
坑苦操作系统的x86处理器,到底哪里难做?

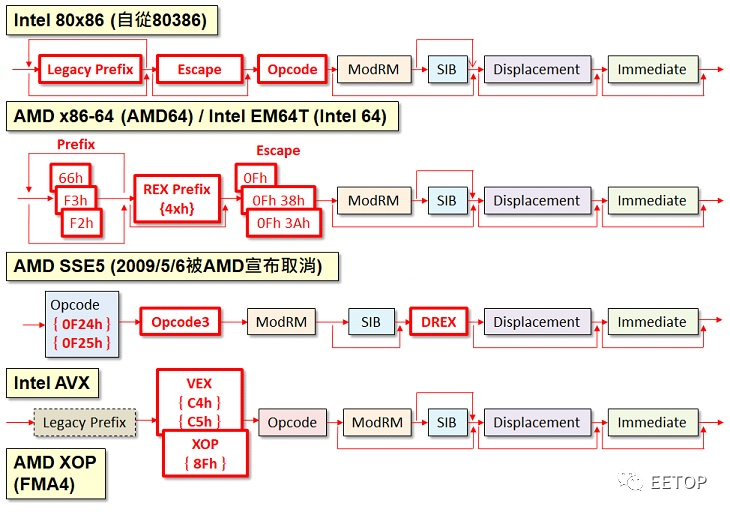
相信各位一直会有相同疑惑:为何今天的x86 处理器市场,台面上只剩下英特尔和AMD 两家美国公司?顶多再加个存在感稀薄的台湾VIA,和少人知悉的俄罗斯Elbrus?对技术有点基础认知的人,多少会直接想到「x86 指令集很复杂很难搞,又有英特尔的授权问题,所以x86 处理器非常不好做」之类的标准答案。
1、信创专题(二).pdf
2、信创专题(一).pdf
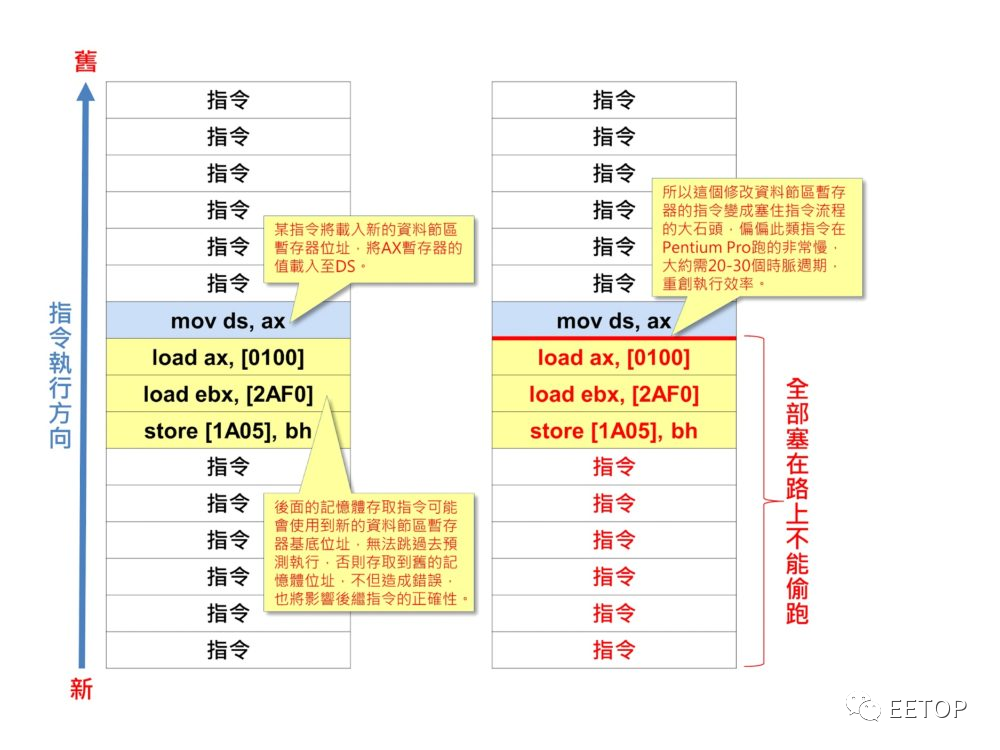
「x86 处理器走向高效能化」。 「x86 开始与RISC 正面竞争」。 「x86 指令集的缺陷让厂商感到棘手」。 「x86 处理器进军多处理器平台」。 「个人电脑市场因Windows 95 的问世而蓬勃成长」。 「笔记本电脑即将逐渐普及」。 「英特尔默默埋下让擅长改良的以色列海法研发团队,主导x86 处理器技术发展」。 「x86指令集的兼容性,成为其他竞争者的潜在障碍,也造成软件开发商的困扰」。

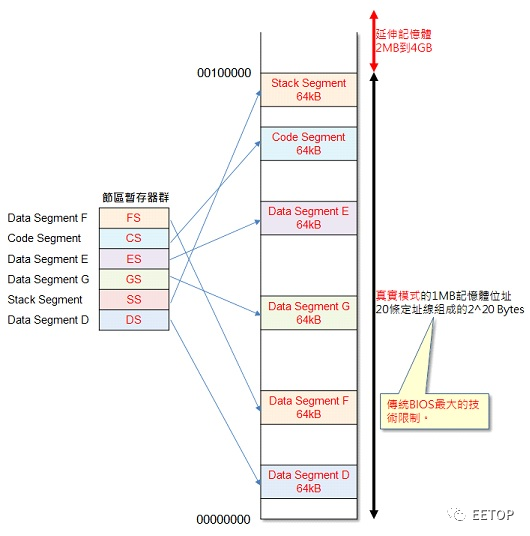



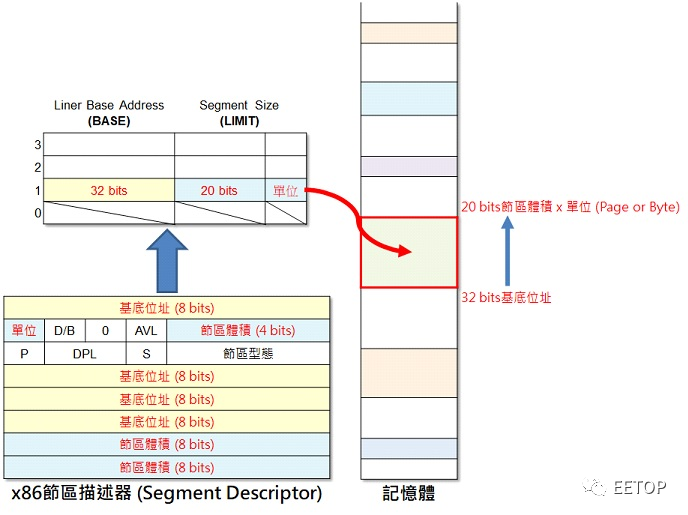
32 位元基底值(Base)。 20 位元范围值(Limit)。 范围值单位Page 或Byte(前者上限4GB,后者则1MB)。 针对堆叠(Stack)数据结构的向下扩展(Expand-Down)栏位。
分配、协调各I/O 周边装置存取处理器需求的能力,发出中断(Interrupt)时,知道该由哪个处理器负责:标准化的中断处理机制。 快取存储器数据一致性协定(Cache Coherence Protocol):回写式(Write-Back)快取存储器常见的MESI(Modified, Exclusive, Shared, Invalid)协议。 低成本多处理器系统的根基:可让多处理器共享的系统总线。
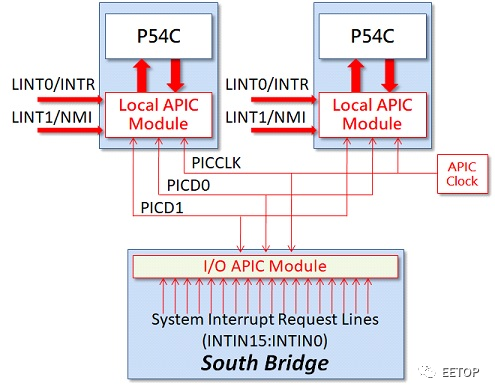
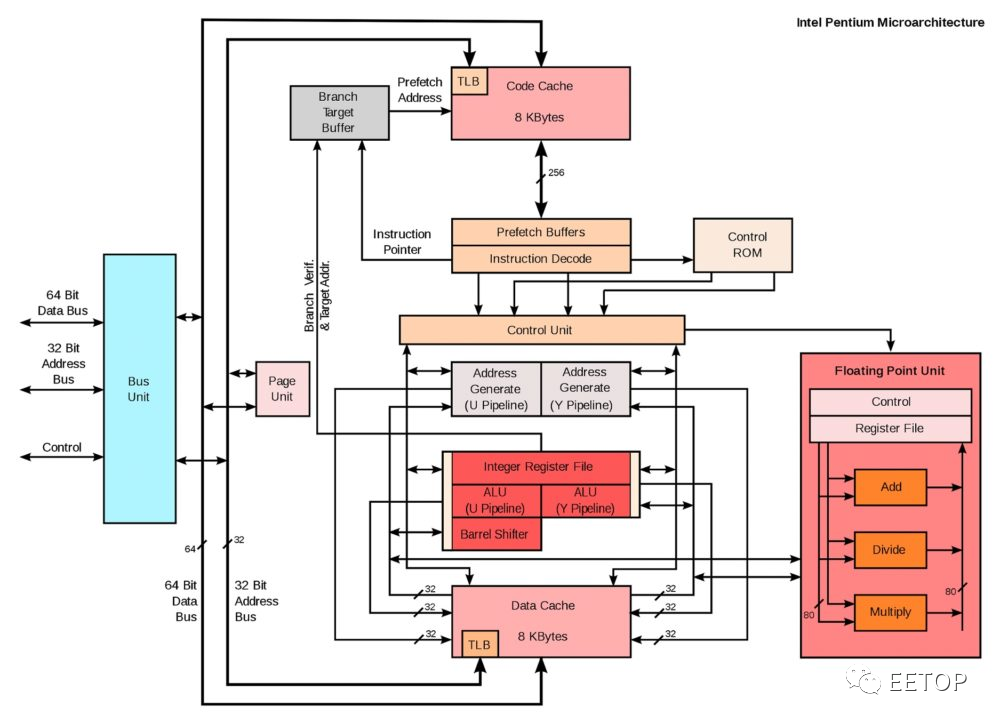
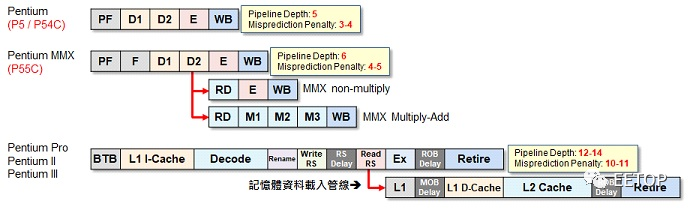
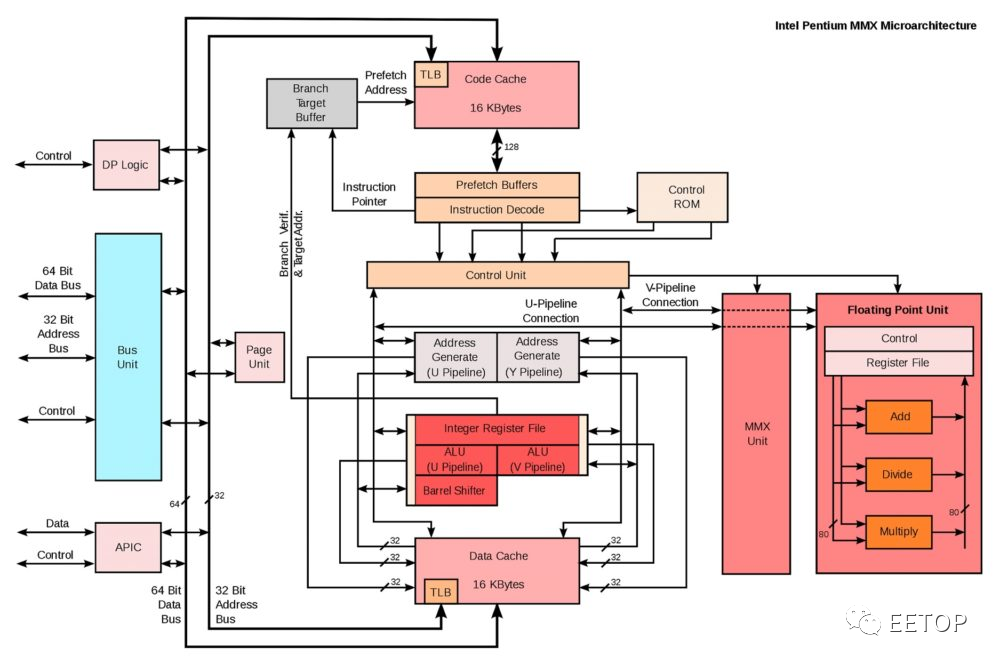
 不过初代Pentium 并未内建Local APIC,同时期系统芯片组也没有I/O APIC,要打造多颗Pentium 平台,每一颗Pentium 需外挂一颗单价高达26 美元、兼具Local APIC 与I/OAPIC 两者功能的82498DX,I/O 也需动用一颗。换句话说,双处理器系统就需要用到3 颗,怎么看都不算便宜,还会占用不少主机板空间。
不过初代Pentium 并未内建Local APIC,同时期系统芯片组也没有I/O APIC,要打造多颗Pentium 平台,每一颗Pentium 需外挂一颗单价高达26 美元、兼具Local APIC 与I/OAPIC 两者功能的82498DX,I/O 也需动用一颗。换句话说,双处理器系统就需要用到3 颗,怎么看都不算便宜,还会占用不少主机板空间。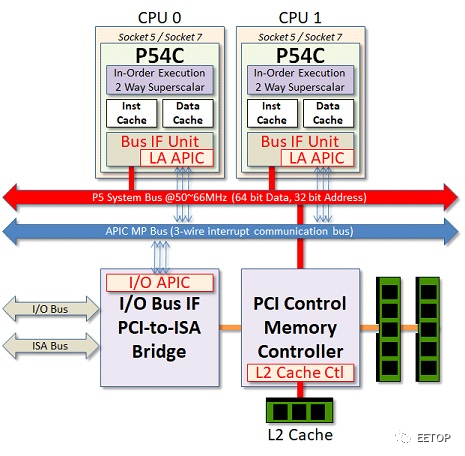
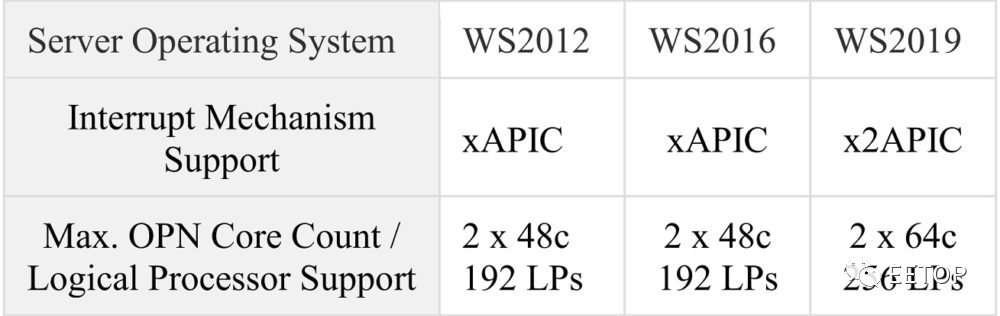
APIC:Pentium和Pentium Pro(与Pentium II、Pentium III、P6核心的Xeon)动用Local APIC的ID寄存器24-27四个位元,16进位的0xF(10进位制的15)用做广播,所以2 4 −1=15。 xAPIC:Pentium 4到Penryn用到Local APIC的ID寄存器24-31八个位元,16进位的0xFF(10进位制的255)用做广播,所以2 8 −1=255。 x2APIC:Nehalem开始使用存于MSR(Model-Specific Register)的32位元x2APIC ID,16进位的0xFFFFFFFF(10进位制的4294967295)用做广播,所以2 32 −1=4294967295。

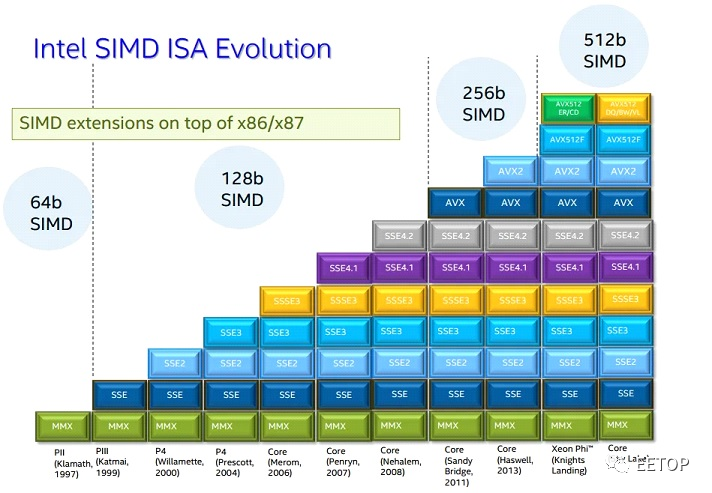
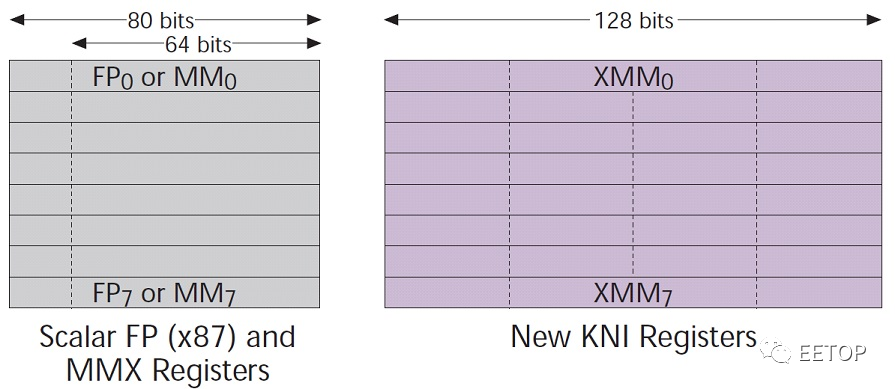
MultiMedia eXtension Multiple Math eXtension Matrix Math eXtension

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。

评论