
分布式唯一ID的几种生成方案
AI全套:Python3+TensorFlow打造人脸识别智能小程序
最新人工智能资料-Google工程师亲授 Tensorflow-入门到进阶
黑马头条项目 - Java Springboot2.0(视频、资料、代码和讲义)14天完整版
作者:稻哥说编程
链接:https://www.jianshu.com/p/4ba1c5e8c185
在业务开发中,大量场景需要唯一ID来进行标识:用户需要唯一身份标识、商品需要唯一标识、消息需要唯一标识、事件需要唯一标识等,都需要全局唯一ID,尤其是复杂的分布式业务场景中全局唯一ID更为重要。
那么,分布式唯一ID有哪些特性或要求呢? ① 唯一性:生成的ID全局唯一,在特定范围内冲突概率极小。
② 有序性:生成的ID按某种规则有序,便于数据库插入及排序。
③ 可用性:可保证高并发下的可用性, 确保任何时候都能正确的生成ID。
④ 自主性:分布式环境下不依赖中心认证即可自行生成ID。
⑤ 安全性:不暴露系统和业务的信息, 如:订单数,用户数等。
分布式唯一ID有哪些生成方法呢? 总的来说,大概有三大类方法,分别是:数据库自增ID、UUID生成、snowflake雪花算法。
一、数据库自增ID
核心思想:使用数据库的id自增策略(如: Mysql的auto_increment)。
优点:
① 简单,天然有序。
缺点:
① 并发性不好。
② 数据库写压力大。
③ 数据库故障后不可使用。
④ 存在数量泄露风险。
针对以上缺点,有以下几种优化方案:
1. 数据库水平拆分,设置不同的初始值和相同的自增步长
核心思想:将数据库进行水平拆分,每个数据库设置不同的初始值和相同的自增步长。

如图所示,可保证每台数据库生成的ID是不冲突的,但这种固定步长的方式也会带来扩容的问题,很容易想到当扩容时会出现无ID初始值可分的窘境。解决方案有:
① 根据扩容考虑决定步长。
② 增加其他位标记区分扩容。
这其实都是在需求与方案间的权衡,根据需求来选择最适合的方式。
2. 批量缓存自增ID
核心思想:如果使用单台机器做ID生成,可以避免固定步长带来的扩容问题(方案1的缺点)。
具体做法是:每次批量生成一批ID给不同的机器去慢慢消费,这样数据库的压力也会减小到N分之一,且故障后可坚持一段时间。
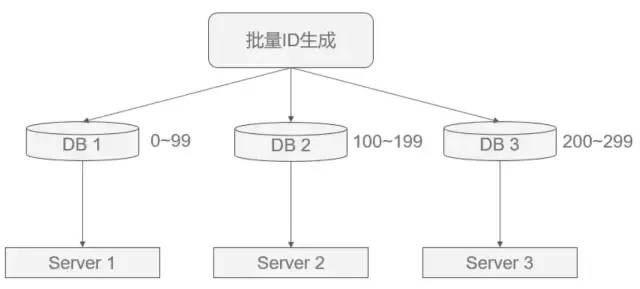
如图所示,但这种做法的缺点是服务器重启、单点故障会造成ID不连续。
还是那句话,没有最好的方案,只有最适合的方案。
3. Redis生成ID
核心思想:Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
优点:
① 不依赖于数据库,灵活方便,且性能优于数据库。
② 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
① 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
② 需要编码和配置的工作量比较大。
优化方案:
考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量,并利用上面的方案(①数据库水平拆分,设置不同的初始值和相同的步长;②批量缓存自增ID)来配置集群。
PS:比较适合使用 Redis 来生成每天从0开始的流水号。比如:“订单号=日期+当日自增长号”,则可以每天在Redis中生成一个Key,使用INCR进行累加。
二、UUID生成
核心思想:结合机器的网卡(基于名字空间/名字的散列值MD5/SHA1)、当地时间(基于时间戳&时钟序列)、一个随记数来生成UUID。
其结构如下:
aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee(即包含32个16进制数字,以连字号-分为五段,最终形成“8-4-4-4-12”的36个字符的字符串,即32个英数字母+4个连字号)。
例如:550e8400-e29b-41d4-a716-446655440000
优点:
① 本地生成,没有网络消耗,生成简单,没有高可用风险。
缺点:
① 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
② 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
③ 无序查询效率低:由于生成的UUID是无序不可读的字符串,所以其查询效率低。
◆ 到目前为止业界一共有5种方式生成UUID:
①版本1 - 基于时间的UUID(date-time & MAC address):
规则:主要依赖当前的时间戳及机器mac地址,因此可以保证全球唯一性。
优点:能基本保证全球唯一性。
缺点:使用了Mac地址,因此会暴露Mac地址和生成时间。
②版本2 - 分布式安全的UUID(date-time & group/user id):
规则:将版本1的时间戳前四位换为POSIX的UID或GID,很少使用。
优点:能保证全球唯一性。
缺点:很少使用,常用库基本没有实现。
③版本3 - 基于名字空间的UUID-MD5版(MD5 hash & namespace):
规则:基于指定的名字空间/名字生成MD5散列值得到,标准不推荐。
优点:不同名字空间或名字下的UUID是唯一的;相同名字空间及名字下得到的UUID保持重复。
缺点:MD5碰撞问题,只用于向后兼容,后续不再使用。
④版本4 - 基于随机数的UUID(pseudo-random number):
规则:基于随机数或伪随机数生成。
优点:实现简单。
缺点:重复几率可计算。机率也与随机数产生器的质量有关。若要避免重复机率提高,必须要使用基于密码学上的强伪随机数产生器来生成值才行。
⑤版本5 - 基于名字空间的UUID-SHA1版(SHA-1 hash & namespace):
规则:将版本3的散列算法改为SHA1。
优点:不同名字空间或名字下的UUID是唯一的;相同名字空间及名字下得到的UUID保持重复。
缺点:SHA1计算相对耗时。
总得来说:
①版本 1/2 适用于需要高度唯一性且无需重复的场景。
②版本 3/5 适用于一定范围内唯一且需要或可能会重复生成UUID的环境下。
③版本 4 适用于对唯一性要求不太严格且追求简单的场景。
相关伪代码如下:

三、雪花算法
核心思想:把64-bit分别划分成多段,分开来标示机器、时间、某一并发序列等,从而使每台机器及同一机器生成的ID都是互不相同。
PS:这种结构是雪花算法提出者Twitter的分法,但实际上这种算法使用可以很灵活,根据自身业务的并发情况、机器分布、使用年限等,可以自由地重新决定各部分的位数,从而增加或减少某部分的量级。比如:百度的UidGenerator、美团的Leaf等,都是基于雪花算法做一些适合自身业务的变化。
下面介绍雪花算法的几种不同优化方案:
1. Twitter的snowflake算法
核心思想是:采用bigint(64bit)作为id生成类型,并将所占的64bit 划分成多段。
其结构如下:
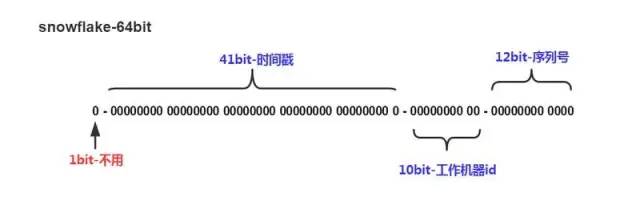

说明:
①1位标识:由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
②41位时间截(毫秒级):需要注意的是,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)得到的值,这里的开始时间截,一般是指我们的id生成器开始使用的时间截,由我们的程序来指定。41位的毫秒时间截,可以使用69年(即T =(1L << 41)/(1000 * 60 * 60 * 24 * 365)= 69)。
③10位的数据机器位:包括5位数据中心标识Id(datacenterId)、5位机器标识Id(workerId),最多可以部署1024个节点(即1 << 10 = 1024)。超过这个数量,生成的ID就有可能会冲突。
④12位序列:毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号(即1 << 12 = 4096)。
PS:全部结构标识(1+41+10+12=64)加起来刚好64位,刚好凑成一个Long型。
优点:
①整体上按照时间按时间趋势递增,后续插入索引树的时候性能较好。
②整个分布式系统内不会产生ID碰撞(由数据中心标识ID、机器标识ID作区分)。
③本地生成,且不依赖数据库(或第三方组件),没有网络消耗,所以效率高(每秒能够产生26万ID左右)。
缺点:
①由于雪花算法是强依赖于时间的,在分布式环境下,如果发生时钟回拨,很可能会引起ID重复、ID乱序、服务会处于不可用状态等问题。
解决方案有:
a. 将ID生成交给少量服务器,并关闭时钟同步。
b. 直接报错,交给上层业务处理。
c. 如果回拨时间较短,在耗时要求内,比如5ms,那么等待回拨时长后再进行生成。
d. 如果回拨时间很长,那么无法等待,可以匀出少量位(1~2位)作为回拨位,一旦时钟回拨,将回拨位加1,可得到不一样的ID,2位回拨位允许标记3次时钟回拨,基本够使用。如果超出了,可以再选择抛出异常。

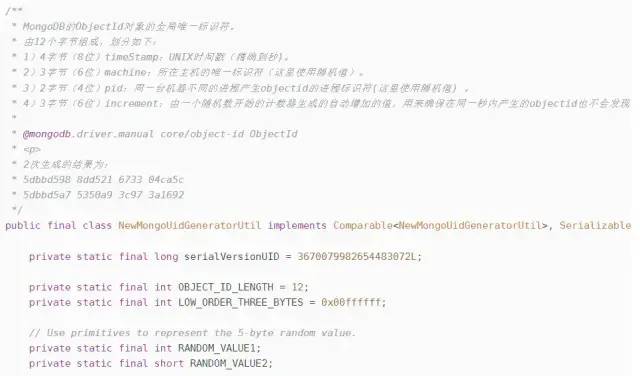
2. Mongo的ObjectId算法
核心思想是:使用12字节(24bit)的BSON 类型字符串作为ID,并将所占的24bit 划分成多段。

说明:
①4字节(8位)timeStamp:UNIX时间戳(精确到秒)。
②3字节(6位)machine:所在主机的唯一标识符(一般是机器主机名的散列值)。
③2字节(4位)pid:同一台机器不同的进程产生objectid的进程标识符 。
④3字节(6位)increment:由一个随机数开始的计数器生成的自动增加的值,用来确保在同一秒内产生的objectid也不会发现冲突,允许256^3(16777216)条记录的唯一性。
如:ObjectID(为了方便查看,每部分使用“-”分隔)格式为:5dba76a3-d2c366-7f99-57dfb0
①timeStamp:5dba76a3(对应十进制为:1572501155)。
②machine:d2c366(对应十进制为:13812582)。
③pid:7f99(对应十进制为:32665)。
④increment:57dfb0(对应十进制为:5758896)。
优点:
①本地生成,没有网络消耗,生成简单,没有高可用风险。
②所生成的ID包含时间信息,可以提取时间信息。
缺点:
①不易于存储:12字节24位长度的字符串表示,很多场景不适用。
◆ 新版ObjectId中“机器标识码+进程号” 改为用随机数作为机器标识和进程号的值
mark:从 MongoDB 3.4 开始(最早发布于 2016 年 12 月),ObjectId 的设计被修改了,中间 5 字节的值由原先的 “机器标识码+进程号” 改为用随机数作为机器标识和进程号的值。
那问题来了,为什么不继续使用“机器标识+进程号”呢?
问题就在于,在这个物理机鲜见,虚拟机、云主机、容器横行的时代,机器标识和进程号不太可靠。
①机器标识码:
ObjectId 的机器标识码是取系统 hostname 哈希值的前几位。那么问题来了,准备了几台虚拟机,hostname 都是默认的 localhost,谁都想着这玩意儿能有什么用,还得刻意给不同机器起不同的 hostname?此外,hostname 在容器、云主机里一般默认就是随机数,也不会检查同一集群里是否有hostname 重名。
②进程号:
这个问题就更大了,要知道,容器内的进程拥有自己独立的进程空间,在这个空间里只用它自己这一个进程(以及它的子进程),所以它的进程号永远都是 1。也就是说,如果某个服务(既可以是 mongo 实例也可以是 mongo 客户端)是使用容器部署的,无论部署多少个实例,在这个服务上生成的 ObjectId,第八第九个字节恒为 0000 0001,相当于说这两个字节废了。
综上,与其使用一个固定值来“区分不同进程实例”,且这个固定值还是人类随意设置或随机生成的 hostname 加上一个可能恒为 1 的进程号,倒不如每次都随机生成一个新值。
可见,这是平台层面的架构变动影响了应用层面的设计方案,随着云、容器的继续发展,这样的故事还会继续上演。
**1)旧版:使用主机名的散列值作用machine、使用进程标识符作为pid **

2)新版:使用随机数作为machine、pid的值
3. 百度UidGenerator算法 UidGenerator是百度开源的分布式ID生成器,是基于snowflake算法的实现,看起来感觉还行,但是需要借助数据库,配置起来比较复杂。
具体可以参考官网说明:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
4. 美团Leaf算法 Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
具体可以参考官网说明:https://tech.meituan.com/2017/04/21/mt-leaf.html
小结:这篇文章和大家分享了全局id生成服务的几种常用方案,同时对比了各自的优缺点和适用场景。在实际工作中,大家可以结合自身业务和系统架构体系进行合理选型。
源代码请移步到博主的CSDN博客(猿码之家) :https://blog.csdn.net/liudao51/article/details/103007892
看完本文有收获?请转发分享给更多人
往期资源: