
RFE筛选出的特征变量竟然是Boruta的4倍之多
RFE算法实战
rfe函数有 4 个关键参数:
x: 训练集数值矩阵 (不包含响应值或分类信息)y: 响应值或分类信息向量sizes: 一个整数向量,设定需要评估的变量子集的大小。默认是
2^(2:4)。rfeControl: 模型评估所用的方法、性能指标和排序方式等。
一些模型有预定义的函数集可供使用,如linear regression (lmFuncs), random forests (rfFuncs), naive Bayes (nbFuncs), bagged trees (treebagFuncs)和其它可用于train函数的函数集。
# 因运行时间长,故存储起运行结果供后续测试
library(caret)
if(file.exists('rda/rfe_rffuncs.rda')){
rfe <- readRDS("rda/rfe_rffuncs.rda")
} else {
subsets <- generateTestVariableSet(ncol(train_data))
# rfFuncs
control <- rfeControl(functions=rfFuncs, method="repeatedcv", number=10, repeats=5)
rfe <- rfe(x=train_data, y=train_data_group, size=subsets, rfeControl=control)
saveRDS(rfe, "rda/rfe_rffuncs.rda")
}
print(rfe, top=10)##
## Recursive feature selection
##
## Outer resampling method: Cross-Validated (10 fold, repeated 5 times)
##
## Resampling performance over subset size:
##
## Variables Accuracy Kappa AccuracySD KappaSD Selected
## 1 0.7152 0.2585 0.1740 0.3743
## 2 0.7990 0.4464 0.1595 0.4398
## 3 0.8341 0.5143 0.1342 0.4096
## 4 0.8387 0.5266 0.1362 0.4231
## 5 0.8678 0.6253 0.1359 0.4080
## 6 0.8937 0.6790 0.1285 0.4095
## 7 0.8906 0.6796 0.1320 0.4031
## 8 0.8995 0.6939 0.1175 0.3904
## 9 0.8803 0.6343 0.1309 0.4234
## 10 0.9017 0.7036 0.1186 0.3847
## 16 0.9250 0.7781 0.1066 0.3398
## 25 0.9223 0.7663 0.1151 0.3632
## 27 0.9318 0.7927 0.1094 0.3483
## 36 0.9356 0.7961 0.1123 0.3657
## 49 0.9323 0.7895 0.1128 0.3649
## 64 0.9356 0.8076 0.1123 0.3488
## 81 0.9385 0.8193 0.1083 0.3305
## 100 0.9356 0.8076 0.1123 0.3488
## 125 0.9356 0.8095 0.1123 0.3478
## 216 0.9394 0.8129 0.1149 0.3650 *
## 256 0.9361 0.8044 0.1155 0.3656
## 343 0.9219 0.7516 0.1247 0.4062
## 512 0.9288 0.7799 0.1239 0.3933
## 625 0.9266 0.7790 0.1165 0.3658
## 729 0.9252 0.7567 0.1278 0.4211
## 1000 0.9259 0.7681 0.1272 0.4077
## 1296 0.9181 0.7313 0.1250 0.4183
## 2401 0.8787 0.5666 0.1285 0.4639
## 4096 0.8787 0.5701 0.1252 0.4525
## 6561 0.8521 0.4619 0.1221 0.4510
## 7070 0.8623 0.4987 0.1268 0.4635
##
## The top 10 variables (out of 216):
## HG4074.HT4344_at, D55716_at, U63743_at, M63835_at, L42324_at, X02152_at, D31887_at, D82348_at, X17620_at, U56102_at绘制下模型的准确性随选择的重要性变量的数目的变化
plot(rfe, type=c("g", "o"))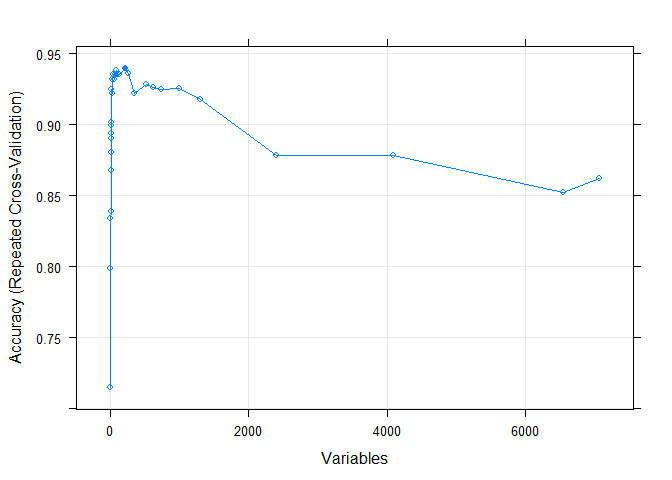
可以使用predictors函数提取最终选定的最小关键特征变量集,也可以直接从rfe对象中提取。
predictors(rfe)## [1] "HG4074.HT4344_at" "D55716_at" "U63743_at"
## [4] "M63835_at" "L42324_at" "X02152_at"
.
.
## [211] "U30872_at" "Y09392_s_at" "U21090_at"
## [214] "U17032_at" "D00763_at" "HG3075.HT3236_s_at"存储起来用于跟Boruta鉴定出的特征变量比较
caretRfe_variables <- data.frame(Item=rfe$optVariables, Type="Caret_RFE")比较Boruta与RFE筛选出的特征变量的异同
Boruta筛选出的特征变量Confirmed都在RFE筛选的特征变量中,Tentative的只有1个未被RFE筛选的特征变量覆盖。
vairables <- rbind(boruta.finalVars, boruta.finalVarsWithTentative, caretRfe_variables)
library(VennDiagram)
library(ImageGP)
sp_vennDiagram2(vairables, item_variable = "Item", set_variable = "Type", manual_color_vector ="Set1")
这些特征变量最终用于评估模型的效果怎样呢? 下期分晓!
机器学习系列教程
从随机森林开始,一步步理解决策树、随机森林、ROC/AUC、数据集、交叉验证的概念和实践。
文字能说清的用文字、图片能展示的用、描述不清的用公式、公式还不清楚的写个简单代码,一步步理清各个环节和概念。
再到成熟代码应用、模型调参、模型比较、模型评估,学习整个机器学习需要用到的知识和技能。
评论