延迟反馈带来的样本偏差如何处理

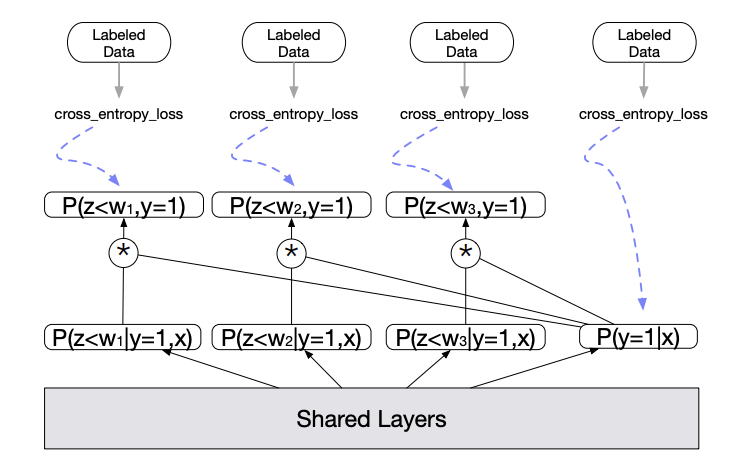
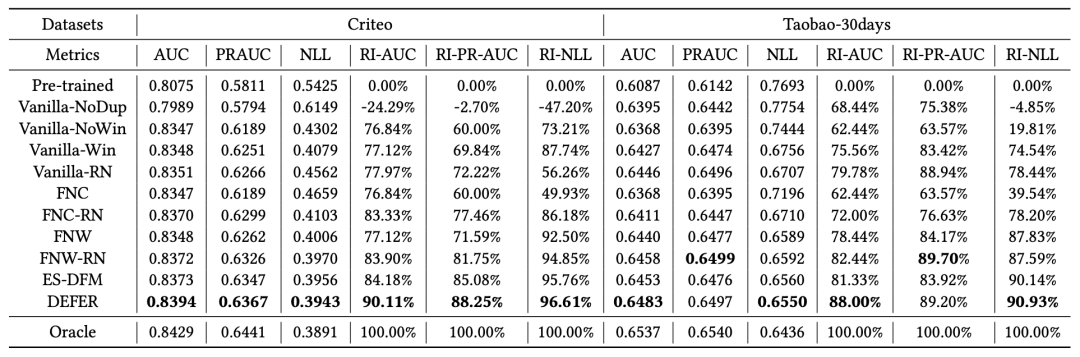
延迟反馈建模

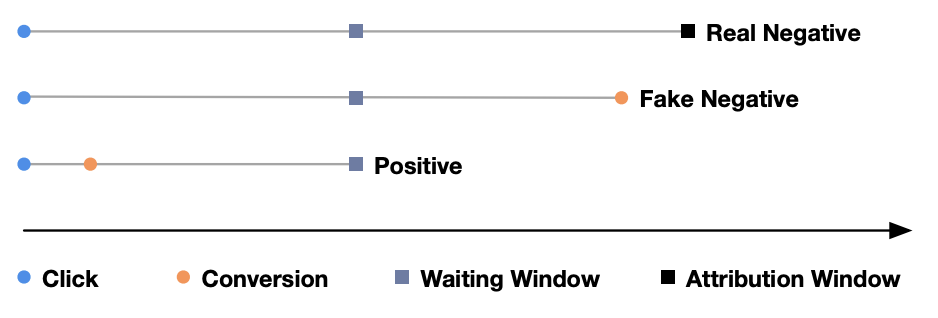
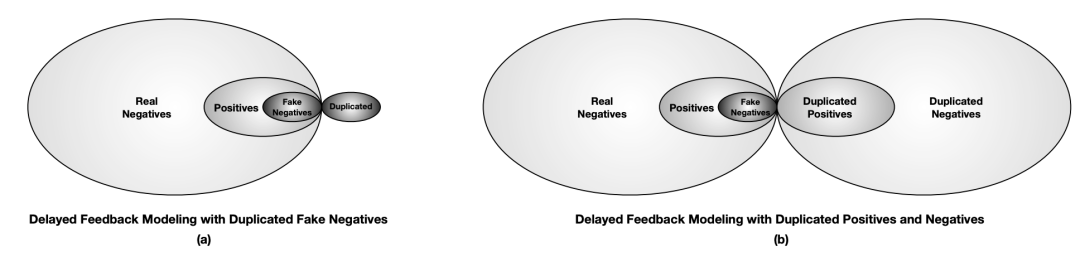
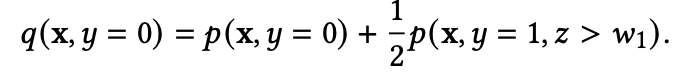
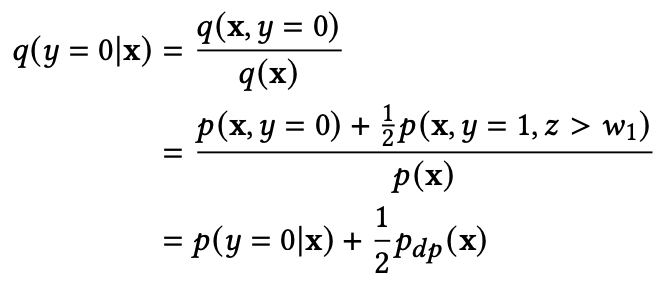
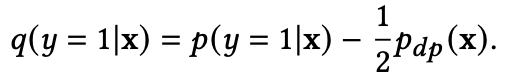
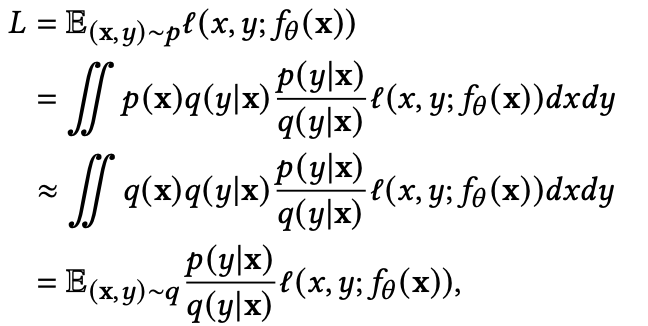
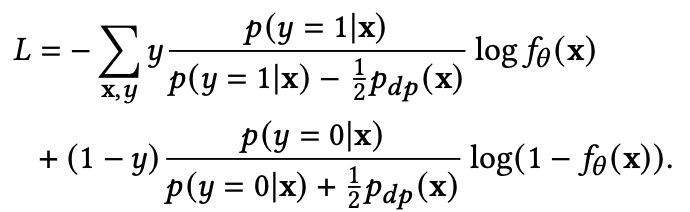
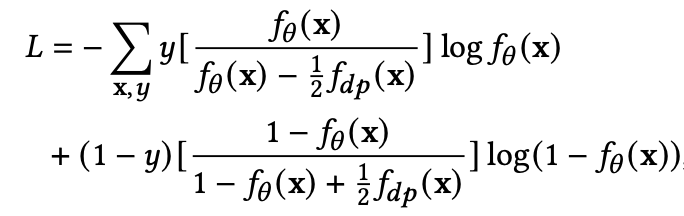
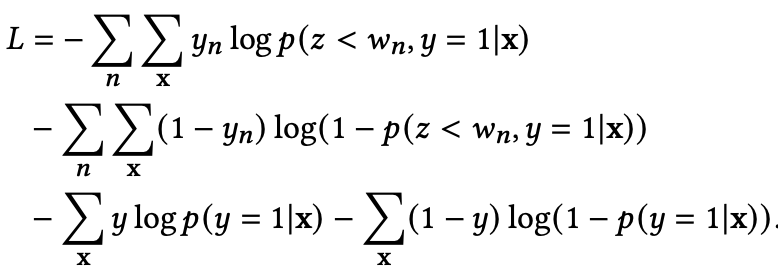
参考文献
1、Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
https://arxiv.org/pdf/2104.14121.pdf
评论
 下载APP
下载APP延迟反馈建模
参考文献
1、Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
https://arxiv.org/pdf/2104.14121.pdf