
智能问答系统CQA调研--工业界

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
1 任务
“技术需求”与“技术成果”项目之间关联度计算模型(需求与成果匹配)
cMedQA2 (医疗问答匹配)
智能客服问题相似度算法设计——第三届魔镜杯大赛
CCKS 2018 微众银行智能客服问句匹配大赛
AFQMC 蚂蚁金融语义相似度
OPPO手机搜索排序query-title语义匹配数据集
医疗问题相似度衡量竞赛数据集(医疗问题匹配、意图匹配)
1.1 任务定义
1.2 任务分类
1.3 评测标准
1.4 数据集
2 方法及模型
2.1.1 规则匹配
2.1.2 无监督文本表示
2.1.3 用于跨领域迁移学习方法
2.1 无监督方法
2.2 有监督匹配算法
FAQ发现
FAQ答案优化
表示型模型
交互型模型
Siamese networks模型
DSSM 模型
Sentence Bert
MatchPyramid模型
ESIM (Enhanced LSTM)
2.2.1 基于意图识别的算法
2.2.2深度文本匹配模型
2.3 FAQ发现与优化
3 产品案例
产品1 百度AnyQ--ANswer Your Questions
产品2:腾讯知文--结构化FAQ问答 引擎
产品3: 阿里小蜜
4 总结
5 相关资料
1 任务
1.1 任务定义
Community Question Answer,中文名称是社区问答。是利用半结构化的数据(问答对形式)来回答用户的提问,其流程通常可以分为三部分。
问题解析,对用户输入的问题进行分词,纠错等预处理步骤。
召回部分,利用信息检索引擎如Lucence等根据处理后的问题提取可能的候选问题。
排序部分,利用信息检索模型对召回的候选问题进行相似度排序,寻找到最相似的问题并返回给用户。
1.2 任务分类
通常,根据应用场景的不同,可以将CQA任务分为两类:
FAQ问答: 在智能客服的业务场景中,对于用户频繁会问到的业务知识类问题的自动解答(以下简称为FAQ)是一个非常关键的需求,可以说是智能客服最为核心的用户场景,可以最为显著地降低人工客服的数量与成本。这个场景中,知识通常是封闭的,而且变化较为缓慢,通常可以利用已有的客服回复记录提取出高质量的问答对作为知识库。
社区问答: 问答对来自于社区论坛中用户的提问和回答,较为容易获取,但是相对质量较低。而且通常是面向开放域的,知识变化与更新速度较快。
1.3 评测标准
查全率:用以评价系统对于潜在答案寻找的全面程度。例如:在回答的前30%中保证一定出现正确答案。
查准率:即准确率,top n个答案包含正确答案的概率。这一项与学术界一致。
问题解决率:与具体业务和应用场景紧密相关
用户满意度/答案满意度:一般对答案满意度的评价方式是在每一次交互后都设置一个评价,客户可以对每一次回答进行评价,评价该答案是否满意。但是这样的评价方式容易让客户厌烦,因为客户是来解决问题的,不是来评价知识库里面的答案是否该优化。
问题识别率/应答准确率:指智能客服机器人正确识别出客户的问题数量在所有问题数中的占比。目前业内评价智能机器人比较常用的指标之一。
问题预判准确率:指用户进入咨询后,智能客服机器人会对客户可能咨询的问题进行预判。如京东的问题预判,是通过其长期数据积累和模型给每个用户添加各种标签,可以提供更个性化和人性化的服务。例如,京东JIMI了解用户的性别、情绪类型、近期购买历史等。当用户开始交流时,就会猜到他可能要询问一个关于母婴商品的使用方法或是一个售后单的退款情况,这就是问题预判。如果预判准确的话,只需在几次甚至一次的交互中获得智能客服机器人专业的问题解答,从而缩短客户咨询时长。
意图识别准确率:要想解答用户的问题,机器人首先需要结合上下文环境,从用户提问中准确识别用户咨询的意图是什么,然后返回对应的答案。
拦截率:机器人代替人工解决的用户咨询比例
24H未转人工率:指客户咨询了智能机器人后的24H内是否有咨询人工客服
1.4 数据集
由于工业界的数据集通常来自其自身业务的记录,并不对外公开,故以下只举例介绍相关比赛中出现的数据集:
“技术需求”与“技术成果”项目之间关联度计算模型(需求与成果匹配)
任务目标
根据项目信息的文本含义,为供需双方提供关联度较高的对应信息(需求——成果智能匹配
数据来源
数据来自中国·河南开放创新暨跨国技术转移大会云服务平台(www.nttzzc.com)
人工标注关联度的方法:从事技术转移工作的专职工作人员,阅读技术需求文本和技术成果文本,根据个人经验予以标注。关联度分为四个层级:强相关、较强相关、弱相关、无相关。
数据具体说明:https://www.datafountain.cn/competitions/359/datasets
评价指标:使用MAE系数
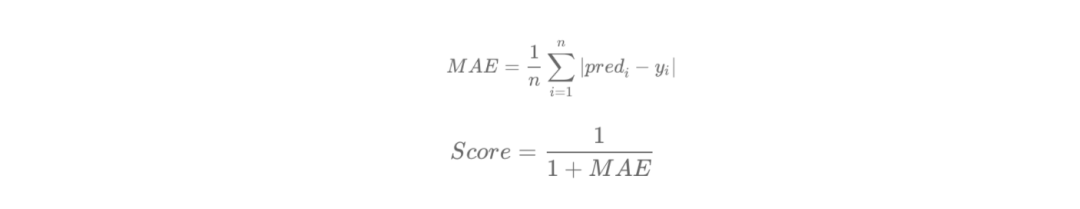
最终结果越接近1分数越高。
平均绝对差值是用来衡量模型预测结果对标准结果的接近程度一种衡量方法.MAE的值越小,说明预测数据与真实数据越接近。
top1方案及结果
解决方案:https://www.sohu.com/a/363245873_787107
主要利用数据清洗、数据增广、孪生BERT模型
平安医疗科技疾病问答迁移学习比赛(疾病问句匹配)
任务目标
针对中文的疾病问答数据,进行病种间的迁移学习。具体是给定来自5个不同病种的问句对,要求判定两个句子语义是否相同或者相近。简单描述是语义匹配问题
数据来源
所有语料来自互联网上患者真实的问题,并经过了筛选和人工的意图匹配标注。
数据分布及说明
训练集,包含2万对人工标注好的疾病问答数据,由5个病种构成,其中diabetes10000对,hypertension、hepatitis、aids、breast_cancer各2500对
验证集,包含10000对无label的疾病问答数据,由5个病种构成,各2000对
测试集,包含5万对人工标注好的疾病问答数据,其中只有部分数据供验证。
具体说明:https://www.biendata.com/competition/chip2019/data/
给参赛选手的文件由train.csv、dev.csv、test.csv三个文件构成
评价指标
Precision、Recall、F1值
top1方案及结果
解决方案:https://zhuanlan.zhihu.com/p/97227793
主要利用基于BERT与提升树模型的语义匹配方法
最高得分:0.88312
CAIL2019相似案例匹配大赛(法律文书匹配)
任务目标
“中国裁判文书网”公开的民间借贷相关法律文书,每组数据由三篇法律文书组成。文书主要为案件的事实描述部分,选手需要从两篇候选集文书中找到与询问文书案件性质更为相似的一篇文书。
数据具体说明
链接:同上述比赛链接
内容:对于每份数据,用三元组(A,B,C)来代表该组数据,其中A,B,C均对应某一篇文书。文书数据A与B的相似度总是大于A与C的相似度的,即sim(A,B)>sim(A,C)
数据量:比赛第一阶段训练数据有500组三元文书,第二阶段有5102组训练数据,第三阶段为封闭式评测
评价指标:acc
top1方案及结果
解决方案:https://www.leiphone.com/news/201910/Yf2J8ktyPE7lh4iR.html
主要利用损失函数为 Triplet Loss 的 Rank 模型来解决三元组的相对相似的问题、只提取并采用三个文书文本特征、基于Bert的多模型离线的多模型融合、解决Triple Loss 过拟合
最高得分:71.88
代码:https://github.com/GuidoPaul/CAIL2019
智能客服问题相似度算法设计——第三届魔镜杯大赛
任务目标
计算客户提出问题与知识库问题的相似度
数据来源
智能客服聊天机器人真实数据
数据分布及描述
https://ai.ppdai.com/mirror/goToMirrorDetail?mirrorId=1
评价指标:logloss,logloss分数越低越好
方案及结果
主要利用传统特征(如最长公共子序列、编辑距离等),结构特征(构造图结构。将q_id作为node,(qi,qj)作为edge,得到一个单种边的同构图,然后计算qi,qj的公共边权重和等结构),还有半监督、相似传递性、早停优化等
rank6方法(rank6结果0.145129,top1结果0.142658)
CCKS 2018 微众银行智能客服问句匹配大赛
任务目标
针对中文的真实客服语料,进行问句意图匹配
数据来源
所有语料来自原始的银行领域智能客服日志,并经过了筛选和人工的意图匹配标注。
数据具体说明:https://biendata.com/competition/CCKS2018_3/data/
评价指标:Precision、Recall、F1值、ACC
top1评测论文:An Enhanced ESIM Model for Sentence Pair Matching with Self-Attention
AFQMC 蚂蚁金融语义相似度
任务目标
给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义
数据来源
所有数据均来自蚂蚁金服金融大脑的实际应用场景。
数据分布
初赛阶段提供10万对的标注数据作为训练数据,包括同义对和不同义对,可下载;复赛阶段不提供下载
具体说明:链接
评测指标:F1-score为准(得分相同时,参照accuracy排序)
top1解决方案:链接。
主要利用char-level feature、ESIM 模型、ensemble
OPPO手机搜索排序query-title语义匹配数据集
数据集链接:https://pan.baidu.com/s/1Hg2Hubsn3GEuu4gubbHCzw (密码7p3n)
数据来源
该数据集来自于OPPO手机搜索排序优化实时搜索场景, 该场景就是在用户不断输入过程中,实时返回查询结果。该数据集在此基础上做了相应的简化, 提供了一个query-title语义匹配。
数据分布
初赛数据约235万 训练集200万,验证集5万,A榜测试集5万,B榜测试集25万
具体说明:https://tianchi.aliyun.com/competition/entrance/231688/information
评测指标:F1 score 指标,正样本为1
top1 解决方案
答辩链接:链接(00:42开始)
https://tianchi.aliyun.com/course/video?spm=5176.12586971.1001.83.1770262auKlrTZ&liveId=41001
主要应用:数据预处理、CTR问题的特征挖掘、TextCNN&TF-IDF、attention net、数据增强、回归CTR模型融合lightGBM、阈值选择。(rank 1,rank2两只队伍都是使用了lightGBM模型和模型融合)
最后得分:0.7502
医疗问题相似度衡量竞赛数据集
比赛链接:
任务目标:针对中文的真实患者健康咨询语料,进行问句意图匹配。给定两个语句,要求判定两者意图是否相同或者相近
数据来源
来源于真实问答语料库,该任务更加接近于智能医疗助手等自然语言处理任务的实际需求
所有语料来自互联网上患者真实的问题,并经过了筛选和人工的意图匹配标注。
数据分布
训练集包含20000条左右标注好的数据(经过脱敏处理,包含标点符号),供参赛人员进行训练和测试。
测试集包含10000条左右无label的数据(经过脱敏处理,包含标点符号)
具体描述:链接
评测指标:Precision,Recall和F1值。最终排名以F1值为基准
2 方法及模型
2.1 无监督方法
2.1.1 规则匹配
目前,流行的问答系统中依旧大量应用着规则匹配的方法。基于规则的方法拥有可解释性强,易于控制,效率高,易于实现,不需要标注数据等优势。针对FAQ库中的标问和相似问进行分词、应用正则表达式等方法提炼出大量的概念,并将这些概念进行组合,构成大量的句式,句式再进行组合形成标问。
例如,标问“华为mate30现在的价格是多少?”,拆出来“华为mate30”是cellphone概念,“价格是多少”是askMoney概念,“现在”是time概念,那么“华为mate30现在的价格是多少?”就是cellphone+askMoney+time。用户输入"华为mate30现在卖多少钱?"进行分词,可以得到相同的句式和概念组合,就能够命中“华为mate30现在的价格是多少?”这个相似问了。
在基于规则的匹配中, 如何进行规则的自动发现与更新、检验与评估是最关键的问题。究其原因, 由人工维护的产生式规则需要高水平的、具备丰富的领域知识的专家.在问答系统所应用的领域较为狭窄时, 这有可能得到满足。然而, 随着问答系统涉及知识的广度和深度不断提高, 依赖于专家知识对管理规则的难度也大为提高。
2.1.2 无监督文本表示
在缺少标记数据的场景,我们可以利用算法对文本本身进行表示,再利用常用的向量距离计算方法(如余弦距离,欧式距离等)进行相似性度量。常见的无监督文本表示方法主要可以分为两种,一种是基于词频信息的方法,一种是基于词向量的方法。
基于词频信息的方法:传统的文本表示方法通常是基于词频特征的,例如TF-IDF,语言模型等。
TF-IDF:将文档表示为其每个单词的TF-IDF值向量形式,并通过计算两个文本向量表示的余弦相似度来衡量其相似性。
语言模型:根据现有的文本对每个单词由一篇文档生成的概率根据词频进行建模,将一段文本由另一段文本生成的概率作为其相似度得分。
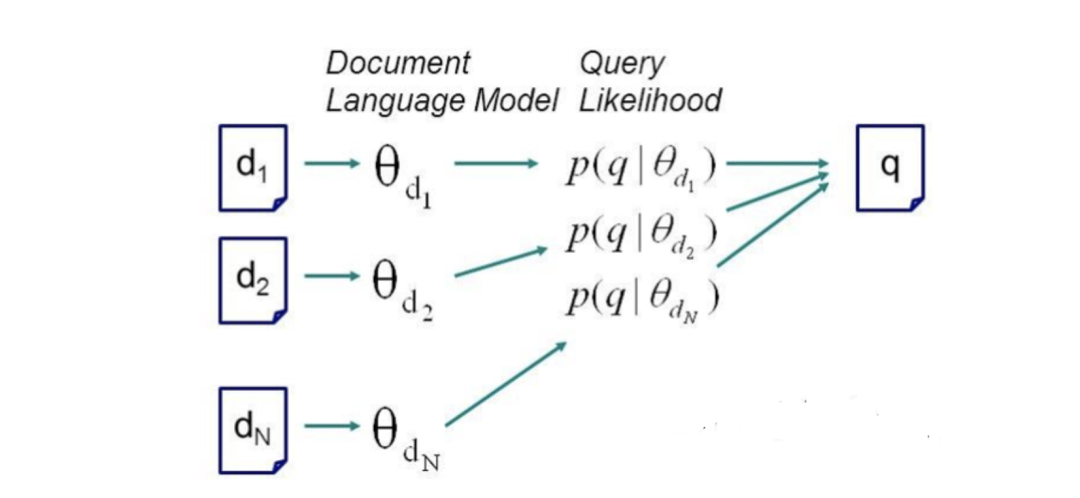
基于浅层语义的方法,这些方法对文档的浅层语义分布进行建模,用来估计文档的生成概率,如PLSA,LDA等。
PLSA
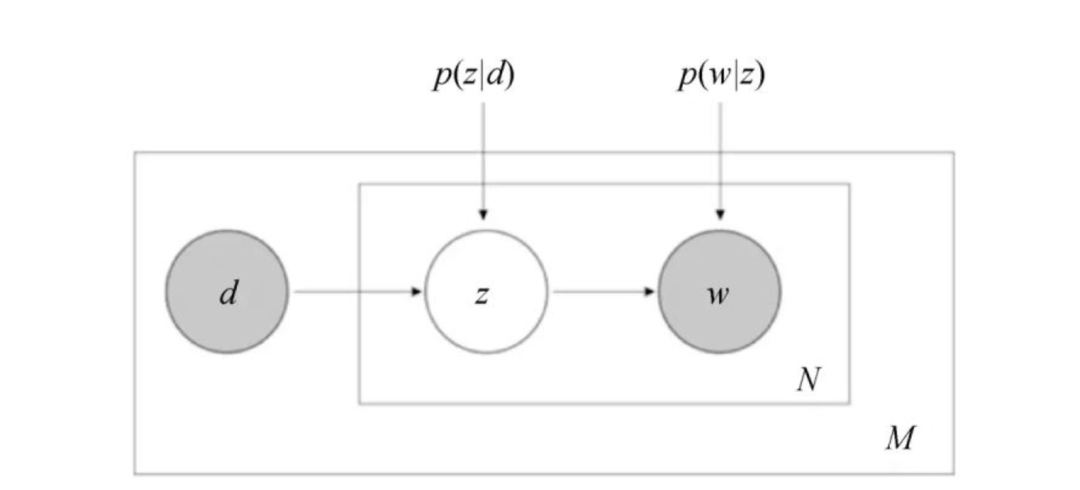
PLSA假设整个词频矩阵服从多项式分布,并引入了主题(z)的概念。假设每篇文章都由若干主题构成,每个主题的概率是p(z|d),在给定主题的条件下,每个词都以一定的概率p(w|z)产生。这样就能解决多义词的分布问题。这种分析的基础仍然是文档和词的共现频率,分析的目标是建立词/文档与这些潜在主题的关系,而这种潜在主题进而成为语义关联的一种桥梁。其概率图模型如下:
其中p(z|d)和P(w|z)是需要学习的参数。P(z|d)参数数目是主题数和文档数乘的关系,p(w|z)是词表数乘主题数的关系,参数空间很大,容易过拟合。
LDA
如果说pLSA是频度学派代表,那LDA就是贝叶斯学派代表。LDA通过引入Dirichlet分布作为多项式共轭先验,在数学上完整解释了一个文档生成过程,其概率图模型如图所示。
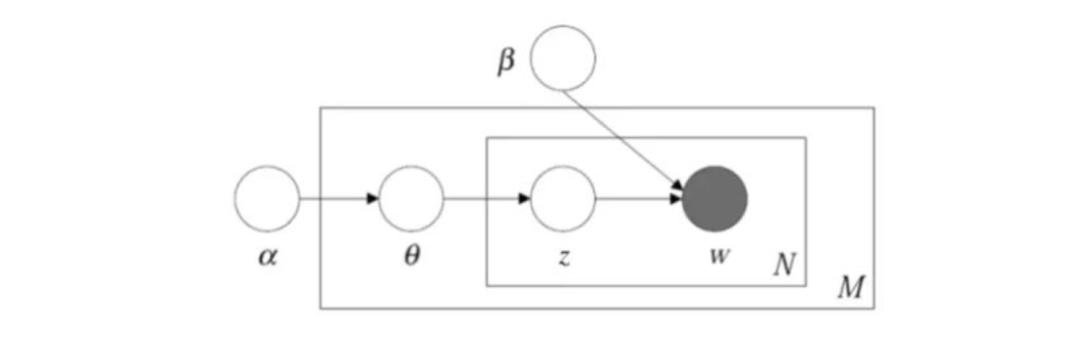
我们可以看出LDA中每篇文章的生成过程如下:
和pLSA不太一样,LDA概率图模型引入了两个随机变量α和β,它们就是控制参数分布的分布,即文档-主题符合多项式分布。这个多项式分布的产生受Dirichlet先验分布控制,这样就解决了PLSA参数量过大的问题。
选择单词数N服从泊松分布,N~Possion(β)。
文档θ服从狄利克雷分布,θ~Dir(α)。
对于文档内N个单词中的每个单词 a. 选择一个主题z,服从多项分布Mult(θ) b. 以概率p(w|z,β)生成单词w,其中p(w|z,β)表示在主题z上的条件多项式概率。
基于词向量的方法:word embedding技术如word2vec,glove等已经广泛应用于NLP,极大地推动了NLP的发展。既然词可以embedding,句子也可以。该类算法通常是基于词袋模型的算法,如TF-IDF加权平均,SIF等。
SIF
发表于2016年的论文A simple but tough-to-beat baseline for sentence embeddings提出了一种非常简单但很有一定竞争力的句子向量表示算法。算法包括两步,第一步是对句子中所有的词向量进行加权平均,得到平均向量;第二步是移出(减去)在所有句子向量组成的矩阵的第一个主成分上的投影。
第一步主要是对TFIDF加权平均词向量表示句子的方法进行改进。论文提出了一种平滑倒词频 (smooth inverse frequency, SIF)方法用于计算每个词的加权系数,具体地,单词的权重为a/(a+p(w)),其中a为平滑参数,p(w)为(估计的)词频。直观理解SIF,就是说频率越低的词在当前句子出现了,说明它在句子中的重要性更大,也就是加权系数更大。对于第二步,通过移出所有句子的共有信息,因此保留下来的句子向量更能够表示本身并与其它句子向量产生差距。
WMD
WMD是一种基于word embeddings 计算两个文本间的距离,即测量一个文本转化为另一个文本的最小距离。其将文本距离度量问题转化为一个最优传输(translation)问题。
Word2Vec得到的词向量可以反映词与词之间的语义差别,WMD距离即对两个文档中的任意两个词所对应的词向量求欧氏距离然后再加权求和。
2.1.3 用于跨领域迁移学习方法
背景
随着近年来NLP的发展,研究发现,有监督的方法虽然准确率高,但是有标数据的获取成本太高,因此迁移学习的效果越来越凸显出来,并在各种NLP(包括短文本相似度)场景出现了革命性进展
一种机器学习的方法。指的是一个预训练的模型被重新用在另一个任务中,一般两种任务之间需要有一定的相似性和关联性
迁移学习
为什么要迁移学习
模型有两种
在实际的商业应用中主要以supervised的迁移学习技术为主,同时结合深度神经网络(DNN)。
在这个设定下主要有两种框架:
Fully-Shared Model:用于比较相似的两个领域。
Specific-Shared Model:用于相差较大的两个领域。
unsupervised:假设完全没有目标领域的标注数据
supervised:假设仅有少部分目标领域的标注数据。
2.2 有监督匹配算法
2.2.2 问题意图分类--深度学习多分类模型(CNN\DNN\LSTM\…)
问答匹配任务在大多数情况下可以用意图分类解决,如先匹配用户问题意图,然后给出对应意图的答案。进而问答匹配任转化为二分类或多分类任务。
工业真正的场景中,用户问题的问题个数是不固定的,所以会把最后一层Softmax更改为多个二分类模型。模型图如下:
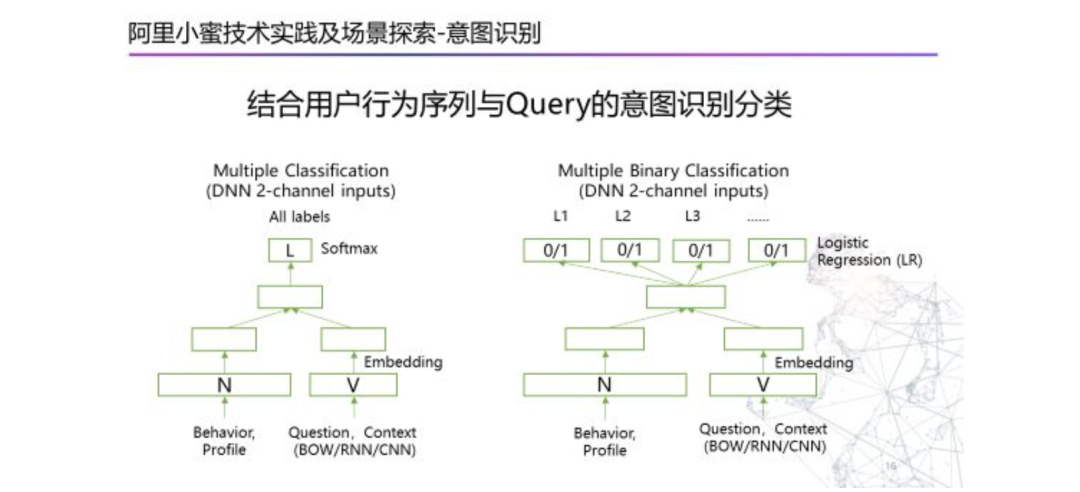
2.2.2深度文本匹配模型
一般来说,深度文本匹配模型分为两种类型,表示型和交互型。
表示型模型
表示型模型更侧重对表示层的构建,它首先将两个文本表示成固定长度的向量,之后计算两个文本向量的距离来衡量其相似度。这种模型的问题是没有考虑到两个句子词级别的关联性。容易失去语义焦点。
Siamese networks模型
Siamese networks(孪生神经网络)是一种相似性度量方法,内部采用深度语义匹配模型(DSSM,Deep Structured Semantic Model),该方法在检索场景下使用点击数据来训练语义层次的匹配。
Siamese networks有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
基于Siamese networks神经网络架构,比如有Siamese结构的LSTM、CNN和ESIM等。
DSSM 模型
论文地址:Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
模型简介
先把 query 和 document 转换成 BOW 向量形式,然后通过 word hashing 变换做降维得到相对低维的向量,feed给 MLP 网络,输出层对应的低维向量就是 query 和 document 的语义向量(假定为 Q 和 D)。计算(D, Q)的余弦相似度后,用 softmax 做归一化得到的概率值是整个模型的最终输出,该值作为监督信号进行有监督训练。
Sentence Bert
论文地址:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
模型简介
Sentence BERT(Sbert) 网络是通过 SNLI 数据集(标注了一对句子之间的关系,可能是蕴含、矛盾或者中立)进行预训练。模型使用孪生网络,即两个一模一样共享参数的Bert网络进行推理。首先将第一个句子输入到BERT,通过不同的Pooling方法获得句子的Embedding表示,第二个句子同样如此,然后将这两个Embedding变换后通过Softmax输出这对句子之间关系的概率进行训练(类似分类问题)。在训练完毕后,就可以将下面的BERT和pooling层拿出来,将句子输入得到其Embedding,再进行其他操作(比如计算相似度可以直接使用余弦)。
原始的Bert模型如果要为一个句子寻找最相似的句子,需要两两计算其相似度,这样的时间消耗是n的平方级别的。Sentence Bert可以首先计算出每个句子的向量表示,然后直接计算句子间的相似度,这样可以将时间消耗减少到O(n)的级别,同时论文中的实验证明这样的方法并没有降低模型的效果。
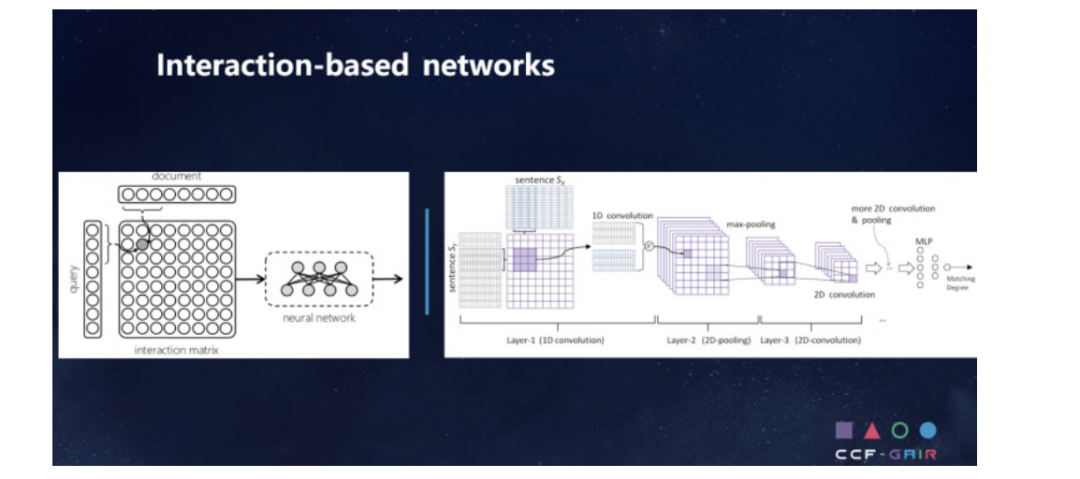
交互型模型
交互型模型认为全局的匹配度依赖于局部的匹配度,在输入层就进行词语间的先匹配,之后利用单词级别的匹配结果进行全局的匹配。它的优势是可以很好的把握语义焦点,对上下文重要性合理建模。由于模型效果显著,业界都在逐渐尝试交互型的方法。
MatchPyramid模型
论文地址:Text Matching as Image Recognition
模型简介
先将文本使用相似度计算构造相似度矩阵,然后CNN网络来提取特征。
模型可以学习到Down the ages(n-gram特征),noodles and dumplings与dumplings and noodles(打乱顺序的n-term特征)、were famous Chinese food和were popular in China(相似语义的n-term特征)
层次化卷积步骤 - 1.Ai和Bj距离度量方式:完全一样 (Indicator),余弦相似度 (Cosine),点乘 (Dot Product)。- 2.卷积,RELU激活,动态pooling(pooling size等于内容大小除以kernel大小) - 3.卷积核第一层分别算,第二层求和算。可以见下图33的kernel分别算,24*4求和算。- 4.MLP拟合相似度,两层,使用sigmoid激活,最后使用softmax,交叉熵损失函数。
ESIM (Enhanced LSTM)
论文地址:Enhanced LSTM for Natural Language Inference
源码:链接
模型简介
Enhanced LSTM for Natural Language Inference(ESIM)是2017年提出的一个文本相似度计算模型,是一种转为自然语言推断而生的加强版LSTM,由原文中知这种精心设计的链式LSTM顺序推理模型可以胜过以前很多复杂的模型。ESIM的模型主要包括3个部分:编码层,推理层和预测层。
编码层:采用BiLSTM(双向LSTM)对输入的两个句子分别编码。
推理层:模型的核心部分,首先计算两个句子和另外句子相关的表示向量,然后计算该向量和原始向量的点积,差值等。之后利用各种不同的池化方式得到最后的句子表示,将两个句子的表示拼接,得到预测层的输出v。
预测层:在这一层中,本模型将上述得到的固定长度向量 v,连接两层全连接层,第一层采用tanh激活函数,第二层采用softmax激活函数,最后得到文本蕴含的结果。

2.3 FAQ发现与优化
FAQ发现
将用户问句进行聚类,对比已有的FAQ,发现并补足未覆盖的知识点。将FAQ与知识点一一对应。
FAQ的拆分与合并
FAQ拆分是当一个FAQ里包含多个意图或者说多种情况的时候,YiBot后台会自动分析触达率较高的FAQ,聚类FAQ对应的问句,按照意图将其拆分开来。
FAQ合并
最终希望希望用户的每一个意图能对应到唯一的FAQ,这样用户每次提问的时候,系统就可以根据这个意图对应的FAQ直接给出答案。而如果两个FAQ意思过于相近,那么当用户问到相关问题时,就不会出现一个直接的回答,而是两个意图相关的推荐问题,这样用户就要再进行一步选择操作。这时候YiBot就会在后台同样是分析触达率较高的FAQ,分析哪一些问句总是被推荐相同的答案,将问句对应的意图合并。
淘汰机制
分析历史日志,采用淘汰机制淘汰废弃知识点,如已下线业务知识点等。
FAQ答案优化
挖掘对话,进行答案优化
如果机器人已经正确识别意图但最后仍然转人工,说明知识库的答案不对,需要进一步修正这一类知识点相对应的答案。
分析头部场景,回答应用文本、图片、自动化解决方案等多元化方式
比如在电商场景中,经常会有查询发货到货时间、订单状态等的场景。利用图示指引、具体订单处理等方式让用户操作更便捷。
3 产品案例
产品1 百度AnyQ--ANswer Your Questions
简介
AnyQ开源项目主要包含面向FAQ集合的问答系统框架、文本语义匹配工具SimNet。
FAQ问答系统框架
AnyQ系统框架主要由Question Analysis、Retrieval、Matching、Re-Rank等部分组成。
框架中包含的功能均通过插件形式加入,如Analysis中的中文切词,Retrieval中的倒排索引、语义索引,Matching中的Jaccard特征、SimNet语义匹配特征,当前共开放了20+种插件。
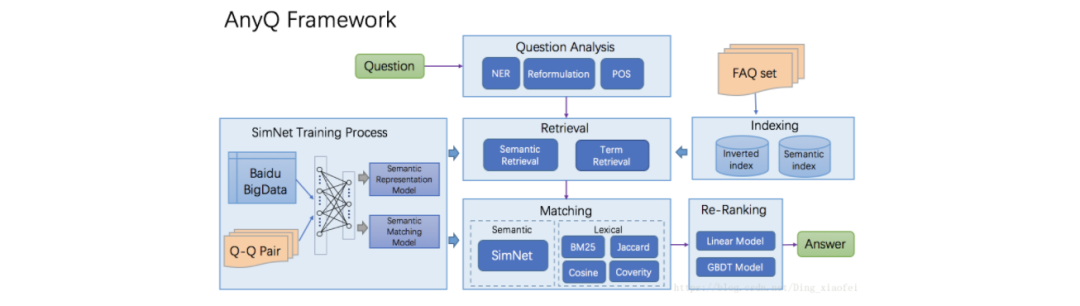
特色
AnyQ 使用 SimNet 语义匹配模型构建文本语义相似度,克服了传统基于字面匹配方法的局限,增强 AnyQ 系统的语义检索和语义匹配能力。
语义检索技术将用户问题和 FAQ 集合的相似问题通过深度神经网络映射到语义表示空间的临近位置,检索时,通过高速向量索引技术对相似问题进行检索。
AnyQ 系统AnyQ 系统集成了检索和匹配的丰富插件,通过配置的方式生效;以相似度计算为例,包括字面匹配相似度 Cosine、Jaccard、BM25 等,同时包含了语义匹配相似度。
用户自定义插件只需实现对应的接口即可,如 Question 分析方法、检索方式、匹配相似度、排序方式等。
框架设计灵活,插件功能丰富
极速语义检索
SimNet 语义匹配模型:
其他:针对无任何训练数据的开发者,AnyQ 还包含了基于百度海量数据训练的语义匹配模型,开发者可零成本直接使用。
产品2: 腾讯知文--结构化FAQ问答引擎
基于结构化的FAQ的问答引擎流程由两条技术路线来解决
无监督学习,基于快速检索
有监督的学习,基于深度匹配
采用了三个层次的方法来实现快速检索的方法
层次1:基础的TFIDF提取query的关键词,用BM25来计算query和FAQ库中问题的相似度。这是典型的词汇统计的方法,该方法可以对rare word比较鲁棒,但同时也存在词汇匹配缺失的问题。
层次2:采用了language model(简写LM)的方法。主要使用的是Jelinek-Mercer平滑法和Dirichlet平滑法,对于上面的词汇匹配问题表现良好,但是也存在平滑敏感的问题。
层次3:最后一层使用Embedding,采用了LSA/word2vec和腾讯知文自己提出的Weighted Sum/WMD方法,以此来表示语义层面的近似,但是也同样引发了歧义问题。
产品3: 阿里小蜜
产品链接
意图与匹配分层的技术架构体系
在阿里小蜜这样在电子商务领域的场景中,对接的有客服、助理、聊天几大类的机器人。这些机器人,由于本身的目标不同,就导致不能用同一套技术框架来解决。因此,我们先采用分领域分层分场景的方式进行架构抽象,然后再根据不同的分层和分场景采用不同的机器学习方法进行技术设计。首先我们将对话系统从分成两层:
1、意图识别层:识别语言的真实意图,将意图进行分类并进行意图属性抽取。意图决定了后续的领域识别流程,因此意图层是一个结合上下文数据模型与领域数据模型不断对意图进行明确和推理的过程;
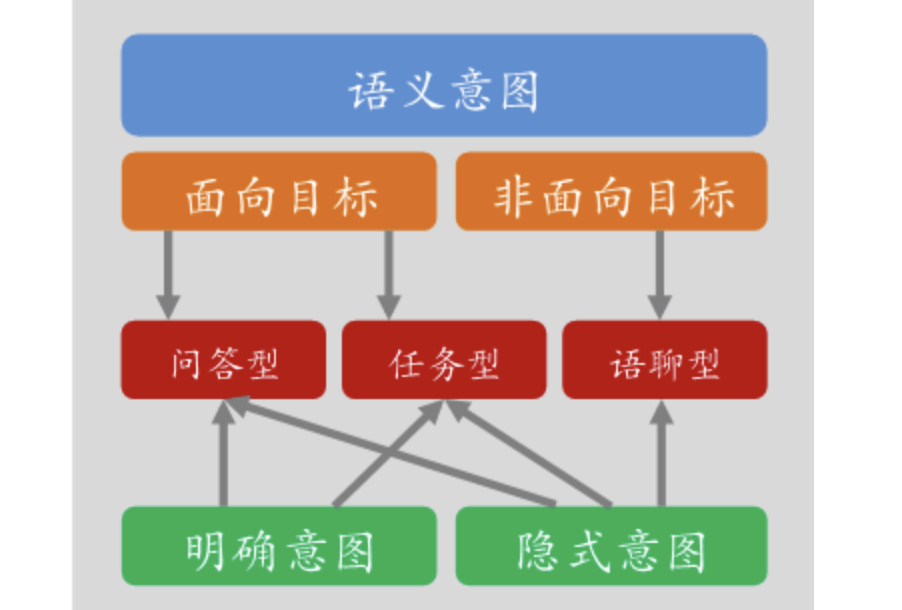
2、问答匹配层:对问题进行匹配识别及生成答案的过程。在阿里小蜜的对话体系中我们按照业务场景进行了3种典型问题类型的划分,并且依据3种类型会采用不同的匹配流程和方法:
问答型:例如“密码忘记怎么办?”→ 采用基于知识图谱构建+检索模型匹配方式
任务型:例如“我想订一张明天从杭州到北京的机票”→ 意图决策+slots filling的匹配以及基于深度强化学习的方式
语聊型:例如“我心情不好”→ 检索模型与Deep Learning相结合的方式
下图表示了阿里小蜜的意图和匹配分层的技术架构。
意图识别介绍:结合用户行为deep-learning模型的实践
通常将意图识别抽象成机器学习中的分类问题,在阿里小蜜的技术方案中除了传统的文本特征之外,考虑到本身在对话领域中存在语义意图不完整的情况,我们也加入了用实时、离线用户本身的行为及用户本身相关的特征,通过深度学习方案构建模型,对用户意图进行预测, 具体如下图:

在基于深度学习的分类预测模型上,我们有两种具体的选型方案:一种是多分类模型,一种是二分类模型。多分类模型的优点是性能快,但是对于需要扩展分类领域是整个模型需要重新训练;而二分类模型的优点就是扩展领域场景时原来的模型都可以复用,可以平台进行扩展,缺点也很明显需要不断的进行二分,整体的性能上不如多分类好,因此在具体的场景和数据量上可以做不同的选型。
行业三大匹配模型
目前主流的智能匹配技术分为如下3种方法:1、基于模板匹配(Rule-Based) 2、基于检索模型(Retrieval Model) 3、基于深度学习模型(Deep Learning)
在阿里小蜜的技术场景下,我们采用了基于模板匹配,检索模型以及深度学习模型为基础的方法原型来进行分场景(问答型、任务型、语聊型)的会话系统构建。
阿里小蜜的核心算法之一:自然语言理解(NLU)方法
无样本冷启动方法
写一套简单易懂的规则表示语法
小样本方法
先整理出一个大数量级的数据,每一个类目几十条数据,为它建立 meta-learning 任务。对于一个具体任务来说:构建支撑集和预测集,通过 few-shot learning 的方法训练出 model,同时与预测集的 query 进行比较,计算 loss 并更新参数,然后不断迭代让其收敛。
这只是一个 meta-learning 任务,可以反复抽样获得一系列这样的任务,不断优化同一个模型。在线预测阶段,用户标注的少量样本就是支撑集,将 query 输入模型获得分类结果。
模型的神经网络结构分为3部分,首先是 Encoder 将句子变成句子向量,然后再通过 Induction Network 变成类向量,最后通过 Relation Network 计算向量距离,输出最终的结果。
具体地,Induction Network中把样本向量抽象到类向量的部分,采用 matrix transformation 的方法,转换后类边界更清晰,更利于下游 relation 的计算。在 Induction Network 的基础上,又可以引入了 memory 机制,形成Memory-based Induction Network ,目的是模仿人类的记忆和类比能力,在效果上又有进一步提升。
多样本方法
构建一个三层的模型,最底层是具有较强迁移能力的通用模型 BERT,在此基础上构建不同行业的模型,最后用相对较少的企业数据来训练模型。这样构建出来的企业的 NLU 分类模型,F1 基本都在90%+。性能方面,因为模型的结构比较复杂,在线预测的延时比较长,因此通过知识蒸馏的方法来进行模型压缩,在效果相当的同时预测效率更快了。
4 总结
整个CQA问答,可能经过的模块共两个:召回模块和检索模块。
无监督的匹配方式 - 规则,LDA,Sentence bert等
有监督的深度模型匹配方式
DSSM(采用了词袋模型,损失了上下文信息,可选用CNN-DSSM等优化模型) - ESIM(适用于短文本)
文本语义表达的Siamese networks深度模型。应用广泛的模型只要有DSSM、ESIM,MAtchPyramid等
MatchPyramid() 基于交互的深度模型)
召回模块 -主要采用传统信息检索方法实现
IR检索模块
问答对较少等情况下可以将IR模块改为分类任务(意图识别)进行。
如果在数据不充足,或数据效果质量不高的情况下,可以使用迁移学习,以训练好的模型为基础。
在系统设计初期,根据数据的不同情况,可参考阿里小蜜自然语言理解(NLU)方法中的无样本冷启动方法、小样本方法、多样本方法的思路。
难点
有标记的相似文本训练数据标注难以自动获取
高质量的问答对数据获取与维护成本较高
用户可能的输入类型较多,匹配模型的鲁棒性无法保证
未来研究方向
利用预训练模型解决文本匹配问题
FAQ的发现与优化的自动化
原文地址
https://github.com/BDBC-KG-NLP/QA-Survey/blob/master/CQA%E8%B0%83%E7%A0%94-%E5%B7%A5%E4%B8%9A%E7%95%8C.md
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx