
volatile 三部曲之可见性

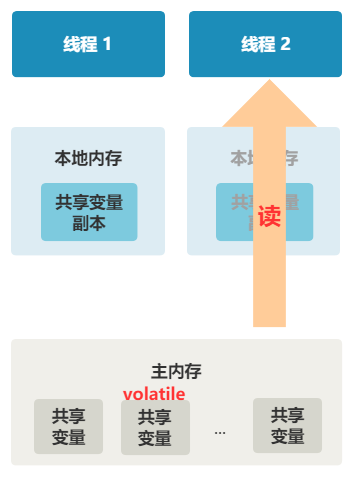
可见性

LOCK
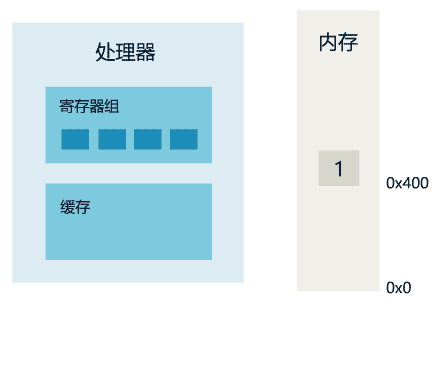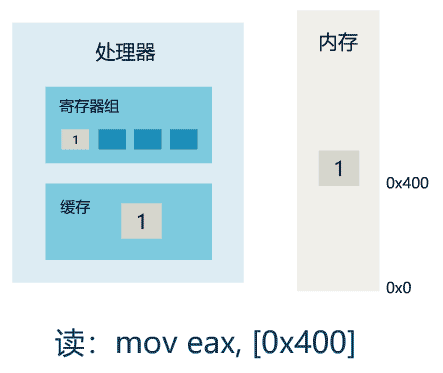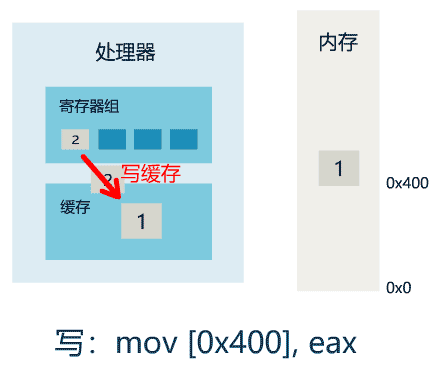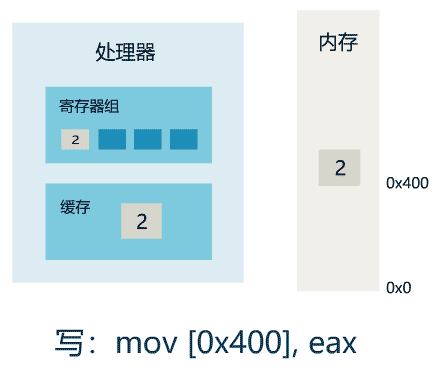
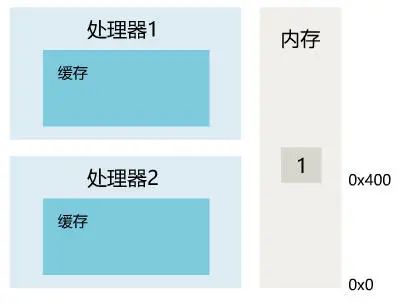
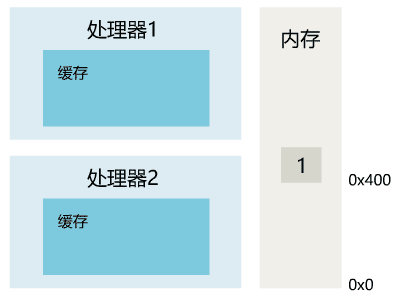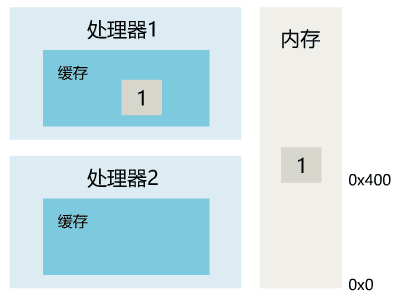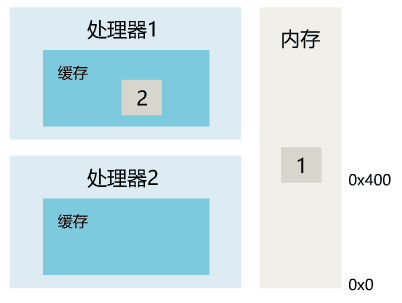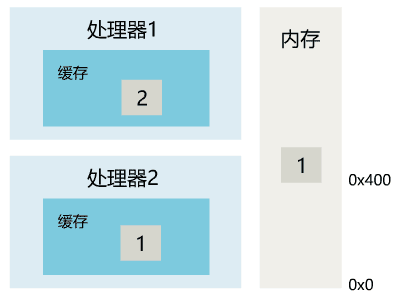
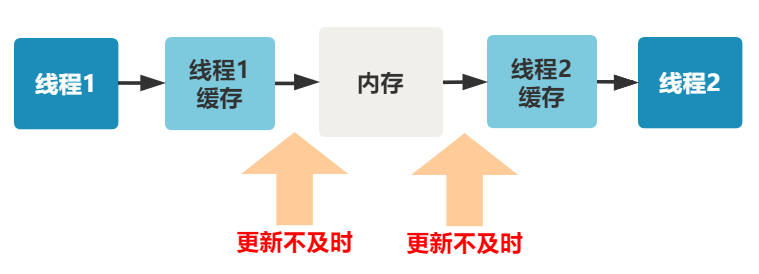
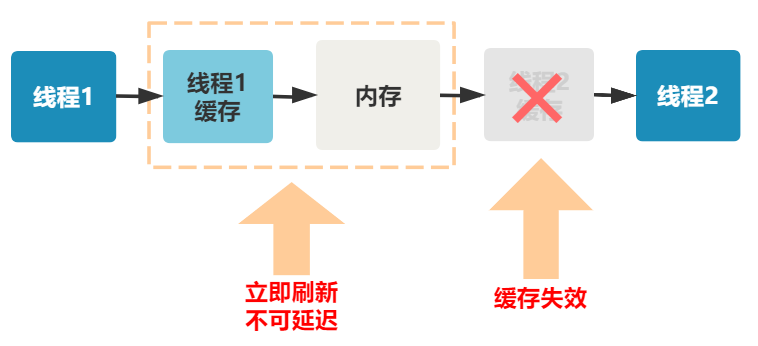
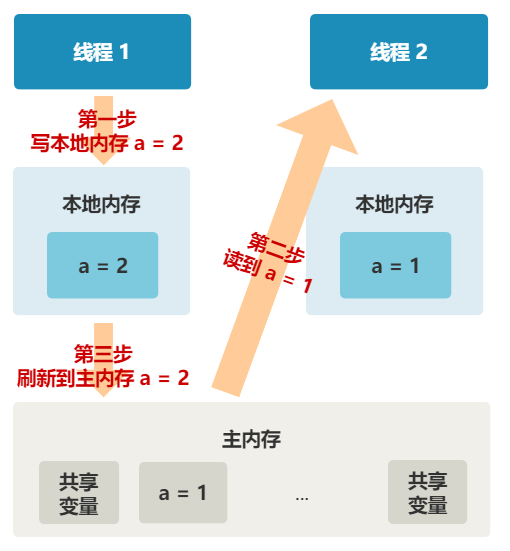
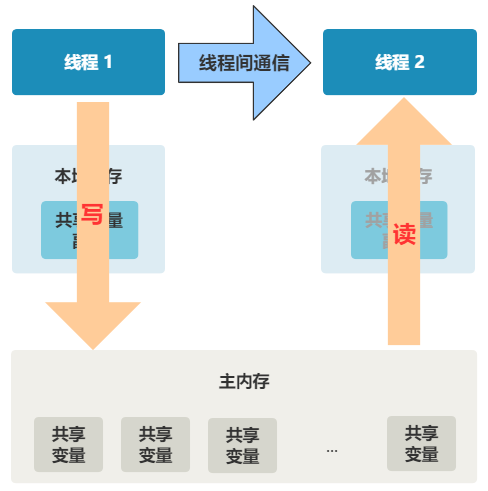
1. 线程 1 对共享变量的修改,如果刚刚将其值写入自己的缓存,却还没有刷新到内存,此时内存的值仍为旧值。
2. 即使线程 1 将其修改后的值,从缓存刷新到了内存,但线程 2 仍然从自己的缓存中读取,读到的也可能是旧值。
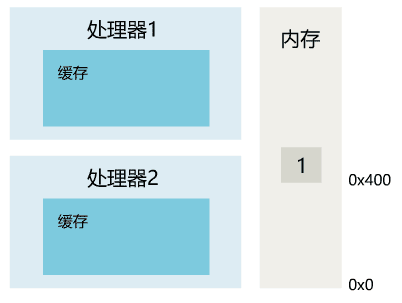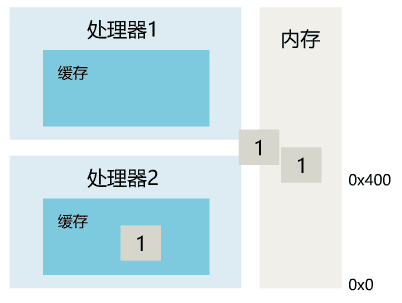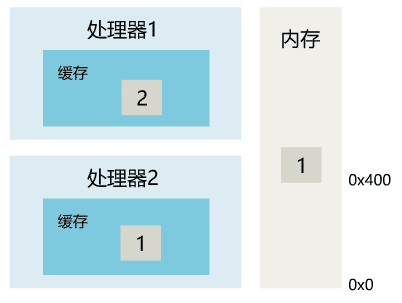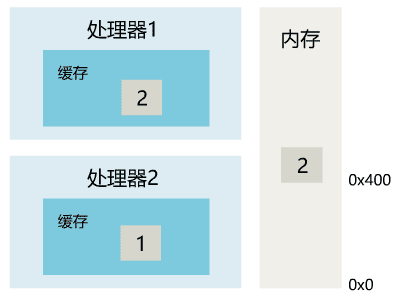
add [某内存地址], 1lock add [某内存地址], 1
JMM
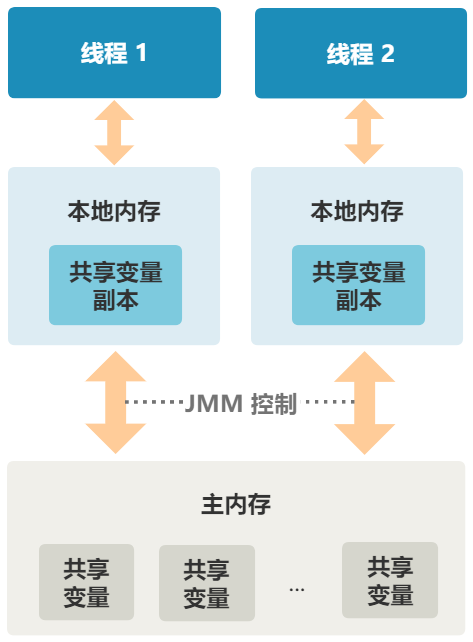
volatile
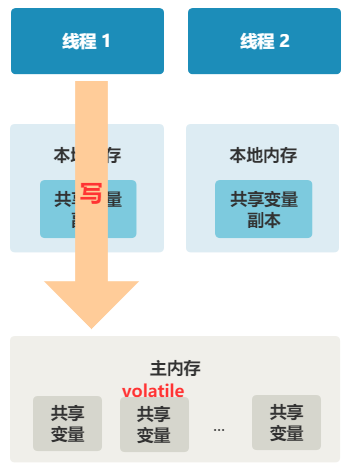
volatile int a;
后记
后记
写这篇文章时真的是瑟瑟发抖,一是因为网上讲这个知识点的实在太多了,二是我发现 volatile 这个知识点水很深,从底层硬件一直到上层语言,每一层都有实现原理,层层抽象直到上层表现为我们看到的样子。
我甚至觉得不可能有人对这个知识点完全理解透彻。缓存一致性和总线嗅探,你需要了解 CPU 硬件的原理吧?JMM 内存模型,你需要了解 JVM 虚拟机实现吧?
或者不说实现的事儿,就单单是 JMM 说了什么,很多人觉得懂了,但你看过 JSR133 文档对 JMM 模型的正式规范么?很长,给大家随便截取一小段。

评论