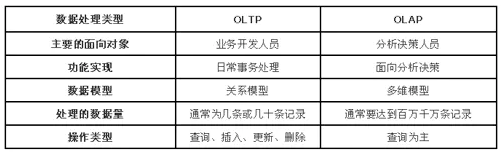
查询满足条件的一整行数据的时,只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。 传统的关系型数据库,如 Oracle、DB2、MySQL、SQL SERVER 等采用行式存储法(Row-based),在基于行式存储的数据库中, 数据是按照行数据为基础逻辑存储单元进行存储的, 一行中的数据在存储介质中以连续存储形式存在。 TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的 这种存储格式比较方便进行INSERT/UPDATE操作,不足之处就是如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。当然数据比较少,一般没啥问题,如果数据量比较大就比较影响性能,还有就是由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,也就是空间利用率不高
列存储的特点
查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询,在查询只需要少数几个字段的时候,能大大减少读取的数据量;因为每一列的数据都是存储在一起的,每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法,高效的压缩率,不仅节省储存空间也节省计算内存和CPU
不足之处是INSERT/UPDATE很麻烦或者不方便,不适合扫描小量的数据
列式存储(Column-based)是相对于行式存储来说的,新兴的Hbase、HPVertica、EMCGreenplum等分布式数据库均采用列式存储。在基于列式存储的数据库中, 数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。
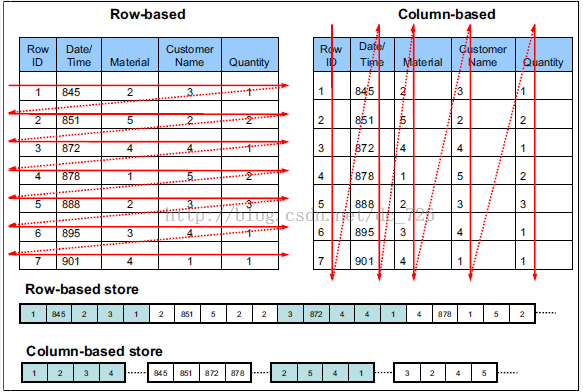
列存储的特点:因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。ORC和PARQUET是基于列式存储的。
举个例子吧不然还是太抽象,假设一个表有10亿行数据,按照列式存储的定义,应该先将某个字段的10亿条数据存储完之后,再存储其他字段。
常见的数据格式
Hive 支持一下几种存储格式,下面我们会对每种格式的特点进行简单介绍
Text File SequenceFile RCFile Avro Files ORC Files Parquet Custom INPUTFORMAT and OUTPUTFORMAT(用户自定义格式)
Hive 默认使用的实Text File,也就是说当你建表的时候不指定文件的存储格式的时候,它就使用的就是Text File,Hive 是支持指定默认存储格式的
<property>
<name>hive.default.fileformat</name>
<value>TextFile</value>
<description>
Expects one of [textfile, sequencefile, rcfile, orc, parquet].
Default file format for CREATE TABLE statement. Users can explicitly override it by CREATE TABLE ... STORED AS [FORMAT]
</description>
</property>
TextFile
存储方式:行存储
默认的存储格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。
并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。
压缩数据文件可以节省磁盘空间,但Hadoop中有些原生压缩文件的就是不支持分割,所以Hadoop 猜提供了SequenceFile 这种格式,支持分割的文件可以并行的有多个mapper程序处理大数据文件,大多数文件不支持可分割是因为这些文件只能从头开始读。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩,RECORD是默认选项,通常BLOCK会带来较RECORD更好的压缩性能。
SequenceFile的优势是文件和hadoop api中的MapFile是相互兼容的。
注:建表使用这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。SequenceFile、RCFile、ORC格式的表不能直接从本地文件导入数据,数据要先导入到TextFile格式的表中,然后再从TextFile表中用insert导入到SequenceFile、RCFile表中
RCfile
存储方式:数据按行分块,每块按列存储
Record Columnar的缩写,是Hadoop中第一个列式存储格式。能够很好的压缩和快速的查询性能,但是不支持模式演进。是一种行列存储相结合的存储方式。
首先,其将数据按行分块,保同一行的数据位于同一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取,并且能跳过不必要的列读取
ORCfile
存储方式:数据按行分块 每块按照列存储(不是真正意义上的列存储,可以理解为分段列存储,你可以对照我们讲的那个例子来理解)
ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。和Parquet类似,它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。
ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Spark SQL、Presto等查询引擎支持,但是Impala对于ORC目前没有支持,仍然使用Parquet作为主要的列式存储格式。2015年ORC项目被Apache项目基金会提升为Apache顶级项目。
ORC文件特点是压缩快 快速列存取,是rcfile的改良版本,相比RC能够更好的压缩,能够更快的查询,支持各种复杂的数据类型,比如datetime,decimal,以及复杂的struct是以二进制方式存储的,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。
需要注意的是 ORC在读写时候需要消耗额外的CPU资源来压缩和解压缩,当然这部分的CPU消耗是非常少的。
格式
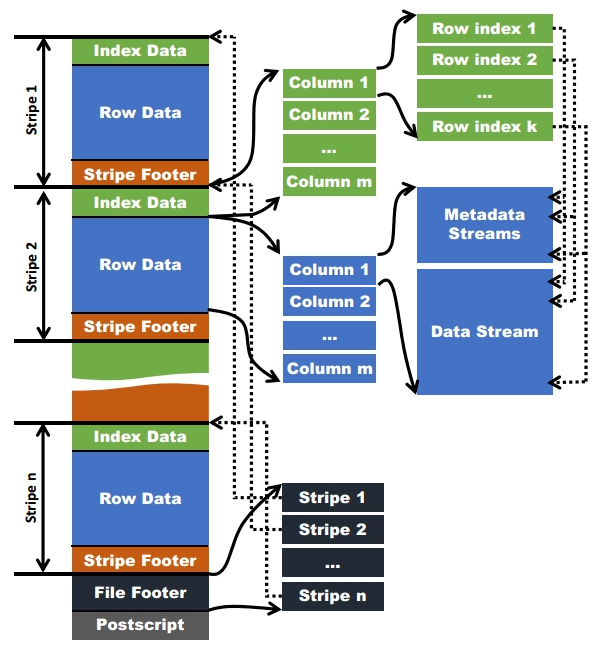
ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中就是row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer;
stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
文件级元数据:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息)、所有stripe的信息和文件schema信息。
stripe元数据:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
在ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别的,他们都可以用来根据Search ARGuments(谓词下推条件)判断是否可以跳过某些数据,在统计信息中都包含成员数和是否有null值,并且对于不同类型的数据设置一些特定的统计信息。
file level:在ORC文件的末尾会记录文件级别的统计信息,会记录整个文件中columns的统计信息。这些信息主要用于查询的优化,也可以为一些简单的聚合查询比如max, min, sum输出结果。
**stripe level:**ORC文件会保存每个字段stripe级别的统计信息,ORC reader使用这些统计信息来确定对于一个查询语句来说,需要读入哪些stripe中的记录。比如说某个stripe的字段max(a)=10,min(a)=3,那么当where条件为a >10或者a <3时,那么这个stripe中的所有记录在查询语句执行时不会被读入
row level: 为了进一步的避免读入不必要的数据,在逻辑上将一个column的index以一个给定的值(默认为10000,可由参数配置)分割为多个index组。以10000条记录为一个组,对数据进行统计。Hive查询引擎会将where条件中的约束传递给ORC reader,这些reader根据组级别的统计信息,过滤掉不必要的数据。如果该值设置的太小,就会保存更多的统计信息,用户需要根据自己数据的特点权衡一个合理的值
数据访问
读取ORC文件是从尾部开始的,第一次读取16KB的大小,尽可能的将Postscript和Footer数据都读入内存。文件的最后一个字节保存着PostScript的长度,它的长度不会超过256字节,PostScript中保存着整个文件的元数据信息,它包括文件的压缩格式、文件内部每一个压缩块的最大长度(每次分配内存的大小)、Footer长度,以及一些版本信息。在Postscript和Footer之间存储着整个文件的统计信息(上图中未画出),这部分的统计信息包括每一个stripe中每一列的信息,主要统计成员数、最大值、最小值、是否有空值等。
接下来读取文件的Footer信息,它包含了每一个stripe的长度和偏移量,该文件的schema信息(将schema树按照schema中的编号保存在数组中)、整个文件的统计信息以及每一个row group的行数。
处理stripe时首先从Footer中获取每一个stripe的其实位置和长度、每一个stripe的Footer数据(元数据,记录了index和data的的长度),整个striper被分为index和data两部分,stripe内部是按照row group进行分块的(每一个row group中多少条记录在文件的Footer中存储),row group内部按列存储。每一个row group由多个stream保存数据和索引信息。每一个stream的数据会根据该列的类型使用特定的压缩算法保存。在ORC中存在如下几种stream类型:
PRESENT:每一个成员值在这个stream中保持一位(bit)用于标示该值是否为NULL,通过它可以只记录部位NULL的值 DATA:该列的中属于当前stripe的成员值。 LENGTH:每一个成员的长度,这个是针对string类型的列才有的。 DICTIONARY_DATA:对string类型数据编码之后字典的内容。 SECONDARY:存储Decimal、timestamp类型的小数或者纳秒数等。 ROW_INDEX:保存stripe中每一个row group的统计信息和每一个row group起始位置信息。
在初始化阶段获取全部的元数据之后,可以通过includes数组指定需要读取的列编号,它是一个boolean数组,如果不指定则读取全部的列,还可以通过传递SearchArgument参数指定过滤条件,根据元数据首先读取每一个stripe中的index信息,然后根据index中统计信息以及SearchArgument参数确定需要读取的row group编号,再根据includes数据决定需要从这些row group中读取的列,通过这两层的过滤需要读取的数据只是整个stripe多个小段的区间,然后ORC会尽可能合并多个离散的区间尽可能的减少I/O次数。然后再根据index中保存的下一个row group的位置信息调至该stripe中第一个需要读取的row group中。
使用ORC文件格式时,用户可以使用HDFS的每一个block存储ORC文件的一个stripe。对于一个ORC文件来说,stripe的大小一般需要设置得比HDFS的block小,如果不这样的话,一个stripe就会分别在HDFS的多个block上,当读取这种数据时就会发生远程读数据的行为。如果设置stripe的只保存在一个block上的话,如果当前block上的剩余空间不足以存储下一个strpie,ORC的writer接下来会将数据打散保存在block剩余的空间上,直到这个block存满为止。这样,下一个stripe又会从下一个block开始存储。
由于ORC中使用了更加精确的索引信息,使得在读取数据时可以指定从任意一行开始读取,更细粒度的统计信息使得读取ORC文件跳过整个row group,ORC默认会对任何一块数据和索引信息使用ZLIB压缩,因此ORC文件占用的存储空间也更小
Parquet
Parquet能够很好的压缩,有很好的查询性能,支持有限的模式演进。但是写速度通常比较慢。这中文件格式主要是用在Cloudera Impala上面的。Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
Parquet的设计方案,整体来看,基本照搬了Dremel中对嵌套数据结构的打平和重构算法,通过高效的数据打平和重建算法,实现按列存储(列组),进而对列数据引入更具针对性的编码和压缩方案,来降低存储代价,提升计算性能。想要了解这一算法逻辑的,可以看Dremel的论文:Dremel: Interactive Analysis of WebScaleDatasets
测试
准备测试数据
首先我们生成一份测试数据,这是生成数据的测试代码
public class ProduceTestData {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-mm-dd HH:MM:ss");
@Test
public void testRandomName() throws IOException {
Faker faker = new Faker(Locale.CHINA);
final Name name = faker.name();
final Address address = faker.address();
Number number = faker.number();
PhoneNumber phoneNumber = faker.phoneNumber();
BufferedWriter out = new BufferedWriter(new FileWriter("/Users/liuwenqiang/access.log"));
int num=0;
while (num<10000000){
int id = number.randomDigitNotZero();
String userName = name.name();
String time = simpleDateFormat.format(new Date(System.currentTimeMillis()));
String city = address.city();
String phonenum = phoneNumber.cellPhone();
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(id);
stringBuilder.append("\t");
stringBuilder.append(userName);
stringBuilder.append("\t");
stringBuilder.append(city);
stringBuilder.append("\t");
stringBuilder.append(phonenum);
stringBuilder.append("\t");
stringBuilder.append(time);
out.write(stringBuilder.toString());
out.newLine();
}
out.flush();
out.close();
}
}
下面准备三张表,分别是log_text、log_orc和log_parquet
create table log_text(
id int,
name string,
city string,
phone string,
acctime string)
row format delimited fields terminated by '\t'
stored as textfile;
LOAD DATA LOCAL INPATH '/Users/liuwenqiang/access.log' OVERWRITE INTO TABLE ods.log_text;
create table log_orc(
id int,
name string,
city string,
phone string,
acctime string)
row format delimited fields terminated by '\t'
stored as orc;
insert overwrite table ods.log_orc select * from ods.log_text;
create table log_parquet(
id int,
name string,
city string,
phone string,
acctime string)
row format delimited fields terminated by '\t'
stored as parquet;
insert overwrite table ods.log_parquet select * from ods.log_text;
所有关于ORCFile的参数都是在Hive SQL语句的TBLPROPERTIES字段里面出现
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
存储空间大小
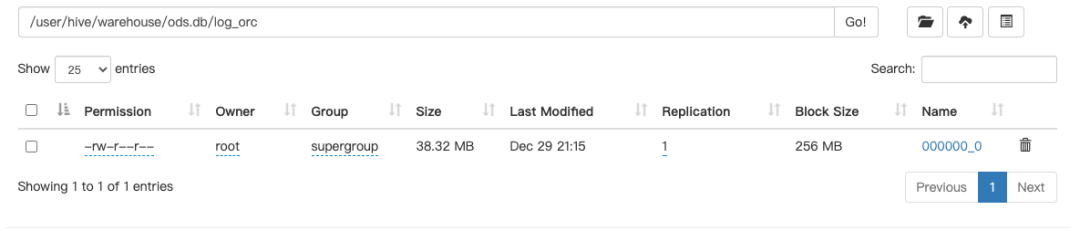
text
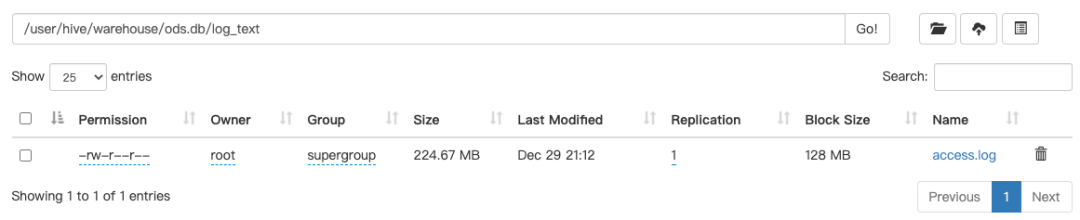
orc
parquet

测试SQL 执行效率
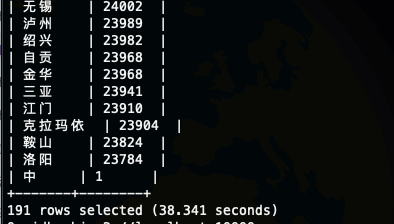
测试SQL select city,count(1) as cnt from log_text group by city order by cnt desc;
text
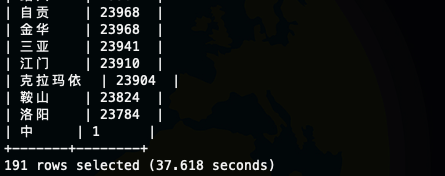
orc
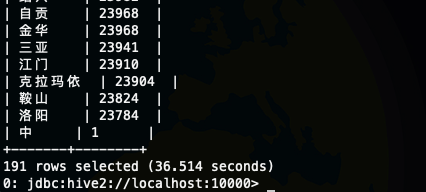
parquet
总结
介绍了行式存储和列式存储的特点,以及适用场景 介绍了Hive 常见的存储格式,Parquet 和 ORC都是二进制存储的,都是不可直接读取的,Parquet和ORC 都是Apache 顶级项目,Parquet不支持ACID 不支持更新,ORC支持有限的ACID 和 更新 我们简单对比了一下Text、ORCfile 和Parquet的存储占用和查询性能,因为我们的查询比较简单加上数据本身不是很大,所以查询性能差异不是很大,但是占用空间存储的差异还是很大的
Hive 压缩
对于数据密集型任务,I/O操作和网络数据传输需要花费相当长的时间才能完成。通过在 Hive 中启用压缩功能,我们可以提高 Hive 查询的性能,并节省 HDFS 集群上的存储空间。
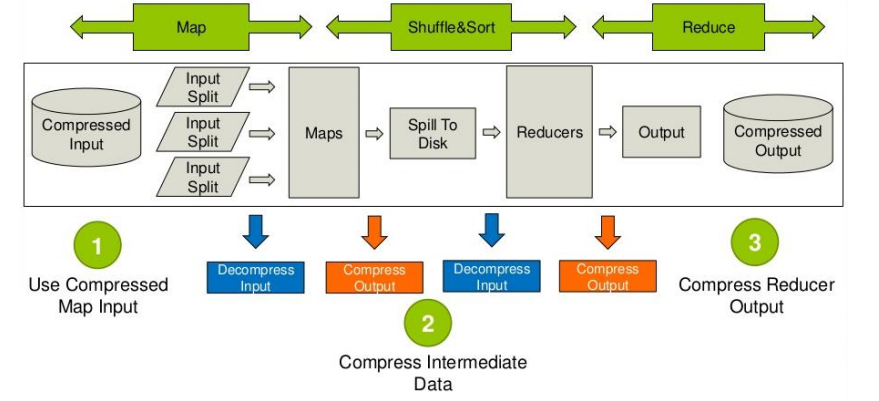
HiveQL语句最终都将转换成为hadoop中的MapReduce job,而MapReduce job可以有对处理的数据进行压缩。
首先说明mapreduce哪些过程可以设置压缩:需要分析处理的数据在进入map前可以压缩,然后解压处理,map处理完成后的输出可以压缩,这样可以减少网络I/O(reduce通常和map不在同一节点上),reduce拷贝压缩的数据后进行解压,处理完成后可以压缩存储在hdfs上,以减少磁盘占用量。
Hive中间数据压缩
提交后,一个复杂的 Hive 查询通常会转换为一系列多阶段 MapReduce 作业,这些作业将通过 Hive 引擎进行链接以完成整个查询。因此,这里的 ‘中间输出’ 是指前一个 MapReduce 作业的输出,将会作为下一个 MapReduce 作业的输入数据。
可以通过使用 Hive Shell 中的 set 命令或者修改 hive-site.xml 配置文件来修改 hive.exec.compress.intermediate 属性,这样我们就可以在 Hive Intermediate 输出上启用压缩。
hive.exec.compress.intermediate:默认为false,设置true为激活中间数据压缩功能,就是MapReduce的shuffle阶段对mapper产生中间压缩。可以使用 set 命令在 hive shell 中设置这些属性
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
或者
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec
也可以在配置文件中进行配置
<property>
<name>hive.exec.compress.intermediate</name>
<value>true</value>
<description>
This controls whether intermediate files produced by Hive between multiple map-reduce jobs are compressed.
The compression codec and other options are determined from Hadoop config variables mapred.output.compress*
</description>
</property>
<property>
<name>hive.intermediate.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description/>
</property>
最终输出结果压缩
hive.exec.compress.output:用户可以对最终生成的Hive表的数据通常也需要压缩。该参数控制这一功能的激活与禁用,设置为true来声明将结果文件进行压缩。
mapred.output.compression.codec:将hive.exec.compress.output参数设置成true后,然后选择一个合适的编解码器,如选择SnappyCodec。设置如下(两种压缩的编写方式是一样的):
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
或者
set mapred.output.compress=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.LzopCodec
同样可以通过配置文件配置
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
<description>
This controls whether the final outputs of a query (to a local/HDFS file or a Hive table) is compressed.
The compression codec and other options are determined from Hadoop config variables mapred.output.compress*
</description>
</property>
常见的压缩格式
Hive支持的压缩格式有bzip2、gzip、deflate、snappy、lzo等。Hive依赖Hadoop的压缩方法,所以Hadoop版本越高支持的压缩方法越多,可以在$HADOOP_HOME/conf/core-site.xml中进行配置:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec
</value>
</property>
<property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
需要注意的是在我们在hive配置开启压缩之前,我们需要配置让Hadoop 支持,因为hive 开启压缩只是指明了使用哪一种压缩算法,具体的配置还是需要在Hadoop 中配置
常见的压缩格式有:
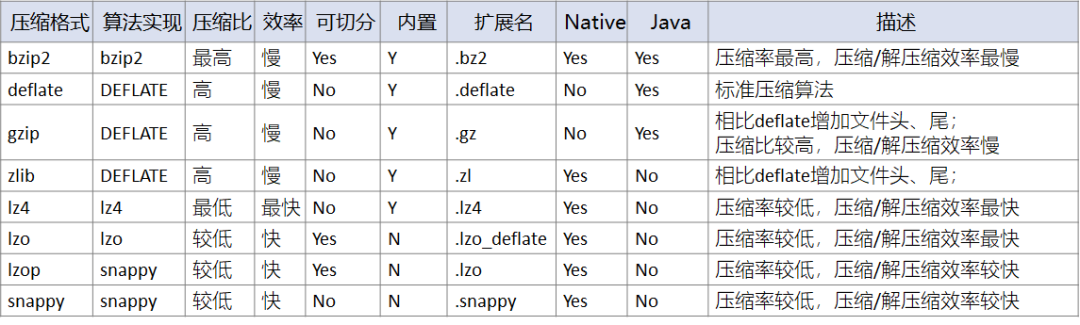
其中压缩比bzip2 > zlib > gzip > deflate > snappy > lzo > lz4,在不同的测试场景中,会有差异,这仅仅是一个大概的排名情况。bzip2、zlib、gzip、deflate可以保证最小的压缩,但在运算中过于消耗时间。
从压缩性能上来看:lz4 > lzo > snappy > deflate > gzip > bzip2,其中lz4、lzo、snappy压缩和解压缩速度快,压缩比低。
所以一般在生产环境中,经常会采用lz4、lzo、snappy压缩,以保证运算效率。
| 压缩格式 | 对应的编码/解码 |
|---|---|
| DEFAULT | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip | org.apache.hadoop.io.compress.BzipCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
| Lzo | org.apache.hadoop.io.compress.LzopCodec |
对于使用 Gzip or Bzip2 压缩的文件我们是可以直接导入到text 存储类型的表中的,hive 会自动帮我们完成数据的解压
CREATE TABLE raw (line STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
LOAD DATA LOCAL INPATH '/tmp/weblogs/20090603-access.log.gz' INTO TABLE raw;
Native Libraries
Hadoop由Java语言开发,所以压缩算法大多由Java实现;但有些压缩算法并不适合Java进行实现,会提供本地库Native Libraries补充支持。Native Libraries除了自带bzip2, lz4, snappy, zlib压缩方法外,还可以自定义安装需要的功能库(snappy、lzo等)进行扩展。而且使用本地库Native Libraries提供的压缩方式,性能上会有50%左右的提升。
使用命令可以查看native libraries的加载情况:
hadoop checknative -a

完成对Hive表的压缩,有两种方式:配置MapReduce压缩、开启Hive表压缩功能。因为Hive会将SQL作业转换为MapReduce任务,所以直接对MapReduce进行压缩配置,可以达到压缩目的;当然为了方便起见,Hive中的特定表支持压缩属性,自动完成压缩的功能。
Hive中的可用压缩编解码器
要在 Hive 中启用压缩,首先我们需要找出 Hadoop 集群上可用的压缩编解码器,我们可以使用下面的 set 命令列出可用的压缩编解码器。
hive> set io.compression.codecs;
io.compression.codecs=
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
演示
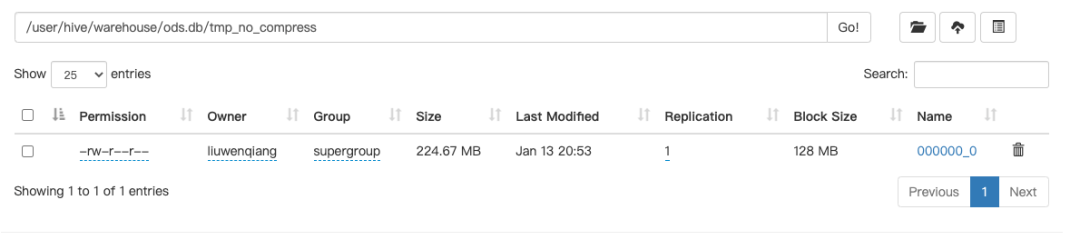
首先我们创建一个未经压缩的表tmp_no_compress
CREATE TABLE tmp_no_compress ROW FORMAT DELIMITED LINES TERMINATED BY '\n'
AS SELECT * FROM log_text;
我们看一下不设置压缩属性的输出
在 Hive Shell 中设置压缩属性:
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
根据现有表 tmp_order_id 创建一个压缩后的表 tmp_order_id_compress:
CREATE TABLE tmp_compress ROW FORMAT DELIMITED LINES TERMINATED BY '\n'
AS SELECT * FROM log_text;
我们在看一下设置压缩属性后输出:
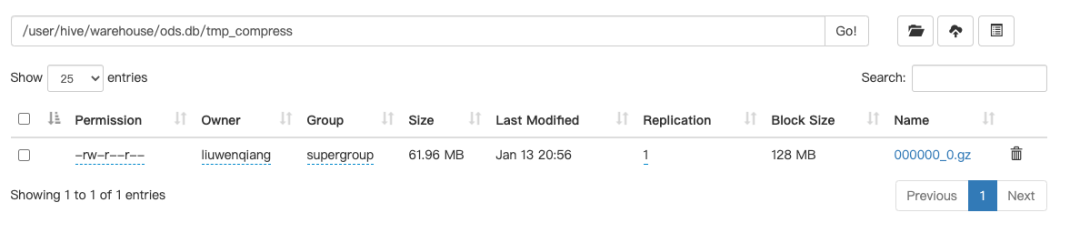
总结
数据压缩可以发生在哪些阶段 1 输入数据可以压缩后的数据 2 中间的数据可以压缩 3 输出的数据可以压缩 hive 仅仅是配置了开启压缩和使用哪种压缩方式,真正的配置是在hadoop 中配置的,而数据的压缩是在MapReduce 中发生的 对于数据密集型任务,I/O操作和网络数据传输需要花费相当长的时间才能完成。通过在 Hive 中启用压缩功能,我们可以提高 Hive 查询的性能,并节省 HDFS 集群上的存储空间。