
使用新版本微博话题爬虫抓取到的 50w 武汉疫情数据情感随时间的变化
点击上方 月小水长 并 设为星标,第一时间接收干货推送
前面几次分享讲到了对新版微博话题爬虫的优化。
本次以武汉疫情为话题,抓取武汉疫情从爆发封城到解封五个月时间线上的相关微博,去重后共计约 50w 条微博数据,10 个字段,半个 G,可直接在本号后台回复 武汉疫情 获取之。
接着对着几十万条微博随机抽样了 1w 条数据,用情感分析,得到微博正文的情感倾向(或者说极性),正向 pos,负向 neg和中立 neg,情感倾向统计值随日期的演化趋势可视化结果如下。
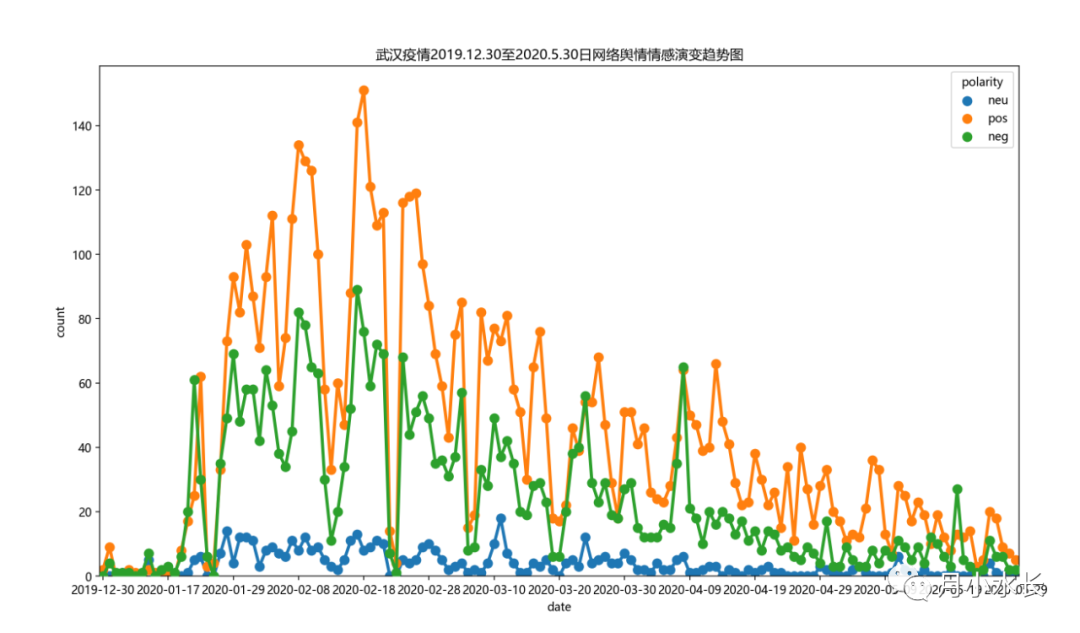
总体上来看,无论是正向,负向还是中立,这三者的 y 之和越大说明热度越高,武汉是从 2020 年 1 月 23 日开始封城的,而从上图来看也是这一天,微博上的热度开始从指数级的增长,而且这一时期,微博网络舆情的负向情感和正向情感能量差不多,这说明最开始疫情爆发的时间,至少一半的人态度的悲观或消极的;而到武汉 2020 年 4 月 8宣布解封后,热度逐渐消失。
微博话题爬虫本次更新了一些 bug,可去 2021 新版微博话题爬虫发布 (点击蓝字直达地址)获取 2021 新版本微博话题爬虫文件,下面说一下配置 json 文件的注意事项。
虽然理论上可以爬取任意时间段的,但还是建议一次不要设置过长,1-10 天即可。如果几十天的需求,可以手动在 json 文件中设置拆分时间段。
cookie 复制的时候注意前面和后面都是英文或数字字符,没有奇怪的符号。
一个话题可能会多次抓取,保存的文件是追加写的,难免会有表头或者数据上的重复,对于表头上的重复,可以在 Pycharm 中打开 csv,搜索列名 user_link 或其他定位到重复的行,删除掉该行即可。对于数据上的重复,可以用后文给出的代码去重。
尤其对于 windows 用户来说,不要在 excel 中修改这个 csv 结果文件,可能会造成文件编码,数据格式等的错乱,在 Pycharm 中打开即可。
# -*- coding: utf-8 -*-# create_time: 2021/9/24 21:26import pandas as pdfile_path = '武汉疫情.csv'def drop_duplicate(path, col_index = 0):df = pd.read_csv(path)first_column = df.columns.tolist()[col_index]# 去除重复行数据df.drop_duplicates(keep='first', inplace=True, subset=[first_column])# 可能还剩下重复 headerdf = df[-df[first_column].isin([first_column])]df.to_csv(path, encoding='utf-8-sig', index=False)drop_duplicate(file_path, col_index=0)