
图像编码与 H264 基础知识
RGB 颜色模型
图像的采集可以通过摄像头或者截取屏幕来获取的图像数据。一幅图像可以看作为一个二维的矩阵,其中矩阵中的每一个点被称为像素。像素的颜色可以通过红、绿、蓝来表示,也就是常说的 3 基色。如下图所示:
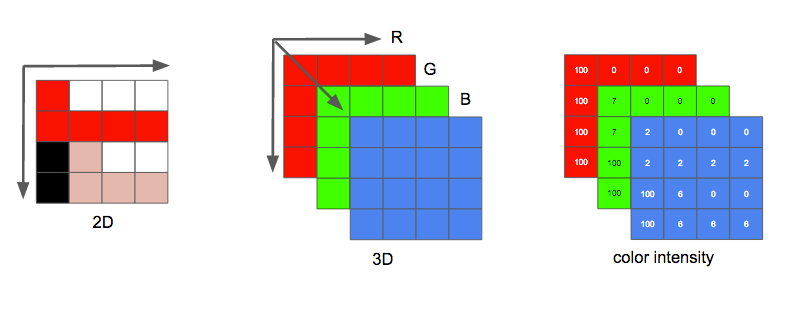
每个像素可以用不同的数据位数来表示,常用的量化位数有 16 位、24 位、32 位等。
24 位最好理解,就是 RGB 的各个分量各占 8 位,取值范围为 0 ~ 255;
32 位则是 24 位的基础上增加了透明度的量化位数,也是 8 位,用来表示当前像素的透明度,根据透明的位置可以分为 RGBA 和 ARGB;
16 位可以分为 565 和 555 两种模式,565 则表示绿色分量占 6 位,红色和蓝色各占 5 位,555 模式则丢弃一位不用,RGB 各个分量占 5 位。量化位数越多,所能表示颜色的层次也越多,颜色则越丰富。
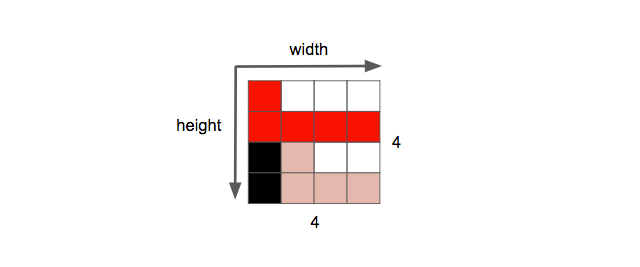
在表示图像的二维的矩阵中,宽和高两个维度中像素的数量称为分辨率,通常用 宽 x 高 来表示,例如下面分辨率为 4 x 4 的图像。
图像还有另一个属性就是宽高比,例如常见的 16:9、4:3、21:9 等,这里通常指显示宽高比(DAR),同样像素也有不同的宽高比,称之为像素长宽比(PAR)。

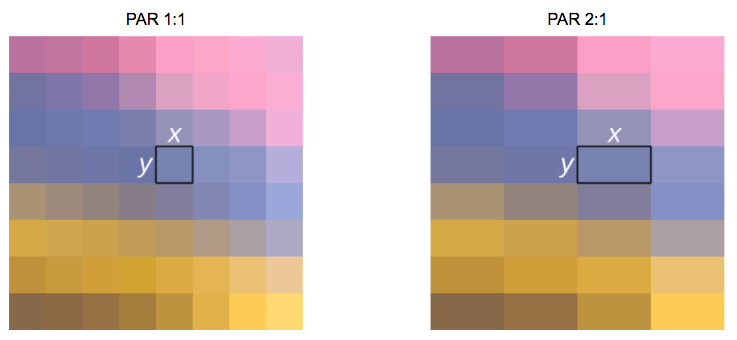
YUV 颜色模型与冗余删除
一张 1280x720 分辨率的图片,如果使用 RGB 颜色模型存储话,24 位量化位数的情况下需要 1280 720 3(24bit) = 2.6M 空间来存储一张图片,如果是 32 位则需要 1280 720 4(24bit) = 3.5M 存储空间,而我们的眼睛对于亮度相比于颜色更敏感,例如一下图片:

区域 A 与区域 B,是相同的颜色,第一张很难区分出来,这跟我们人眼的构造相关,人眼更加注意光线明亮度。
所以针对这一特点存在另一种颜色模型 YUV 颜色模型,YUV 颜色模型中,其中的 Y 分量表示的是明亮度(Luminance、Luma), U、V 表示的是色度 (Chrominance/Chroma),如下图:

该模型下可以采用不同的量化位数来表示亮度以及色度,所以存在不同到模式:4:4:4、4:2:2、4:1:1、4:2:0、4:1:0 和 3:1:1 六种不同的模式。
在使用 4:2:0 模式时,同样的图片相比 RGB 模式,所用的内存减少一半。RGB 可以和 YUV(YCbCr)进行转换,公式如下:
# 第一步计算亮度
Y = 0.299R + 0.587G + 0.114B
# 一旦有了亮度,可以分割颜色(色度蓝色和红色):
Cb = 0.564(B - Y)
Cr = 0.713(R - Y)
# 也可以通过使用 YCbCr 进行转换,甚至获得 RGB
R = Y + 1.402Cr
B = Y + 1.772Cb
G = Y - 0.344Cb - 0.714Cr
采样率、码率、帧以及场的概念
图像则是对模拟信号进行采样量化后获得,而视频则是由一系列的图像组成,采集时图像的分辨率及量化位数越高,所能表达的信息越多,画面则越清晰。
视频存在一个采样频率的属性,即单位时间内采样的次数。视频的采样频率也受人眼的限制,通常在每秒 20 ~ 30 帧之间。
当采样频率在每秒 10~20 帧时,对于快速运动的图像,人眼可以感觉到不流畅,而采样频率提高到 20~30 帧时,人眼看起来比较流畅了。
如果将采样频率在提高,人眼是很难感觉这种差异的,这也是目前电影拍摄时使用 24 帧或者 30 帧采样频率的原因。
显示视频所需要的每秒位数称作为比特率,也叫码率。
计算公式为 比特率=宽 高 位深度 每秒帧数 例如,如果我们不采用任何类型的压缩,每秒 30 帧,每像素 24 位,480x240 分辨率的视频将需要 82,944,000 位/秒 或 82.944 Mbps(30x480x240x24)。
当比特率几乎恒定时,称为恒定比特率(CBR),但它也可以变化,然后称为可变比特率(VBR)。
下图显示了一个受限的 VBR,在帧为黑色时不会花太多位。

视频采样中通过逐行扫描得到一幅完整的图像称之为一帧,通常帧频率为 25 帧(PAL 制)、30 帧每秒(NTSC 制),而通过隔行扫描(奇、偶数行),那么一帧图像就被分成两场,通常场频为 50Hz(PAL 制)、60Hz(NTSC 制)。
这是在早期,工程师们提出的一种技术,能够在不消耗额外的带宽的情况下,使得显示器的感知帧率倍增。这种技术称为隔行视频;它基本上在 1 帧中发送一半的屏幕,而在下一帧中发送另一半。

今天视频的显示主要使用逐行扫描技术。逐行是显示、存储或发送运动图像的方法,其中每帧的所有行被依次绘制。
H264 编码
当需要存储视频或者网络传输时,无论是使用 RGB 还是 YUV 格式,所需要的码率和存储空间都是非常大的,例如一个分辨率为 1280 x 720 ,24 位量化位数,采样频率为每秒 30 帧,一个小时的视频则需要 1280 x 720 x 3 x 30 x 60 x 60 = 278G 的空间来存储该视频。
而在显示或网络传输该视频时所需要的码率为 1280 x 720 x 24 x 30 = 632Mbps,这么大数据量很难实际应用,因为网络带宽和硬盘存储空间都是非常有限的。
针对以上问题则需要对视频进行编码压缩,而 H264 是其中一种编解码标准;
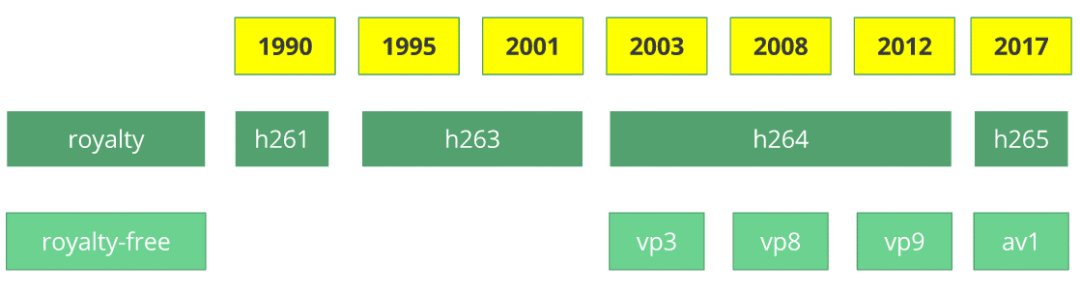
H264 由视频编解码器 H.261 发展而来的,它诞生于 1990 年(技术上为 1988 年),其设计工作的数据速率为 64 kbit / s。它已经使用了色度子采样,宏块等方面的想法。在 1995 年,H.263 视频编解码器标准被公布,并持续延续至 2001 年。
2003 年,第一版 H.264/AVC 完成。同一年,一家名为 TrueMotion 的公司将其视频编解码器作为免版税的有损视频压缩称为 VP3。2008 年,Google 收购了该公司,同年发布了 VP8。2012 年 12 月,Google 发布了 VP9, 大约有 3/4 的浏览器市场(包括手机)支持。
AV1 是一种新的视频编解码器,免版税并且开放源代码,由 AOMedia 联盟设计,该组织包括:谷歌,Mozilla,微软,亚马逊,Netflix,AMD,ARM,NVIDIA,英特尔,思科等等,编解码器的第一个版本 0.1.0 于 2016 年 4 月 7 日发布。
H264 编解码方法
去除数据统计冗余:H264 采用两种熵编码方式:CAVLC ( 基于上下文的可变字长编码)和 CABAC(基于上下文的二进制算数编码),CAVLC 实现相对简单,编码效率高,但压缩率要比 CABAC 低 15% 左右,CABAC 复杂度高,可以分场景采用不同的熵编码,让视频压缩后的平均码长接近信源熵值。
去除空间冗余:去除空间冗余则仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩,跟编码 jpeg 差不多。
除此以外,H264 采用变换编码的方式,将残差从空间域利用 DCT(离散余弦变换)变换到频率域,结合差异量化编码方式,更进一步的去除空间冗余。
去除时间冗余:相邻几帧的数据有很大的相关性,或者说前后两帧信息变化很小的特点。也即连续的视频其相邻帧之间具有冗余信息,根据这一特性,压缩相邻帧之间的冗余量就可以进一步提高压缩量,减小压缩比。帧间压缩也称为时间压缩(Temporal compression),它通过比较时间轴上不同帧之间的数据进行压缩。
帧间压缩一般是无损的。帧差值(Frame differencing)算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
去除人眼视觉冗余:H264 编码器的输入图像或视频的色彩空间采样格式一般为 YUV420,不同于 RGB 采样,YUV420 利用人眼视觉对像素亮度分量更敏感,而色度分量没那么敏感,进一步将图像或视频的色度分量做 2:1 的采样,4 个亮度分量,2 个色度分量。
另外,H264 采用量化编码的有损编码方式,也正是利用了人眼视觉对高频细节部分不敏感的理论基础,将残差系数低频部分采用更细的量化参数,而高频部分则粗化量化,一般的视频压缩失真也正是这个阶段产生。
除了以上是 H264 所使用的技术,还使用了以下方法:
帧分组(GOP):在 H264 中图像以序列为单位进行组织,一个序列是一段图像编码后的数据流,以 I 帧开始,到下一个 I 帧结束。当运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个 I 帧,然后一直 P 帧、B 帧了,可以有效的降低码率。
当运动变化多时,一个序列就需要设置的比较小,比如就包含一个 I 帧 和 3、4 个 P 帧,这样可以控制 P 帧和 B 帧的大小。
帧类型的定义:将每组内各帧图像定义为三种类型,即 I 帧(IDR)、B 帧和 P 帧;I 帧是帧内编码帧,I 帧表示关键帧,可以理解为这一帧画面的完整保留, I 帧特点:
它是一个全帧压缩编码帧。它将全帧图像信息进行 JPEG 压缩编码及传输; 解码时仅用 I 帧的数据就可重构完整图像; I 帧描述了图像背景和运动主体的详情; I 帧不需要参考其他画面而生成; I 帧是 P 帧和 B 帧的参考帧,其质量直接影响到同组中以后各帧的质量; I 帧是帧组 GOP 的基础帧(第一帧),在一组中只有一个 I 帧; I 帧不需要考虑运动矢量; I 帧所占数据的信息量比较大。
P 帧是前向预测编码帧。P 帧表示的是这一帧跟之前的一个关键帧(或 P 帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。P 帧是以 I 帧或 P 帧为参考帧,在参考帧中找出 P 帧的差异 P 帧特点:
P 帧采用运动补偿的方法传送它与前面的 I 或 P 帧的差值及运动矢量(预测误差); 解码时必须将 I 帧中的预测值与预测误差求和后才能重构完整的 P 帧图像; P 帧属于前向预测的帧间编码,它只参考前面最靠近它的 I 帧 或 P 帧; P 帧可以是其后面 P 帧的参考帧,也可以是其前后的 B 帧 的参考帧; 由于 P 帧是参考帧,它可能造成解码错误的扩散; 由于是差值传送,P 帧的压缩比较高。
B 帧是双向预测内插编码帧。B 帧是双向差别帧,也就是 B 帧记录的是本帧与前后帧的差别,换言之,要解码 B 帧不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B 帧以前面的 I 或 P 帧 和后面的 P 帧为参考帧,B 帧特点:
B 帧是由前面的 I 或 P 帧和后面的 P 帧来进行预测的; B 帧传送的是它与前面的 I 或 P 帧和后面的 P 帧之间的预测误差及运动矢量; B 帧是双向预测编码帧; B 帧压缩比最高,因为它只反映丙参考帧间运动主体的变化情况,预测比较准确; B 帧不是参考帧,不会造成解码错误的扩散。
I、P、B 各帧是根据压缩算法的需要,是人为定义的,它们都是实实在在的物理帧。 一般来说,I 帧的压缩率是 7(跟 JPG 差不多),P 帧是 20,B 帧可以达到 50。 B 帧的使用会导致解码的延时,因为需要参考前后帧,同时也会增加 CPU 负担。 P 帧和 B 帧不会越过 I 帧(IDR 图像)去参考其他帧。
H264 的编码参数
H264 的编码的实现存在很多的控制参数,不同的编码器实现可能有一些特殊的参数可供设置,不同的控制参数得到不同的输出结果,以便适应不同的应用场景,这里介绍一些通用的参数,后续在介绍一些具体编码器以及应用时,在对一些参数进行详细的说明。
H.264 Profiles:Profile 用于确定编码过程中帧
间压缩使用的算法,常见的 H264 编码 Profile 有如下 3 种:
1、Baseline Profile (BP):只支持 I/P 帧,无交错(Progressive)和 CAVLC,主要用于计算能力有限的应用环境,一般用于低阶或需要额外容错的应用,比如视频通话、手机视频等;优势:编解码开销较小,速度快,适用于视频会议等延时敏感的场景或者解码能力不够的环境。不足:同等码率下,Baseline 的画质最差。
2、Main Profile (MP):支持 I/P/B 帧,无交错(Progressive)和交错(Interlaced),同时提供对于 CAVLC 和 CABAC 的支持,用于主流消费类电子产品规格如低解码(相对而言)的 MP4、便携的视频播放器;
优势:CABAC 的支持和 B 帧的引入,相同码率下画质相对 Baseline 有 15% 的提升。不足:运算量上和画质相对于 HiP 没有太大优势,绝大部份情况下已经被 HiP 取代。
3、High Profile (HiP):在 Main 的基础上增加了 8x8 内部预测、自定义量化、无损视频编码和更多的 YUV 格式(如 4:4:4)用于广播,高清电视及视频碟片存储(HiP 被采纳为 HD DVD 和蓝光的编码标准)。
优势:8x8 内部预测的引入使得 HiP 能够较好的编码快速移动的场景、支持码流之间有效的切换(SP 和 SI 片)、改进误码性能。
CAVLC 和 CABAC 是两种不同的熵编码(一种无损,变长编码数据压缩方案)形式,CAVLC 效率高压缩比低,CABAC 反之。
除此之外还存一下类别:
High 10 Profile (Hi10P):超越目前主流的消费型产品能力,此 profile 建立在 High Profile 之上,多了支援 10 bit 的精度,色彩更精准。以影片压制而言,将 High Profile (8 bit) 影片重新编码输出为 H.264 High 10 Profile ,虽然色彩精度不会变,但至少压缩率比输出 High Profile (8 bit) 还要高。
High 4:2:2 Profile (Hi422P):针对专业领域应用,此 profile 建立在 High 10 Profile 之上,多了支援 4:2:2 色彩取样,位元深度达 10 bit。
High 4:4:4 Predictive Profile (Hi444PP):此 profile 建立在 High 4:2:2 Profile 之上,多了支援 4:4:4 色彩取样,位元深度达 14 bit,并且支援高效率无损重新编码,且每张画面编码为三个独立的色彩平面。
H.264 Level:Level 是对视频本身特性的一些描述(码率,分辨率,fps 等),Level 越高,视频的码率、分辨率、fps 越高。Level 也表示了对播放设备的解码性能要求,值越高,代表播放设备解码性能要求越高,相对的输出影片的压缩率也越越高。
关于 Profile 和 Level 更详细资料可参考 WiKi 百科的 H.264/MPEG-4 AVC 资料。
地址:https://en.wikipedia.org/wiki/Advanced_Video_Coding
GOP 长度:一个 key frame (IDR) 到下一个 key frame 的范围。表示关键帧的间隔,一个序列的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧 图像。当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR 图像之后的图像永远不会使用 IDR 之前的图像的数据来解码。
Constant Quantizer (QP):恒定量化值(Constant Quantizer)可以用来控制图像编码的品质。编码器中一般可以这是最大值和最小值。比较低的数值会得到比较高的品质。
Maximun B-frame:当设定 B 帧时,重复部分比较多/变化较少的 Frames 会被编码为 B 帧此值限制 B 帧的最大连续数量。
Reference frame (ref):设定一个 P 帧所能参考的帧的数量,ref 会影响播放相容性。
码率控制(Bitrate Control):CBR(恒定码率)、VBR(动态码率);码率控制实际上是一种编码的优化算法,它用于实现对视频流码流大小的控制。
目的在于同样的视频编码格式,码流大,它包含的信息也就越多,那么对应的图像也就越清晰,反之亦然。
VBR 码流控制方式可以降低图像动态画面少时候的带宽占用,CBR 控制方式码流稳定,图像状态较稳定。他们为了解决的是不同需求下的不同应用。
来源:http://www.enkichen.com/2017/11/26/image-h264-encode/
技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。
私信领取相关资料
推荐阅读:
觉得不错,点个在看呗~
