
利用大规模轨迹数据提取城市内货车出行信息
Yitao Yang, Bin Jia*, Xiao-Yong Yan*, Rui Jiang, Hao Ji, Ziyou Gao. Identifying intracity freight trip ends from heavy truck GPS trajectories[J]. Transportation Research Part C: Emerging Technologies, 2022, 136: 103564.

1 内容导读
在上一期推送中,我们给大家介绍了城际出行OD的识别方法。在本期推送中,我们将给大家介绍城市内出行OD的识别。在城市货运中,重型卡车的运输活动通常以出行链的形式组织起来的,即重型卡车从一个常驻地点(可能为货运企业、物流仓库、工厂等)出发,为了不同的货运目的进行多次出行,最后返回这个常驻地点。在出行链中,重型卡车在常驻地点的停留时间较长,而在中间目的地停留的时间较短。此外,卡车的出行链模式在不同城市是复杂且多样的。我们先前提出的城际出行OD识别方法以两个时间阈值粗粒化地将停车点分为三类,并从中识别实际OD点。这种方法在复杂的城市环境下会导致很多错误识别的结果。
本文中,我们提出了一种时间阈值动态调整的出行OD识别方法。该方法客观地定义了识别停车点的速度阈值和区分临时停车点和出行OD点的多级时间阈值。在此基础上,结合重型卡车的城市活动模式,动态选择合适的级别的时间阈值。此外,我们利用城市道路网络和兴趣点(POI)数据剔除长时间停留的临时停车点,以提高方法的准确性。验证结果表明,该方法的准确度为88.79%。该方法考虑了城市货运环境对卡车轨迹特征的影响,其结果能够反映城市重型卡车出行的空间分布和出行链模式,具有广泛的实际应用价值。
2 数据描述

2.1 GPS轨迹数据
我们的GPS数据来源于中国道路货运监管与服务平台(https://www.gghypt.net/),该平台由中国政府主导搭建,主要用于交通部门监控重型卡车道路违法行为(超速驾驶、疲劳驾驶等)。我们的数据集中包含中国境内260万辆重型卡车,占全国总数的41%左右。数据时间跨度为从2018年5月18日到2018年5月24日,为期一周。GPS数据的平均采样率为30 s,数据记录超过200亿条,数据字段包括:卡车ID(加密后)、地理坐标、点速度、时间戳和行驶方向。Fig. 1a-d为中国北京、成都、上海和苏州四个城市重型卡车GPS轨迹的空间分布。
2.2 城市道路网络数据
本文以城市路网为基础数据,度量城市重型卡车行驶轨迹的迂回程度,剔除道路上的临时停车点。我们使用OSMnx一个用于下载OpenStreetMap街道网络数据的Python包来获取城市道路网络。获取的城市道路网数据集的坐标系为WGS-84。城市路网用有向图表示,其中边表示路段,节点表示交叉口。每条边的权重就是它的长度。根据不同城市的货运政策,人口密度高的中心地区往往被规定为重型卡车的限制区域(见Fig. 1e-h)。重型卡车在某些时间段是无法进入这些限制区的。因此,我们将限制区域内的路段移除,以建立多个不同时段重型货车可通行的路网。
2.3 货运相关的POI数据
我们使用高德地图(https://lbs.amap.com)的API抓取每个城市货运相关的POIs。在高德地图应用程序中,开发人员按行业类别以分层格式存储POI。根据POI与重型卡车货运活动的相关性,我们选择了企业、购物、日常生活服务、运输服务四个基本POI类别,如Table. 1所示。
3 研究方法
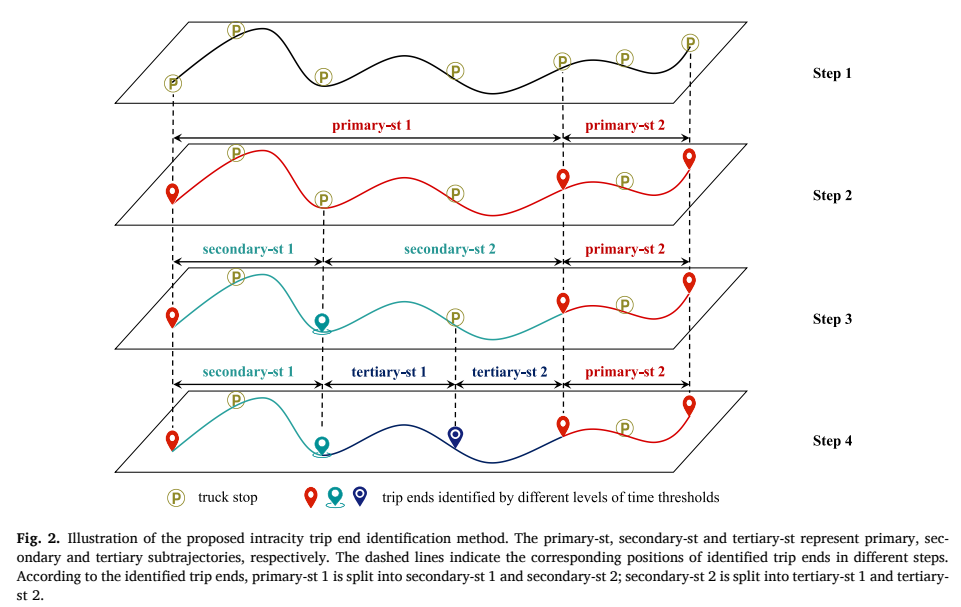
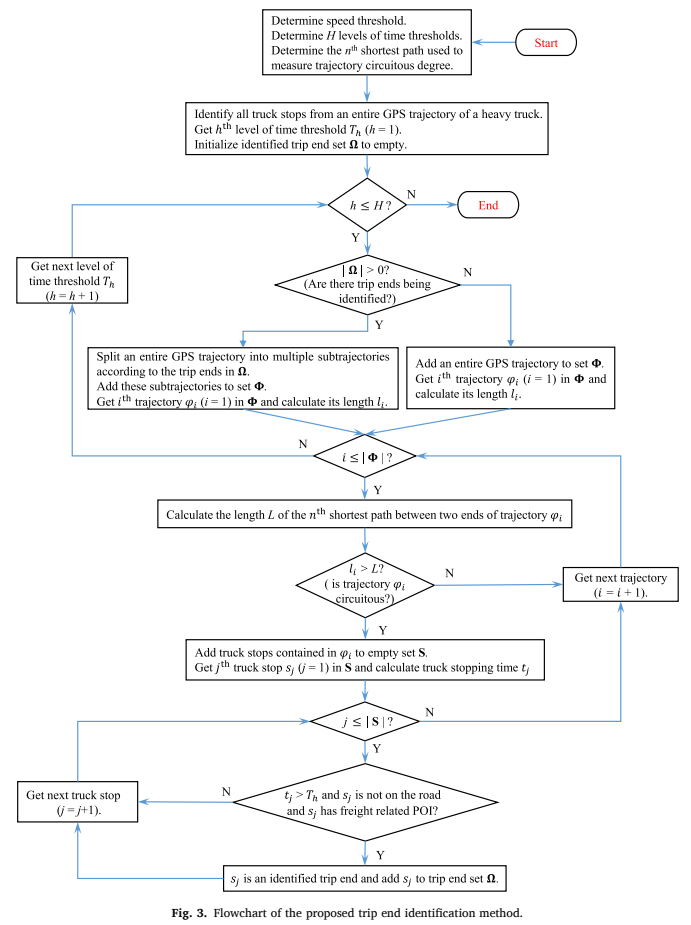
我们提出了一种数据驱动的方法,从每辆重型卡车整个GPS轨迹中识别其城市内出行OD点,见Fig. 2。首先,我们通过使用预先确定的速度阈值(见Fig. 2中的Step 1),从整个GPS轨迹中识别停车点。如果重型卡车的速度小于速度阈值,则认为它是静止的。其次,我们确定多级时间阈值,并根据卡车的最大停车时间选择合适的时间阈值,从这些停车点中识别可能的出行OD点。例如,如果第一级(最大)时间阈值小于该卡车的最大停车时间,则选择第一级时间阈值。否则,选择另一个较小的时间阈值,以确保可以识别出OD点。我们使用辅助数据,即货运相关的POI数据和城市路网数据,来判断每个出行OD是否被准确识别(见下文)。如果实际出行OD被识别出来,我们根据这些OD点将整个GPS轨迹分割成多段(见Fig. 2中的Step 2)。
我们将从整个GPS轨迹中分割出的轨迹段定义为一级子轨迹。接下来,我们确定每个一级子轨迹是否可能由多次出行组成。如果某段一级子轨迹的长度大于相应的第n条最短路径的长度,则该一级子轨迹显著迂回,那么它可能由多次出行组成。我们使用下一级较短的时间阈值和辅助数据,从每个迂回的一级子轨迹中识别潜在的OD点。如果识别出潜在的OD点,则将该一级子轨迹划分为多段。从一级子轨迹中分离出轨迹被定义为二级子轨迹(见Fig. 2中的Step 3)。上述过程不断迭代,直到所有的轨迹不能再被分割或时间阈值达到最小值时停止。算法流程图见Fig. 3。
3.1 从GPS轨迹中识别卡车停车点
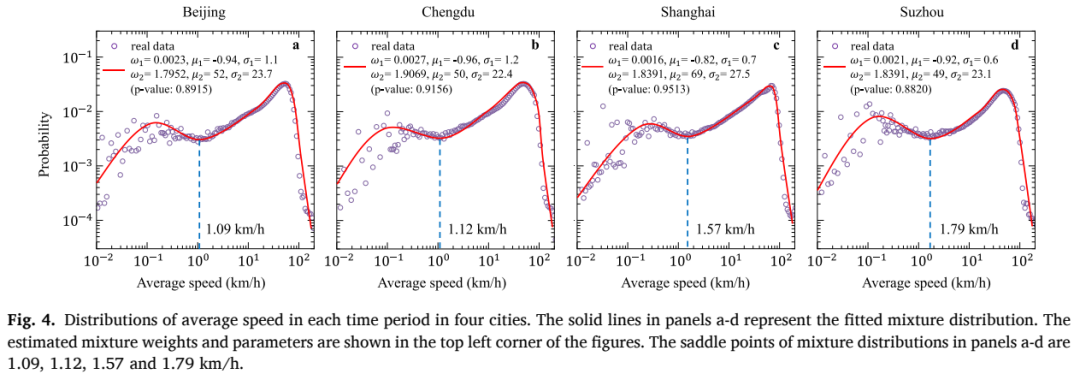
首先,我们计算每辆重型卡车GPS轨迹中连续两个GPS点的平均速度。其次,我们得到了一个城市中所有重型卡车平均速度的分布,见Fig. 4。在双对数轴上,这四个城市的平均速度分布呈现双峰分布。我们假设平均速度分布的右峰反映了重型卡车在道路上正常行驶时的速度特性。而平均速度分布的左峰主要由GPS漂移引起的。在本文中,我们使用混合分布来拟合城市重型卡车的平均速度数据,并将混合分布鞍点处的速度值定义为速度阈值,用于确定重型卡车是否停车。
在一个时间段内,如果一辆重型卡车的速度小于确定的速度阈值,则认为它是静止的。我们将多个连续静止时段的GPS点的中心作为识别的卡车停车点,如Fig. 5所示。卡车停车点的地理位置由这些静止GPS点经纬度的平均表示。

3.2 确定多级的时间阈值
我们使用了一种非参数迭代方法,名为Loubar方法确定多级时间阈值。以北京为例,我们首先使用第3.1节介绍的方法识别所有停车点。其次,我们按照停车时间由高到低的顺序对停车点进行排序,并计算排序后的停车点累计停车时间。最后,我们绘制停车时间的洛伦兹曲线,如Fig. 7a所示。洛伦兹曲线的曲率值表示数据分布的均衡程度。我们计算洛伦兹曲线在(1,1)处的切线与横轴的交点F*。归一化序数大于F*的长时间停车点分为第一类。将F*对应的停车时间确定为一级时间阈值,如Fig. 7a所示。接下来,我们将这些长时间停车点剔除,重新绘制剩余停车时间的洛伦兹曲线,计算出相应的F*,并确定下一级时间阈值,如Fig. 7b所示。重复上述过程(如Fig. 7c-g),直到达到均衡的数据分布,即洛伦兹曲线为直线,如Fig. 7h所示。最后确定了1,295 min、326 min、72 min、26 min、12 min、2 min和1 min 7个级别的时间阈值。

3.3 从迂回子轨迹中识别潜在的出行OD点
在出行OD识别过程中,首先根据卡车最大停车时间选择合适的时间阈值,从整个GPS轨迹中识别OD点,然后将该轨迹分解为多个子轨迹。每个子轨迹可以由一次出行或多次出行组成。接下来,我们需要识别可能由多个出行组成的子轨迹,然后使用更短的下一级时间阈值来识别潜在的出行OD点。在由多次出行组成的子轨迹中,重型卡车需要在不同的地点服务多个客户,因此其路径的迂回程度往往大于单次出行的路径。因此,我们需要度量卡车单次出行轨迹的迂回程度,并以此来判断一段轨迹是否由多次出行组成。
以北京市为例,首先,我们通过地理空间分析,从GPS轨迹中人工提取了近2000辆卡车的单次出行。由于一些装卸货地点具有显著的建筑特征,可以从卫星地图上识别。所以,我们可以进行地理空间分析,提取一些以这些地点为起点和终点的单次出行。其次,我们使用路段删除,生成从每次出行的起点到终点的K条最短路径,如Fig. 8所示。
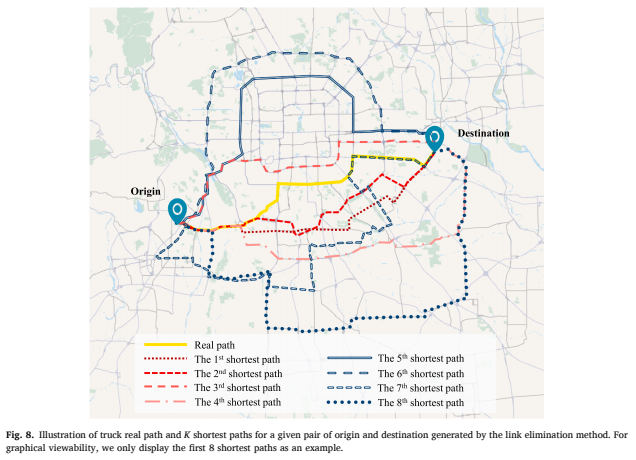
最后,我们使用Sørensen相似性指数找出长度与所有单次出行路径最接近的第n条最短路径。Fig. 9给出了北京市实际出行路径与对应的前8条最短路径的长度相似性度量结果。我们发现第3条最短路径(最大的SSI值和R2)适用于度量北京重型卡车单行出行路径的迂回程度。对于某个分割的子轨迹,我们从城市路网中生成从它起点到终点的第3条最短路径。如果该子轨迹的长度比对应的第3条最短路径长,则该子轨迹可以由多个出行组成。然后,我们使用下一级较短的时间阈值来识别该子轨迹中的潜在出行OD点。

4 结果与分析
4.1 城市内货运出行OD的空间分布
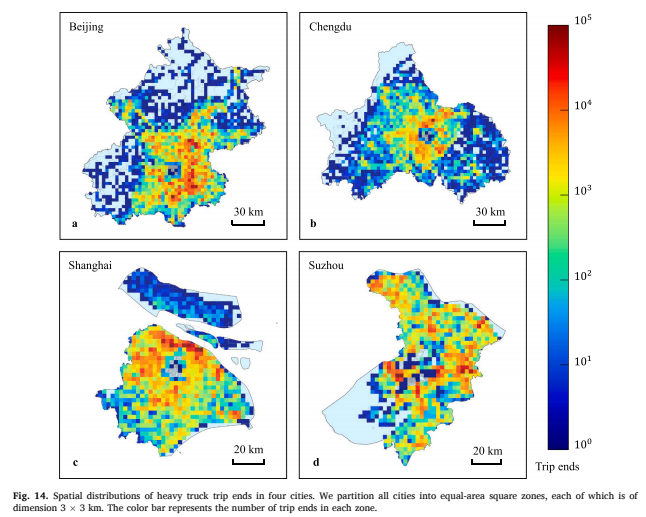
利用重型卡车出行OD的空间分布可以识别城市货运热点。Fig. 14展示了从我们的GPS数据集中识别的出行OD空间分布。我们可以看到,大多数识别的出行OD集中在郊区。如果研究人员的数据集包含城市中所有的重型卡车,那么城市的出行OD分布可以用于识别货运热点,并分析重型卡车货运活动的郊区化趋势。准确识别城市货运热点可以为城市管理者有效管理货运企业、监测环境污染和规划土地利用提供决策支持。
4.2 城市内货运出行的空间分布
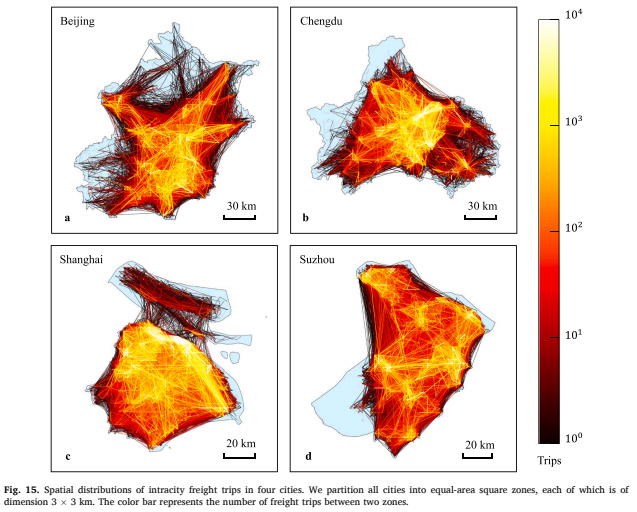
Fig. 15为4个城市内货运出行的空间分布。从城市规划和管理的角度,这些提取的货运出行可以用来分析城市区域之间的经济联系和货运交互强度,从而为货运政策制定提供参考。此外,如果所有重型卡车都安装GPS设备并进行监控,重型卡车出行数据可用于计算重型卡车货运交通发生和吸引,为城市货运规划提供支持。从企业运营管理的角度来看,重型卡车出行数据可以用来估计货运成本和货运需求,这对运输成本控制和卡车调度至关重要。从货运网络优化的角度,重型卡车出行数据可用于识别货运交通瓶颈,为提高货运网络性能指出方向。
4.3 城市内重型卡车出行链模式分析
城市重型卡车货运活动通常以出行链的形式进行,出行链模式对于理解重型卡车货运活动至关重要。在此,我们使用出行网络分析方法从每辆重型卡车的出行序列中识别典型的货运出行链。首先,我们使用DBSCAN聚类算法,将一辆重型卡车在空间上相邻的出行OD聚类为一个点,其为该重型卡车出行网络的一个节点。其次,我们将两个节点之间的出行作为重型卡车出行网络的有向边。一辆重型卡车根据其出行序列在该网络中移动,整个出行序列根据常驻点(如home)被分解为多个出行链,常驻点是每个出行链的端点。Fig. 16展示了这四个城市中重型卡车占比最高的10种典型的出行链模式。研究发现,这四个城市的各种典型出行链模式所占比例相似。从Fig. 16中可以看出,包含一个中间目的地(不是常驻点)的出行链模式所占比例最高(大于60%),而包含多个中间目的地的出行链模式仅占40%。通常而言,在包含多个中间目的地的出行链中,重型卡车的运输效率高于包含一个中间目的地的运输效率。因此,相关部门需要关注卡车调度优化,提高包括多个中间目的地的出行链比例,以提高重型卡车运输效率。

编辑:木瓜
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码