
分布式 ID 生成方案

- 前言 -
- ID 生成方案 -
UUID/GUID
123e4567-e89b-12d3-a456-426655440000xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
"版本1" UUID 是根据时间和节点 ID(通常是MAC地址)生成; "版本2" UUID是根据标识符(通常是组或用户ID)、时间和节点ID生成; "版本3" 和 "版本5" 确定性UUID 通过散列 (hashing) 命名空间 (namespace) 标识符和名称生成; "版本4" UUID 使用随机性或伪随机性生成。
优点 容易实现,产生快 ID唯一(几乎不会产生重复id) 无需中心化的服务器 不会泄漏商业机密 缺点 可读性差 占用空间太多(16个字节) 影响数据库的性能, 比如UUID or GUID as Primary Keys? Be Careful!
- 递增的整数 -
优点 容易产生 可读性好,容易记住 存储很小,比如4个字节 缺点 需要中心化的服务器,并且需要处理单点的问题,而且单点有性能瓶颈的问题。 如果ID暴露给公共访问,可能会泄漏商业机密。比如最近浑水报告通过统计销售小票推断出某商业模式的每日单量。 需要访问一次数据库获取ID
- 随机数 -
优点 可读性高 占用存储小,4个字节就可以了 随机,不会泄漏信息 缺点 同样需要中心化的服务,有单点问题和性能问题 需要两步,先产生递增的ID,再进行随机加密
- 随机字符串 -
优点 短,5个字符(字节)就可以表示10亿个ID。 可读性高 随机,不会泄漏信息 缺点 ID可能不唯一,需要检查和处理
- Twitter的snowflake算法 -
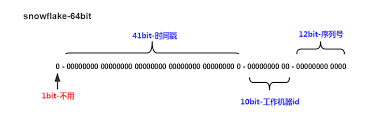
优点 存储少, 8个字节 可读性高 性能好,可以中心化的产生ID,也可以独立节点生成 缺点 时间回拨会重复产生ID ID生成有规律性,信息容易泄漏
- MongoDB ObjectID -

优点 可读性高 性能好,可以中心化的产生ID,也可以独立节点生成 缺点 占用存储较多 时间回拨会重复产生ID ID生成有规律性,信息容易泄漏
- 分布式 ID 生成器服务 did -
1、256个client并发,每次只获取1个ID, ID的产生速度是 12万个ID/秒。./bclient -addr 192.168.15.225:8972 -n 100000total IDs: 25600000, duration: 3m31.581592489s, id/s: 1209932、如果采用批量获取,尽量减少网络消耗,256个client并发,每次只获取100个ID, ID的产生速度是 297万个ID/秒。./bclient -addr 192.168.15.225:8972 -n 1000000 -b 100total IDs: 256000000, duration: 1m26.178942509s, id/s: 2970563
https://www.simpleorientedarchitecture.com/7-strategies-for-assigning-ids/ https://www.callicoder.com/distributed-unique-id-sequence-number-generator/ https://juejin.im/post/5b3a23746fb9a024e15cad79 https://tech.meituan.com/2017/04/21/mt-leaf.html https://i6448038.github.io/2019/09/28/snowflake/ https://soulmachine.gitbooks.io/system-design/content/cn/distributed-id-generator.html https://juejin.im/post/5bb0217ef265da0ac2567b42 https://chai2010.cn/advanced-go-programming-book/ch6-cloud/ch6-01-dist-id.html https://zh.wikipedia.org/zh-hans/%E9%80%9A%E7%94%A8%E5%94%AF%E4%B8%80%E8%AF%86%E5%88%AB%E7%A0%81 https://zhuanlan.zhihu.com/p/46404167
作者:smallnest
来源:
https://colobu.com/2020/02/21/ID-generator/

评论