
谷歌最新姿势识别模型Pr-VIPE,怎么变都能认得你 | ECCV2020

新智元报道
新智元报道
来源:外媒
编辑:keyu
【新智元导读】近日,Google引入了将二维人体姿态映射到视图不变概率嵌入空间的Pr-VIPE模型,使用15块CPU在一天时间内即可完成训练。该模型中学习到的嵌入,可以直接用于姿态检索、动作识别和视频对齐等应用。此外,研究人员还提出了一个交叉视图检索基准,可以用来测试其他嵌入的视图不变属性。


“两个观察”成为Pr-VIPE建立基石,概率映射教会机器匹配情况
Pr-VIPE的输入是一组2D关键点,这些关键点来源于至少产生13个身体关键点的2D位姿估计器,而Pr-VIPE输出则是位姿嵌入的均值和方差。
其中,二维位姿嵌入之间的距离与它们在绝对三维位姿空间中的相似性相关。
研究人员的方法主要是基于两个观察结果而提出的: 1、同样的3D姿势在2D中可能会随着视点的变化而出现非常不同的效果。 2、同样的2D姿势可以从不同的3D姿势投射出来。
第一个观察结果激发了视图不变性的需要。
为了满足这一需要,研究人员定义了匹配概率,即不同的2D姿态从相同或相似的3D姿态投射出来的可能性。
同时,Pr-VIPE预测的姿态对匹配的匹配概率,应该高于非匹配的姿态对匹配概率。
为了解决第二个观察结果,Pr-VIPE利用了一个概率嵌入公式。
由于许多3D位姿可以投影到相同或类似的2D位姿,模型输入显示出一种固有的模糊性,很难通过嵌入空间中的确定性点对点映射来捕捉。
因此,研究人员采用了通过概率映射进而映射到嵌入分布的方法,并使用方差来表示输入2D位姿的不确定性。
例如,在下图中,左侧3D姿势的第三个2D视图与右侧不同3D姿势的第一个2D视图相似,所以研究人员将它们映射到嵌入空间的一个相似的位置上,并将方差设置为一个很大的值。
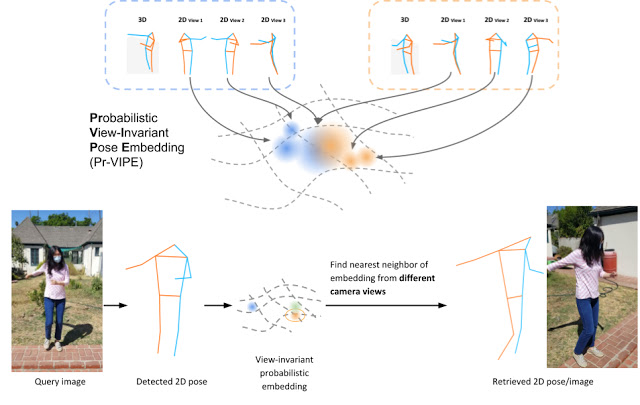
视图不变性(View-Invariance)
视图不变性(View-Invariance)
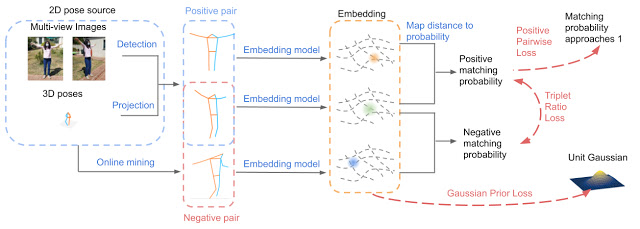 图:Pr-VIPE模型概述
图:Pr-VIPE模型概述提出新姿态检索基准, Pr-VIPE在多个数据集上效果突出
提出新姿态检索基准, Pr-VIPE在多个数据集上效果突出
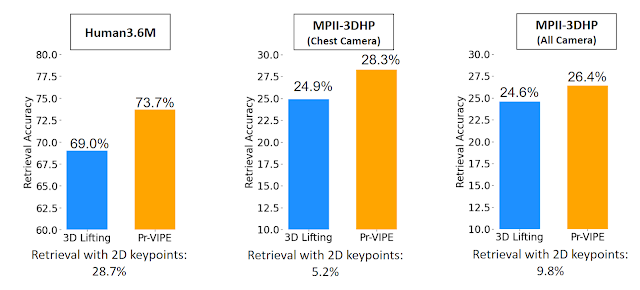
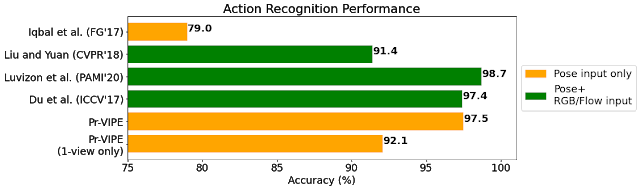
提升交叉视图检索和视频对齐表现,Pr-VIPE 应用广泛


参考链接:
https://ai.googleblog.com/2021/01/recognizing-pose-similarity-in-images.html


评论