
常见的负载均衡算法的实现与应用
走过路过不要错过
点击 蓝字 关注我们
所谓负载均衡就是将外部发送过来的请求均匀或者根据某种算法分配到对称结构中的某一台服务器中。负载均衡可以分为硬件负载均衡和软件负载均衡,常见的硬件负载均衡有F5、Array等,但是这些设备都比较昂贵。相比之下,利用软件来实现负载均衡就比较简单了,常见的像是 Nginx 的反向代理负载均衡。
这篇文章并不去细说 Nginx 这类软件的具体配置,只是着重来了解几种常见的负载均衡算法的实现(本文使用Java描述)与应用。对于我们来讲,所了解的最基本的负载均衡算法包括了:随机、轮询、一致性Hash等几种方式,接下来就来详细介绍这几种算法:
一、随机#
1. 完全随机
所谓完全随机就是完全没有规律可言,每次随机种IP列表中选取一个,将请求打到该服务器上:
Copy
public class ServerIps {
public static final List<String> LIST = Arrays.asList(
"192.168.0.1",
"192.168.0.2",
"192.168.0.3",
"192.168.0.4",
"192.168.0.5"
);
}
Copy
public class Random {
public static String getServer() {
java.util.Random = new java.util.Random();
int rand = random.nextInt(ServerIps.LIST.size());
return ServerIps.LIST.get(rand);
}
public static void main(String[] args) {
for(int i = 0; i < 10; i++) {
System.out.println(getServer());
}
}
}
完全随机是最简单的负载均衡算法了,实现起来也很简单。但是我们在日常生产过程中,机器的处理效率肯定是不同的,有些机器处理得快,有些机器处理得慢,完全随机的缺点在此刻就很明显了,无法将更多的请求分配到更好的服务器上,由此就有了加权随机的思想了。
2. 加权随机#
加权随机常见的有两种实现方式,现在先来了解第一种方式,先构建一个ServerIps类先,如下:
Copy
public class ServerIps {
public static final Map<String, Integer> WEIGHT_LIST = new LinkedHashMap<String, Integer>();
static {
WEIGHT_LIST.put("192.168.0.1", 1);
WEIGHT_LIST.put("192.168.0.2", 8);
WEIGHT_LIST.put("192.168.0.3", 3);
WEIGHT_LIST.put("192.168.0.4", 6);
WEIGHT_LIST.put("192.168.0.5", 5);
}
}
首先这种实现方式的想法很简单,就是通过上面的服务器IP的List,再去构建一次List:如果一个IP服务器的权重为8,那么就往List里面添加8次该对应的IP地址,如果权重为3,那么就添加3次,以此类推。这样的话,结合前面的完全随机实现,那么这样权重越大的,在List中出现的比例也越高,被选中的几率当然也会更大:
Copy
public class WeightRandom {
public static String getServer() {
// 构建一个新的List
List<String> ips = new ArrayList<>();
for(String ip : ServerIps.WEIGHT_LIST.keySet()) {
Integer weight = ServerIps.WEIGHT_LIST.get(ip);
for(int i = 0; i < weight; i++) {
ips.add(ip);
}
}
java.util.Random random = new java.util.Random();
int randomPos = random.nextInt(ips.size());
return ips.get(randomPos);
}
public static void main(String[] args) {
// 连续调用10次
for(int i = 0; i < 10; i++) {
System.out.println(getServer());
}
}
}
上面代码可以自行测试一下,最后结构应该就是权重高的服务器被选中的几率更高。但是这也有一种很明显的缺点,如果现在的权重是像下面这样配置呢?
Copy
WEIGHT_LIST.put("192.168.0.1", 998);
WEIGHT_LIST.put("192.168.0.2", 13);
// ...
这样很明显就会带来一个新的问题,服务器中的新建的List动不动就会有上万条记录,那么此时服务器岂不是要白白浪费掉一部分内存去维护一个数组,所以此时我们就有了下面更优的实现。
3. 加权随机优化
假设我们现在有3台服务器,A服务器的权重为3,B服务器的权重为5,C服务器的权重为1。然后我们随机生成一个数:
-
如果生成的随机数为1,1 ≤ 3,那么此时请求在落在A的区间段,请求应该交由A来处理;
-
如果生成的随机数为5,那么此时 3 < 5,所以不在A区间,而 5 - 3 = 2 < 5,那么此时应该落在B区间;
-
如果生成的随机数为9,那么 9 > 3 + 5,所以不可能落在A区间或者B区间,而刚好后面C的权重为,落在C区间。
用图展示会更直观些,假设下面数组下标从1开始:
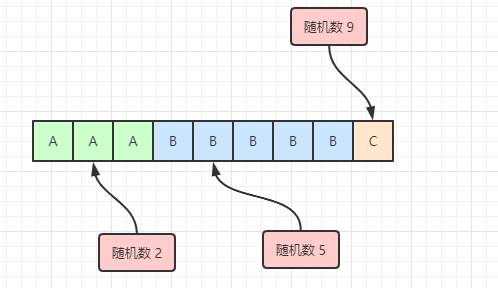
当然我们不可能真的像图中那样再去维护一个数组了,这样不也和刚刚那样白占内存么。所以每次但一个随机数过来时,我们会先去判断它是否小于A的权重,如果小于,那么就是请求发到A,如果不小于,注意,这里就得将随机数减去A的权重,然后下一次循环再和B的权重比,如果小于B的权重,那么就是请求到B,具体我们可以看下代码实现:
Copy
public class WeightRandomV2 {
public static String getServer() {
int totalWeight = 0;
for(Integer weight : ServerIps.WEIGHT_LIST.values()) {
totalWeight += weight;
}
java.util.Random random = new java.util.Random();
int pos = random.nextInt(totalWeight);
for(String ip : ServerIps.WEIGHT_LIST.keySet()) {
Integer weight = ServerIps.WEIGHT_LIST.get(ip);
if(pos < weight) {
return ip;
}
pos = pos - weight;
}
return "";
}
}
二、轮询
1. 完全轮询#
完全轮询的思想也十分简单,大家轮着来嘛,这次请求打到A上,下次就到B,再下次就是C了,这种实现的方式也很简单,代码实现如下:
Copy
public clsss RoundRobin {
private static Integer pos = 0;
public String String getServer() {
if (pos >= ServerIps.LIST.size()) {
pos = 0;
}
String ip = ServerIps.LIST.get(pos);
pos++;
return ip;
}
}
2. 加权轮询
完全轮询缺点和完全随机基本无异,当遇见性能较好的机器时,它的性能无法展示出来,当遇见性能较差的机器时,它的弊端倒是很容易显现,由此我们也需要来实现加权轮询。同样的,加权轮询也像加权随机那样有两种实现方式,一种靠着扩展列表,以外一种靠着偏移量,这里就简单演示下后者,毕竟后者的实现更优。
这里我们加上些简单的优化,请求是从前面发过来的,带有一个RequestID,那么我们就利用这个ID来帮助我们的轮询:
我们先创建一个RequestId模仿请求ID,代码如下:
Copy
public class RequestId {
public static Integer num = 0;
public static Integer getAndIncrement() {
return num++;
}
}
接下来我们就利用这个ID,然后进行轮询,代码如下:
Copy
public class WeightRoundRobin {
public static String getServer() {
int totalWeight = 0;
for (Integet weight : ServerIps.WEIGHT_LIST.values()) {
totalWeight += weight;
}
Integer requestId = Request.getAndIncrement();
Integer pos = requestId % totalWeight;
for(String ip : ServerIps.WEIGHT_LIST.keySet()) {
Integer weight = ServerIps.WEIGHT_LIST.get(ip);
if(pos < weight) {
return ip;
}
pos = pos - weight;
}
return "";
}
}
通过上面方式我们确实能实现加权轮询,但是这种轮询是连着来到,意思也就说,如果有请求过来,那么如果A服务器的权重为3,就会有连续3个请求打到A上,那么B此时却没有请求来访问,等到A服务器经历3个请求后,接下来又有连续的5个请求打到B上,依次类推。
Copy
A A A B B B B B C
这种实现也会来带很大的弊端,所以我们实际上是既要有轮询,轮询中间最好还是要有交叉,由此有了平滑加权轮询的思想。
3. 平滑加权轮询#
首先我们需要先来了解静态权重与动态权重的概念:
-
静态权重:权重由用户自己设定,在轮询过程中一直不变化,像上面几种加权方式就是静态权重;
-
动态权重:动态权重的思想与静态权重刚好相反,在轮询的过程中动态地变换各机器的权重,但是最终的加权效果不能与静态权重不同,只是用来实现交叉轮询的效果。
接下来就讲解一种动态权重实现的算法,假设用户给A、B、C三台服务器配置的权重为3、5、1,我们将3、5、1称为固定权重,在算法过程中变化的权重称为动态权重:
-
请求第一次过来,此时A、B、C的权重分别是3、5、1,在这里面 5 是大的,所对应的就是B服务器,将请求打到B服务器,接下来将我们刚刚所选中的服务器的权重减去所有机器的权重加起来的总值,作为接下来的动态权重,没被选中的服务器权重不变。也就是B服务器:5 - (3 + 5 + 1) = -4;那么第一次请求结束后三台服务器的动态权重为:3、-4、1;
-
请求第二次过来,此时A、B、C的动态权重为3、-4、1,固定权重3、5、1,我们需要将这两个权重相加,得出此时三台服务器的动态权重为6、1、2。那么此时A的权重最大,那么就将请求打到A上。接下来再将刚刚所选中的服务器的动态权重减去所有服务器的权重加起来的总值,也就是A服务器:6 - (3 + 5 + 1 ) = -3;那么第二次请求结束后三台服务器的动态权重为:-3、1、2;
-
请求第三次过来,此时A、B、C的动态权重为-3、1、2,固定权重3、5、1,将这两个权重相加,得出此时三台服务器的动态权重为0、6、3。那么此时B的权重最大,那么就将请求打到B服务器上。接下来再将刚刚所选中的服务器的动态权重减去所有的服务器的权重加起来的总值,也就是B服务器:6 - (3 + 5 + 1) = -3;那么第三次请求结束后三台服务器的动态权重为:0、-3、3;
-
......
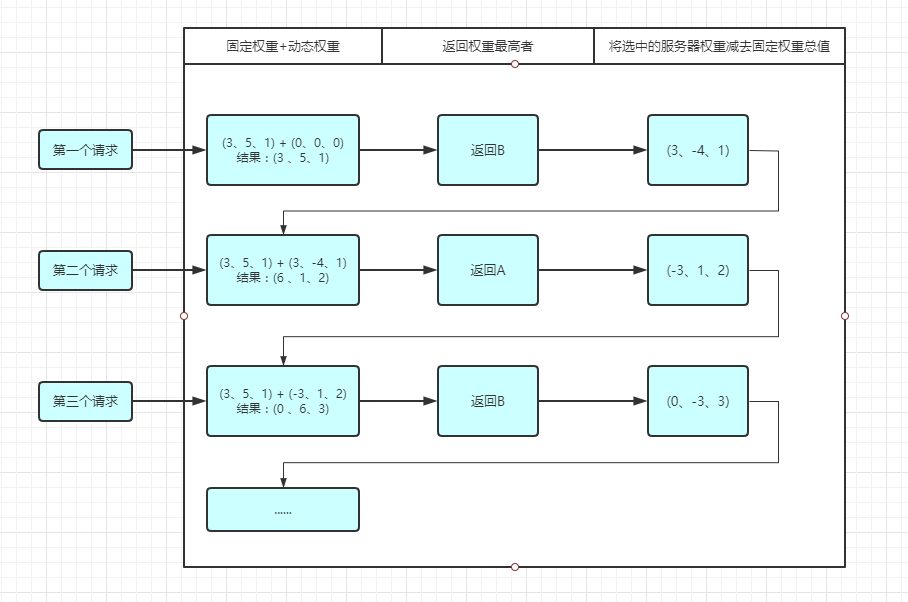
到这里应该能有一个基本的了解,那么我们现在就用代码实现一遍:
首先实现一个权重类:
Copy
public class Weight {
private String ip;
private Integer weight; // 固定权重
private Integer currentWeight; // 动态权重
public Weight(String ip, Integer weight, Integer currentWeight) {
this.ip = up;
this.weight = weight;
this.currentWeight = currentWeight;
}
// get & set methods...
}
接下来我们就来实现这个平滑加权轮询算法:
Copy
public class WeightRoundRobinV3 {
private static Map<String, Weight> weights = new HashMap<String, Weight>();
public static String getServer() {
if (weights.isEmpty()) {
ServerIps.WEIGHT_LIST.forEach((ip, weight) -> {
weights.put(ip, new Weight(ip, weight, 0));
});
}
for (Weight weight : weight.values()) {
weight.setCurrentWeight(weight.getCurrentWeight() + weight.getWeight());
}
// 寻找本次请求中权重最高的服务器IP
Weight maxCurrentWeight = null;
for (Weight weight : weights.values()) {
if (maxCurrentWeight == null || weight.getCurrentWeight() > maxCurrentWeight.getCurrentWeight()) {
maxCurrentWeight = weight;
}
}
return maxCurrentWeight.getIp();
}
public static void main(String[] args) {
// 连续调用20次
for (int i = 0; i < 20; i++) {
System.out.print(getServer() + " ");
}
}
}
三、一致性Hash
其实我们可以发现,随机和轮询的思想其实差不多,都是尽可能将请求均衡地派发到服务器中,最多加权实现。如果我们现在想要让某个用于发过来的请求一直打到相同的服务器上去处理,那该怎么办呢?常见的实现就是一致性Hash算法了,这一算法在Nginx中配置负载均衡时也有体现:
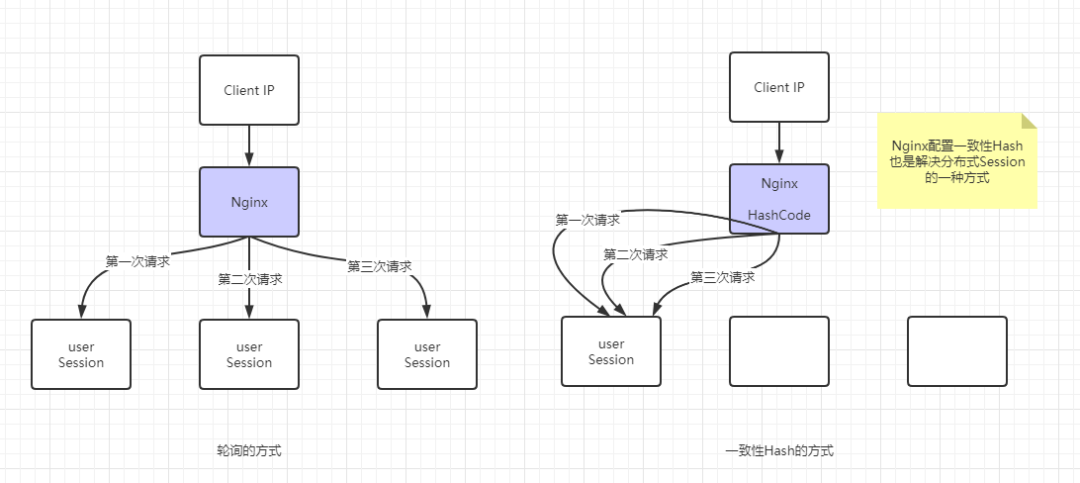
如上图,当有相同用户的连接过来的时候,可以通过Hash映射的方式打到同一台服务器上,这也是解决分布式Session的一种思路。
现在这里就涉及到一些问题了,我们一步一步来解决。首先用户的请求过来,根据Hash算法计算出对应的值后,如何找到对应的服务器IP呢?
这很简单,将所有可能的HashCode值列出来,造一个Map,将HashCode与IP一一对应,大概多个HashCode会对应到同一台机器。
那如果HashCode的可能值有很多个呢?那岂不是需要去造一个占用内存很大的Map?
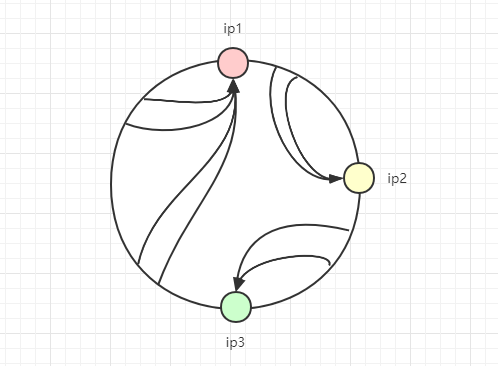
嗯,客户端发起的请求情况是无穷无尽的(客户端地址不同,请求参数不同等等),所以对于哈希值也是无穷大的,所以我们不可能把所有的哈希值都进行映射到服务端IP上,这里就需要用到哈希环了,如下图:
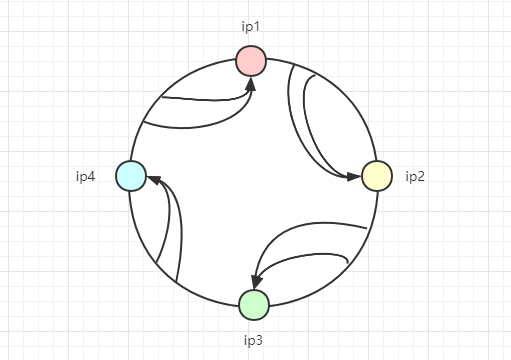
-
哈希值如果在ip1和ip2之间,则应该选择ip2作为响应服务器;
-
哈希值如果在ip2和ip3之间,则应该选择ip3作为响应服务器;
-
哈希值如果在ip3和ip4之间,则应该选择ip4作为响应服务器;
-
哈希值如果在ip4和ip1之间,则应该选择ip1作为响应服务器;
如果多台服务器所“控制”的区域很小,或者有时候其中一台服务器宕机了,像下面这种出现哈希倾斜的情况,怎么办?
嗯,像这种情况可以加入虚拟节点,如下图所示:
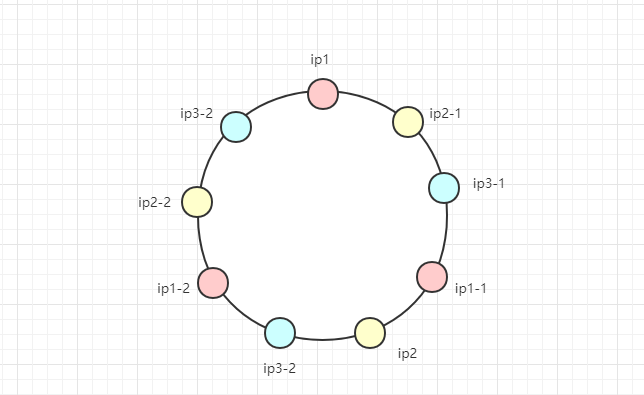
其中ip1-2、ip2-1等节点其实是虚拟的,等同于ip1和ip2服务器本身。实际上,这只是处理这种不平衡性的一种思路,实际上就算哈希环本身是平衡的,你也可以加入如更多的虚拟节点来使这个环更加平滑。
那么我们如何来实现这个算法呢?接下来我们就来看代码实现:
Copy
public class ConsitentHash {
// 用红黑树,有序
private static TreeMap<Integer, String> virtualNodes = new TreeMap<>();
private static final int VIRTUAL_NODES = 160;
static {
// 对每个真实的节点添加虚拟节点,虚拟节点会根据哈希算法进行散列
for (String ip : ServerIps.LIST) {
for (int i = 0; i < VIRTUAL_NODES; i++) {
int hash = getHash(ip + "VN" + i);
virtualNodes.put(hash, ip);
}
}
}
public staitc String getServer(String clientInfo) {
int hash = getHash(client);
// 得到大于该Hash值的子红黑树
SortedMap<Integer, String> subMap = virtualNode.tailMap(hash);
// 获取该树的第一个元素,也就是最小的元素
Integer nodeIndex = subMap.firstKey();
// 如果没有大于该元素的子树了,则取整棵树的第一个元素,相当于取哈希环中的最小的那个元素
if (nodeIndex == null) {
nodeIndex = virtualNodes.firstKey();
}
// 返回对应的虚拟节点名称
return virtualNodes.get(nodeIndex);
}
// 计算hash值的算法
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 216613621L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hsah ^= hash >> 7;
return hashl
}
}
四、最小连接数法
前面几种方法费尽心思来实现服务消费者请求次数分配的均衡,当然这么做是没错的,可以为后端的多台服务器平均分配工作量,最大程度地提高服务器的利用率,但是实际情况是否真的如此?实际情况中,请求次数的均衡真的能代表负载的均衡吗?这是一个值得思考的问题。
上面的问题,再换一个角度来说就是:以后端服务器的视角来观察系统的负载,而非请求发起方来观察。最小连接数法便属于此类。
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它正是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能地提高后端服务器的利用效率,将负载合理地分流到每一台机器。由于最小连接数设计服务器连接数的汇总和感知,设计与实现较为繁琐,此处就不说它的实现了。
想进大厂的小伙伴请注意,
大厂面试的套路很神奇,
早做准备对大家更有好处,
埋头刷题效率低,
看面经会更有效率!
小编准备了一份 大厂 常问面经 汇总集
大致内容包括了: Java 集合、JVM、多线程、并发编程、设计模式、Spring全家桶、Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、MongoDB、Redis、MySQL、RabbitMQ、Kafka、Linux、Netty、Tomcat等大厂面试题等、等技术栈!
剩下的就不会给大家一展出来了,以上资料按照一下操作即可获得
——将文章进行 转发 和 评论 , 关注公众号【Java烤猪皮】 ,关注后继续后台回复领取口令“ 666 ”即可免费领文章取中所提供的资料。
 往期精品推荐
往期精品推荐 腾讯、阿里、滴滴后台试题汇集总结 — (含答案)
面试:史上最全多线程序面试题!
最新阿里内推Java后端试题
JVM难学?那是因为你没有真正看完整这篇文章
 — 结束 —
— 结束 —
关注作者微信公众号 — 《JAVA烤猪皮》
了解了更多java后端架构知识以及最新面试宝典
看完本文记得给作者点赞+在看哦~~~大家的支持,是作者来源不断出文的动力~