
SpringCloud的负载均衡
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 拾万个为什么
来源 | urlify.cn/iuQJv2
一.什么是负载均衡
负载均衡(Load-balance LB),指的是将用户的请求平摊分配到各个服务器上,从而达到系统的高可用。常见的负载均衡软件有Nginx、lvs等。
二.负载均衡的简单分类
1)集中式LB:集中式负载均衡指的是,在服务消费者(client)和服务提供者(provider)之间提供负载均衡设施,通过该设施把消费者(client)的请求通过某种策略转发给服务提供者(provider),常见的集中式负载均衡是Nginx;
2)进程式LB:将负载均衡的逻辑集成到消费者(client)身上,即消费者从服务注册中心获取服务列表,获知有哪些地址可用,再从这些地址里选出合适的服务器,springCloud的Ribbon就是一个进程式的负载均衡工具。
三.为什么需要做负载均衡
1) 不做负载均衡,可能导致某台机子负荷太重而挂掉;
2)导致资源浪费,比如某些机子收到太多的请求,肯定会导致某些机子收到很少请求甚至收不到请求,这样会浪费系统资源。
四.springCloud如何开启负载均衡
1)在消费者子工程的pom.xml文件的加入相关依赖(https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-ribbon/1.4.7.RELEASE);
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-ribbon -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
消费者需要获取服务注册中心的注册列表信息,把Eureka的依赖包也放进pom.xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
2)在application.yml里配置服务注册中心的信息
在该消费者(client)的application.yml里配置Eureka的信息,至于如何启动一个springCloud项目,请看这篇博客https://www.cnblogs.com/fengrongriup/p/14464208.html
#配置Eureka
eureka:
client:
#是否注册自己到服务注册中心,消费者不用提供服务
register-with-eureka: false
service-url:
#访问的url
defaultZone: http://localhost:8002/eureka/
3)在消费者启动类上面加上注解@EnableEurekaClient
@EnableEurekaClient
4)在配置文件的Bean上加上
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
五.IRule
什么是IRule
IRule接口代表负载均衡的策略,它的不同的实现类代表不同的策略,它的四种实现类和它的关系如下()
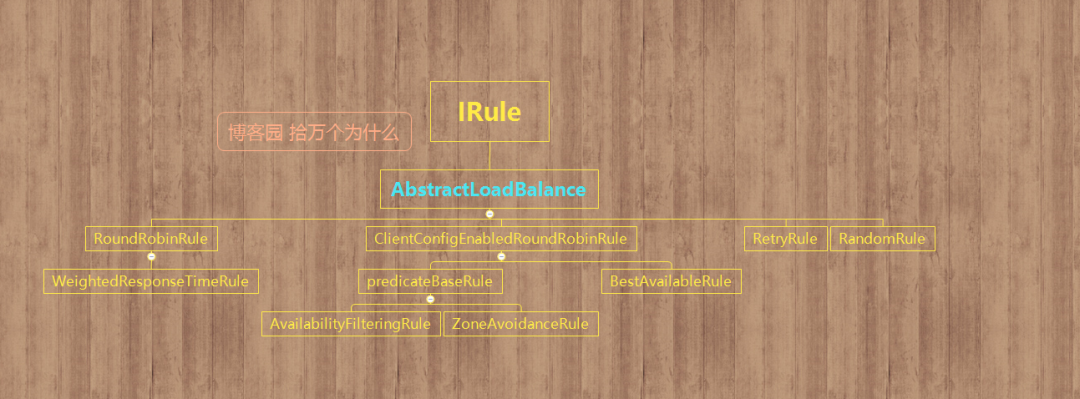
说明一下(idea找Irule的方法:ctrl+n 填入IRule进行查找)
1.RandomRule:表示随机策略,它将从服务清单中随机选择一个服务;
public class RandomRule extends AbstractLoadBalancerRule {
public RandomRule() {
}
@SuppressWarnings({"RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE"})
//传入一个负载均衡器
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
} else {
Server server = null;
while(server == null) {
if (Thread.interrupted()) {
return null;
}
//通过负载均衡器获取对应的服务列表
List<Server> upList = lb.getReachableServers();
//通过负载均衡器获取全部服务列表
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
//获取一个随机数
int index = this.chooseRandomInt(serverCount);
//通过这个随机数从列表里获取服务
server = (Server)upList.get(index);
if (server == null) {
//当前线程转为就绪状态,让出cpu
Thread.yield();
} else {
if (server.isAlive()) {
return server;
}
server = null;
Thread.yield();
}
}
return server;
}
}
小结:通过获取到的所有服务的数量,以这个数量为标准获取一个(0,服务数量)的数作为获取服务实例的下标,从而获取到服务实例
2.ClientConfigEnabledRoundRobinRule:ClientConfigEnabledRoundRobinRule并没有实现什么特殊的处理逻辑,但是他的子类可以实现一些高级策略, 当一些本身的策略无法实现某些需求的时候,它也可以做为父类帮助实现某些策略,一般情况下我们都不会使用它;
public class ClientConfigEnabledRoundRobinRule extends AbstractLoadBalancerRule {
//使用“4”中的RoundRobinRule策略
RoundRobinRule roundRobinRule = new RoundRobinRule();
public ClientConfigEnabledRoundRobinRule() {
}
public void initWithNiwsConfig(IClientConfig clientConfig) {
this.roundRobinRule = new RoundRobinRule();
}
public void setLoadBalancer(ILoadBalancer lb) {
super.setLoadBalancer(lb);
this.roundRobinRule.setLoadBalancer(lb);
}
public Server choose(Object key) {
if (this.roundRobinRule != null) {
return this.roundRobinRule.choose(key);
} else {
throw new IllegalArgumentException("This class has not been initialized with the RoundRobinRule class");
}
}
}
小结:用来作为父类,子类通过实现它来实现一些高级负载均衡策略
1)ClientConfigEnabledRoundRobinRule的子类BestAvailableRule:从该策略的名字就可以知道,bestAvailable的意思是最好获取的,该策略的作用是获取到最空闲的服务实例;
public class BestAvailableRule extends ClientConfigEnabledRoundRobinRule {
//注入负载均衡器,它可以选择服务实例
private LoadBalancerStats loadBalancerStats;
public BestAvailableRule() {
}
public Server choose(Object key) {
//假如负载均衡器实例为空,采用它父类的负载均衡机制,也就是轮询机制,因为它的父类采用的就是轮询机制
if (this.loadBalancerStats == null) {
return super.choose(key);
} else {
//获取所有服务实例并放入列表里
List<Server> serverList = this.getLoadBalancer().getAllServers();
//并发量
int minimalConcurrentConnections = 2147483647;
long currentTime = System.currentTimeMillis();
Server chosen = null;
Iterator var7 = serverList.iterator();
//遍历服务列表
while(var7.hasNext()) {
Server server = (Server)var7.next();
ServerStats serverStats = this.loadBalancerStats.getSingleServerStat(server);
//淘汰掉已经负载的服务实例
if (!serverStats.isCircuitBreakerTripped(currentTime)) {
//获得当前服务的请求量(并发量)
int concurrentConnections = serverStats.getActiveRequestsCount(currentTime);
//找出并发了最小的服务
if (concurrentConnections < minimalConcurrentConnections) {
minimalConcurrentConnections = concurrentConnections;
chosen = server;
}
}
}
if (chosen == null) {
return super.choose(key);
} else {
return chosen;
}
}
}
public void setLoadBalancer(ILoadBalancer lb) {
super.setLoadBalancer(lb);
if (lb instanceof AbstractLoadBalancer) {
this.loadBalancerStats = ((AbstractLoadBalancer)lb).getLoadBalancerStats();
}
}
}
小结:ClientConfigEnabledRoundRobinRule子类之一,获取到并发了最少的服务
2)ClientConfigEnabledRoundRobinRule的另一个子类是PredicateBasedRule:通过源码可以看出它是一个抽象类,它的抽象方法getPredicate()返回一个AbstractServerPredicate的实例,然后它的choose方法调用AbstractServerPredicate类的chooseRoundRobinAfterFiltering方法获取具体的Server实例并返回
public abstract class PredicateBasedRule extends ClientConfigEnabledRoundRobinRule {
public PredicateBasedRule() {
}
//获取AbstractServerPredicate对象
public abstract AbstractServerPredicate getPredicate();
public Server choose(Object key) {
//获取当前策略的负载均衡器
ILoadBalancer lb = this.getLoadBalancer();
//通过AbstractServerPredicate的子类过滤掉一部分实例(它实现了Predicate)
//以轮询的方式从过滤后的服务里选择一个服务
Optional<Server> server = this.getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
return server.isPresent() ? (Server)server.get() : null;
}
}
再看看它的chooseRoundRobinAfterFiltering()方法是如何实现的
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
List<Server> eligible = this.getEligibleServers(servers, loadBalancerKey);
return eligible.size() == 0 ? Optional.absent() : Optional.of(eligible.get(this.incrementAndGetModulo(eligible.size())));
}
是这样的,先通过this.getEligibleServers(servers, loadBalancerKey)方法获取一部分实例,然后判断这部分实例是否为空,如果不为空则调用eligible.get(this.incrementAndGetModulo(eligible.size())方法从这部分实例里获取一个服务,点进this.getEligibleServers看
public List<Server> getEligibleServers(List<Server> servers, Object loadBalancerKey) {
if (loadBalancerKey == null) {
return ImmutableList.copyOf(Iterables.filter(servers, this.getServerOnlyPredicate()));
} else {
List<Server> results = Lists.newArrayList();
Iterator var4 = servers.iterator();
while(var4.hasNext()) {
Server server = (Server)var4.next();
//条件满足
if (this.apply(new PredicateKey(loadBalancerKey, server))) {
//添加到集合里
results.add(server);
}
}
return results;
}
}
getEligibleServers方法是根据this.apply(new PredicateKey(loadBalancerKey, server))进行过滤的,如果满足,就添加到返回的集合中。符合什么条件才可以进行过滤呢?可以发现,apply是用this调用的,this指的是AbstractServerPredicate(它的类对象),但是,该类是个抽象类,该实例是不存在的,需要子类去实现,它的子类在这里暂时不是看了,以后有空再深入学习下,它的子类如下,实现哪个子类,就用什么 方式过滤。

再回到chooseRoundRobinAfterFiltering()方法,刚刚说完它通过 getEligibleServers方法过滤并获取到一部分实例,然后再通过this.incrementAndGetModulo(eligible.size())方法从这部分实例里选择一个实例返回,该方法的意思是直接返回下一个整数(索引值),通过该索引值从返回的实例列表中取得Server实例。
private int incrementAndGetModulo(int modulo) {
//当前下标
int current;
//下一个下标
int next;
do {
//获得当前下标值
current = this.nextIndex.get();
next = (current + 1) % modulo;
} while(!this.nextIndex.compareAndSet(current, next) || current >= modulo);
return current;
}
源码撸明白了,再来理一下chooseRoundRobinAfterFiltering()的思路:先通过getEligibleServers()方法获得一部分服务实例,再从这部分服务实例里拿到当前服务实例的下一个服务对象使用。
小结:通过AbstractServerPredicate的chooseRoundRobinAfterFiltering方法进行过滤,获取备选的服务实例清单,然后用线性轮询选择一个实例,是一个抽象类,过滤策略在AbstractServerPredicate的子类中具体实现
3.RetryRule:是对选定的负载均衡策略加上重试机制,即在一个配置好的时间段内(默认500ms),当选择实例不成功,则一直尝试使用subRule的方式选择一个可用的实例,在调用时间到达阀值的时候还没找到可用服务,则返回空,如果没有配置负载策略,默认轮询(即“4”中的轮询);
先贴上它的源码
public class RetryRule extends AbstractLoadBalancerRule {
//从这可以看出,默认使用轮询机制
IRule subRule = new RoundRobinRule();
//500秒的阀值
long maxRetryMillis = 500L;
//无参构造函数
public RetryRule() {
}
//使用轮询机制
public RetryRule(IRule subRule) {
this.subRule = (IRule)(subRule != null ? subRule : new RoundRobinRule());
}
public RetryRule(IRule subRule, long maxRetryMillis) {
this.subRule = (IRule)(subRule != null ? subRule : new RoundRobinRule());
this.maxRetryMillis = maxRetryMillis > 0L ? maxRetryMillis : 500L;
}
public void setRule(IRule subRule) {
this.subRule = (IRule)(subRule != null ? subRule : new RoundRobinRule());
}
public IRule getRule() {
return this.subRule;
}
//设置最大耗时时间(阀值),最多重试多久
public void setMaxRetryMillis(long maxRetryMillis) {
if (maxRetryMillis > 0L) {
this.maxRetryMillis = maxRetryMillis;
} else {
this.maxRetryMillis = 500L;
}
}
//获取重试的时间
public long getMaxRetryMillis() {
return this.maxRetryMillis;
}
//设置负载均衡器,用以获取服务
public void setLoadBalancer(ILoadBalancer lb) {
super.setLoadBalancer(lb);
this.subRule.setLoadBalancer(lb);
}
//通过负载均衡器选择服务
public Server choose(ILoadBalancer lb, Object key) {
long requestTime = System.currentTimeMillis();
//当前时间+阀值 = 截止时间
long deadline = requestTime + this.maxRetryMillis;
Server answer = null;
answer = this.subRule.choose(key);
//获取到服务直接返回
if ((answer == null || !answer.isAlive()) && System.currentTimeMillis() < deadline) {
InterruptTask task = new InterruptTask(deadline - System.currentTimeMillis());
//获取不到服务的情况下反复获取
while(!Thread.interrupted()) {
answer = this.subRule.choose(key);
if (answer != null && answer.isAlive() || System.currentTimeMillis() >= deadline) {
break;
}
Thread.yield();
}
task.cancel();
}
return answer != null && answer.isAlive() ? answer : null;
}
public Server choose(Object key) {
return this.choose(this.getLoadBalancer(), key);
}
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
小结:采用RoundRobinRule的选择机制,进行反复尝试,当花费时间超过设置的阈值maxRetryMills时,就返回null
4.RoundRobinRule:轮询策略,它会从服务清单中按照轮询的方式依次选择每个服务实例,它的工作原理是:直接获取下一个可用实例,如果超过十次没有获取到可用的服务实例,则返回空且报出异常信息;
public class RoundRobinRule extends AbstractLoadBalancerRule {
private AtomicInteger nextServerCyclicCounter;
private static final boolean AVAILABLE_ONLY_SERVERS = true;
private static final boolean ALL_SERVERS = false;
private static Logger log = LoggerFactory.getLogger(RoundRobinRule.class);
public RoundRobinRule() {
this.nextServerCyclicCounter = new AtomicInteger(0);
}
public RoundRobinRule(ILoadBalancer lb) {
this();
this.setLoadBalancer(lb);
}
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
} else {
Server server = null;
int count = 0;
while(true) {
//选择十次,十次都没选到可用服务就返回空
if (server == null && count++ < 10) {
List<Server> reachableServers = lb.getReachableServers();
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if (upCount != 0 && serverCount != 0) {
int nextServerIndex = this.incrementAndGetModulo(serverCount);
server = (Server)allServers.get(nextServerIndex);
if (server == null) {
Thread.yield();
} else {
if (server.isAlive() && server.isReadyToServe()) {
return server;
}
server = null;
}
continue;
}
log.warn("No up servers available from load balancer: " + lb);
return null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: " + lb);
}
return server;
}
}
}
//递增的形式实现轮询
private int incrementAndGetModulo(int modulo) {
int current;
int next;
do {
current = this.nextServerCyclicCounter.get();
next = (current + 1) % modulo;
} while(!this.nextServerCyclicCounter.compareAndSet(current, next));
return next;
}
public Server choose(Object key) {
return this.choose(this.getLoadBalancer(), key);
}
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
小结:采用线性轮询机制循环依次选择每个服务实例,直到选择到一个不为空的服务实例或循环次数达到10次
它有个子类WeightedResponseTimeRule,WeightedResponseTimeRule是对RoundRobinRule的优化。WeightedResponseTimeRule在其父类的基础上,增加了定时任务这个功能,通过启动一个定时任务来计算每个服务的权重,然后遍历服务列表选择服务实例,从而达到更加优秀的分配效果。我们这里把这个类分为三部分:定时任务,计算权值,选择服务
1)定时任务
//定时任务
void initialize(ILoadBalancer lb) {
if (this.serverWeightTimer != null) {
this.serverWeightTimer.cancel();
}
this.serverWeightTimer = new Timer("NFLoadBalancer-serverWeightTimer-" + this.name, true);
//开启一个任务,每30秒执行一次
this.serverWeightTimer.schedule(new WeightedResponseTimeRule.DynamicServerWeightTask(), 0L, (long)this.serverWeightTaskTimerInterval);
WeightedResponseTimeRule.ServerWeight sw = new WeightedResponseTimeRule.ServerWeight();
sw.maintainWeights();
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
public void run() {
WeightedResponseTimeRule.logger.info("Stopping NFLoadBalancer-serverWeightTimer-" + WeightedResponseTimeRule.this.name);
WeightedResponseTimeRule.this.serverWeightTimer.cancel();
}
}));
}
DynamicServerWeightTask()任务如下:
class DynamicServerWeightTask extends TimerTask {
DynamicServerWeightTask() {
}
public void run() {
WeightedResponseTimeRule.ServerWeight serverWeight = WeightedResponseTimeRule.this.new ServerWeight();
try {
//计算权重
serverWeight.maintainWeights();
} catch (Exception var3) {
WeightedResponseTimeRule.logger.error("Error running DynamicServerWeightTask for {}", WeightedResponseTimeRule.this.name, var3);
}
}
}
小结:调用initialize方法开启定时任务,再在任务里计算服务的权重
2)计算权重:第一步,先算出所有实例的响应时间;第二步,再根据所有实例响应时间,算出每个实例的权重
//用来存储权重
private volatile List<Double> accumulatedWeights = new ArrayList();
//内部类
class ServerWeight {
ServerWeight() {
}
//该方法用于计算权重
public void maintainWeights() {
//获取负载均衡器
ILoadBalancer lb = WeightedResponseTimeRule.this.getLoadBalancer();
if (lb != null) {
if (WeightedResponseTimeRule.this.serverWeightAssignmentInProgress.compareAndSet(false, true)) {
try {
WeightedResponseTimeRule.logger.info("Weight adjusting job started");
AbstractLoadBalancer nlb = (AbstractLoadBalancer)lb;
//获得每个服务实例的信息
LoadBalancerStats stats = nlb.getLoadBalancerStats();
if (stats != null) {
//实例的响应时间
double totalResponseTime = 0.0D;
ServerStats ss;
//累加所有实例的响应时间
for(Iterator var6 = nlb.getAllServers().iterator(); var6.hasNext(); totalResponseTime += ss.getResponseTimeAvg()) {
Server server = (Server)var6.next();
ss = stats.getSingleServerStat(server);
}
Double weightSoFar = 0.0D;
List<Double> finalWeights = new ArrayList();
Iterator var20 = nlb.getAllServers().iterator();
//计算负载均衡器所有服务的权重,公式是weightSoFar = weightSoFar + weight-实例平均响应时间
while(var20.hasNext()) {
Server serverx = (Server)var20.next();
ServerStats ssx = stats.getSingleServerStat(serverx);
double weight = totalResponseTime - ssx.getResponseTimeAvg();
weightSoFar = weightSoFar + weight;
finalWeights.add(weightSoFar);
}
WeightedResponseTimeRule.this.setWeights(finalWeights);
return;
}
} catch (Exception var16) {
WeightedResponseTimeRule.logger.error("Error calculating server weights", var16);
return;
} finally {
WeightedResponseTimeRule.this.serverWeightAssignmentInProgress.set(false);
}
}
}
}
}
3)选择服务
@SuppressWarnings({"RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE"})
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
} else {
Server server = null;
while(server == null) {
List<Double> currentWeights = this.accumulatedWeights;
if (Thread.interrupted()) {
return null;
}
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int serverIndex = 0;
double maxTotalWeight = currentWeights.size() == 0 ? 0.0D : (Double)currentWeights.get(currentWeights.size() - 1);
if (maxTotalWeight >= 0.001D && serverCount == currentWeights.size()) {
//生产0到最大权重值的随机数
double randomWeight = this.random.nextDouble() * maxTotalWeight;
int n = 0;
//循环权重区间
for(Iterator var13 = currentWeights.iterator(); var13.hasNext(); ++n) {
//获取到循环的数
Double d = (Double)var13.next();
//假如随机数在这个区间内,就拿该索引d服务列表获取对应的实例
if (d >= randomWeight) {
serverIndex = n;
break;
}
}
server = (Server)allList.get(serverIndex);
} else {
server = super.choose(this.getLoadBalancer(), key);
if (server == null) {
return server;
}
}
if (server == null) {
Thread.yield();
} else {
if (server.isAlive()) {
return server;
}
server = null;
}
}
return server;
}
}
小结:首先生成了一个[0,最大权重值) 区间内的随机数,然后遍历权重列表,假如当前随机数在这个区间内,就通过该下标获得对应的服务。
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 