
Delta 解析 | Delta 2.0如何实现对Apache Flink的支持?
共 6178字,需浏览 13分钟
·
2022-08-25 08:41
6月30日,Databricks在Data+AI Summit大会上官宣了Delta 2.0的完全开源,其中特别强调了三件事:
代码已经全部捐献给Linux基金会。 Delta现在支持Flink,Trino(Presto)等Spark以外计算引擎的读写。 Delta还支持python,rust,ruby等jvm系以外的语言直接读写,甚至不需要任何大数据组件。
一个月以后,Delta 2.0终于和众多翘首以盼的社区用户见面。在《Delta 2.0的源码解析》这篇文章的开头,我罗列了这个大版本的所有功能和改进点。
在Delta 2.0的官方Release Note里,提到Delta 2.0正式包括的功能主要是以下几项:
Change Data Feed(CDF) Z-Order clustering 支持幂等性写入 支持字段的drop操作 支持动态的分区覆写(只覆写一部分分区) 支持checkpointing时并发写入多个parquet文件(用于提高checkpointing的性能)
可能眼尖的朋友会发现,怎么好像完全没有提到对Flink的支持?
其实Delta 2.0对Flink,Trino等其他计算引擎的支持,并非实现在Delta自己的代码库里,而是以另一种“曲线救国”的方式来实现的。这篇文章就来讲一讲其中的原理。
Delta支持Flink的历程
其实直到今年以前,Databricks官方对于Flink等Spark以外的计算引擎的支持,还必须借助Spark才能完成。例如在今年2月官方博客的一篇文章《Using Apache Flink With Delta Lake》中,Databricks推荐的方式就是“Flink首先把数据写入s3,然后用Databricks Autoloader(一个基于Spark Streaming的产品)把数据写入Delta Lake里面”,大概说来就是这样一个架构
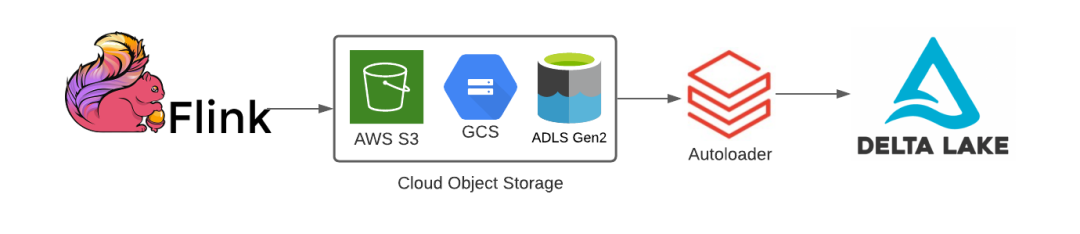
负责写入的代码如下,可以看到实际写入Delta的还是Spark。
flink_parquet_to_delta_silver = (spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "parquet")
.schema(flink_parquet_schema)
.load(data_path)
.withColumn("date", date_format(col("dt"), "yyyy-MM-dd")) # use for partitioning the downstream Delta table
.withColumnRenamed("dt", "timestamp")
.writeStream
.format("delta")
.option("checkpointLocation", checkpoint_path)
.partitionBy("date")
.start(delta_silver_table_path)
)
但可能是为了给Delta 2.0铺路,从今年的年初开始,Databricks就认真地考虑起支持Flink这件事来。
然而现实是Delta因为代码和Spark深度绑定(详见之前的文章《谈一谈Delta Lake的原理》),很难基于Delta的代码库实现对Flink的支持,于是Databricks就想到了另一个项目——Delta Standalone。
Delta Standalone是Databricks在2020年12月开源的一个库,库如其名,这个库最主要的功能就是可以让用户无需Spark也能使用Delta的数据。不过在这之前,这个库的能力还仅限于“只读”,而且只是一个通用的Java/Scala接口,并没有专门适配Flink,换言之需要用户自己在Flink端调用这个库,自己实现读写逻辑,使用体验很差。
直到今年4月初,Databricks把Delta Standalone扩展为Delta Connectors框架,并且发布了Flink/Delta Sink Connector,正式支持了Flink写入Delta。而在8月11日,也就是上周,发布了最新的0.5.0版本,新增了Flink读取Delta的Source Connector。至此,Delta Connectors算是比较完整地实现了原生Flink读写Delta的能力,兑现了Databricks在Data+AI Summit上的承诺。
下面就来讲一讲Delta Connectors的原理。
Delta Connectors的原理
上文提到,Delta自身很难实现的Flink读写的能力,那Delta Connectors是如何实现的呢?
首先Delta Connectors的基础是Delta Standalone,读写Delta的能力都是由这个库提供的。而Delta Standalone的实现原理,简单来说就是“提供对Delta的元数据DeltaLog的操作接口,允许用户直接读取,更新DeltaLog”。
如果用户想读取Delta里面的数据,那么他首先会从DeltaLog里获得他要读取的snapshot,以及这个snapshot具体包括哪些parquet文件,然后用户就可以直接读取这些parquet文件。
反之,如果用户想写入数据到Delta,那么他需要把数据写入成为新的parquet文件,然后调用DeltaLog的commit方法,将这些新的parquet文件的元数据写入到Delta里面。这样就完成了对Delta的写入。
以上是Delta Standalone最初开源时,Databricks对这个库的定位。但在时间进入2022年以后,Databricks调整了战略,把Delta Standalone升级成为Delta Connectors,实际上做的事情就是把这些复杂的读写逻辑进一步封装成为各个计算引擎的原生接口,让用户可以开箱即用。
以Flink为例,现在用户不需要直接和DeltaLog打交道,只需要以下不到10行代码,就可以把任意的stream写入Delta里面。
public DataStream<RowData> createDeltaSink(DataStream<RowData> stream,
String deltaTablePath, RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
Delta Standalone的优缺点
个人觉得,用Delta Standalone解决Delta强耦合Spark的问题,实现对其他计算引擎(甚至其他语言,例如Delta的rust读写库delta-rs也是类似的思想)的支持,这个思路还是比较巧妙的。
但是Delta Standalone本质上是绕过了Delta的读写接口,重新实现了一遍读写逻辑。这种方式可以解决一些问题,但同时也不可避免地会带来另一些问题。其中有一个问题就是,如何保证两套读写逻辑的一致性?
事实上目前的Delta Connectors也确实存在这个问题,主要表现为Delta的有些功能还没有移植到Delta Connectors上面来,例如
Update和Conditional Update MergeInto Change Data Feed
读过之前文章的朋友们应该都清楚,这些功能是通过特殊的读写逻辑实现的,因此暂时还没来得及移植到Delta Connectors上面来。
长期来看,要保持Delta和Delta Connectors的一致也是极具挑战性的一件事。需要Databricks投入很多资源才能做到。
不过从积极的角度来说,Delta Connectors毕竟让更多系统可以和Delta集成,扩大了Delta的生态系统。而且因为Flink现在可以读取Delta的数据了,提供了“读取Delta的数据,在Flink上实现业务逻辑”这种可能性。