
单张人像生成视频!中国团队提出最新3D人脸视频生成模型,实现SOTA
新智元报道
新智元报道
来源:IEEE
编辑:好困
【新智元导读】稀疏人脸特征点生成的人脸图像视频通常会遇到图像质量损失、图像失真、身份改变,以及表情不匹配等问题。为此作者使用重建出的三维人脸动态信息来指导人脸视频的生成。结果显示,FaceAnime从单张静止人脸图像生成的视频比其它方法效果更好。
如何用一张人脸可以生成一段有趣的视频?

当然不是指这种直接贴个人头就算了的粗糙gif
人脸视频的生成通常会利用人脸图像的稀疏特征点(landmarks)结合生成对抗网络(GAN)。
不过,这种由稀疏人脸特征点生成的人脸图像视频通常会遇到很多问题。
比如图像质量损失、图像失真、身份改变,以及表情不匹配等问题。
因此,为了解决这些问题,本文作者使用重建出的三维人脸动态信息来指导人脸视频的生成。

论文地址:https://ieeexplore.ieee.org/abstract/document/9439899
arXiv版本:https://arxiv.org/pdf/2105.14678.pdf
三维人脸动态中,人的面部表情和动作更加细腻,可以作为有力的先验知识指导生成高度逼真的人脸视频。
文中,作者设计了一套三维动态预测和人脸视频生成模型(FaceAnime)来预测单张人脸图像的3D动态序列。
通过稀疏纹理映射算法进一步渲染3D动态序列的皮肤细节,最后利用条件生成对抗网络引导人脸视频的生成。
实验结果显示,FaceAnime能从单张静止的人脸图像生成高保真度、身份不变性的人脸视频,比其它方法效果更好。
背景和贡献
当前的人脸视频生成方法普遍采用人脸的稀疏特征点(landmarks)来引导图片或视频的生成。
然而作者认为使用稀疏的二维特征点引导人脸图像/视频生成有明显的不足:
稀疏人脸特征点不能很好地表示人脸图像的几何形状,容易导致人脸整体形状和面部结构细节的缺失,进而导致合成图像的失真和质量损失; 稀疏的二维特征点不携带源人脸图像的任何内容信息,这可能会导致生成的图像过拟合于只包含训练集的人脸图像中; 在视频生成过程中应保留人脸身份信息,但稀疏的2D特征点没有身份信息,容易导致合成结果的身份变化。
因此,文章针对这些方面做出了以下贡献:
不同于广泛使用2D稀疏人脸landmarks进行图像/视频的引导生成,文章主要探索包含人脸丰富信息的3D动态信息的人脸视频生成任务; 设计了一个三维动态预测网络(3D Dynamic Prediction,3DDP)来预测时空连续的3D动态序列; 提出了一个稀疏纹理映射算法来渲染预测的3D动态序列,并将其作为先验信息引导人脸图像/视频的生成; 文章使用随机和可控的两种方式进行视频的生成任务,验证提出方法的有效性。
方法描述
本文提出的FaceAnime包含一个3D动态预测网络(3D Dynamic Prediction, 3DDP)和一个先验引导的人脸生成网络(Prior-Guided Face Generation, PGFG)。
首先,方法基于三维形变模型(3D Morphable Models, 3DMM)对单张人脸图像进行三维重建,3DDP网络随后预测该图像未来的3D动态序列,之后将动态序列进行稀疏纹理映射渲染,最后使用PGFG网络完成相应的人脸生成。
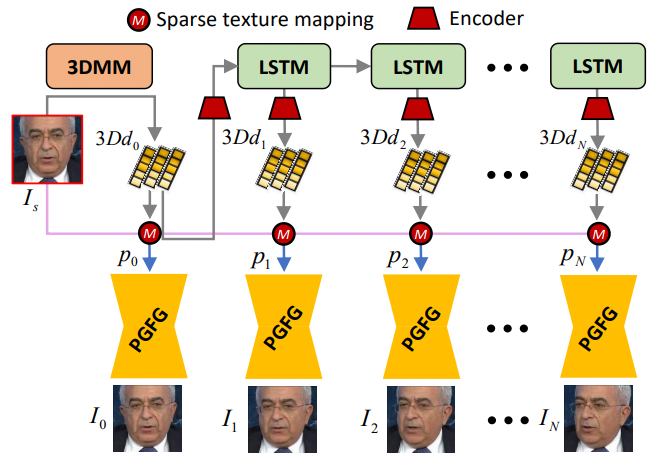
FaceAnime的整体框架图,3DDP网络部分
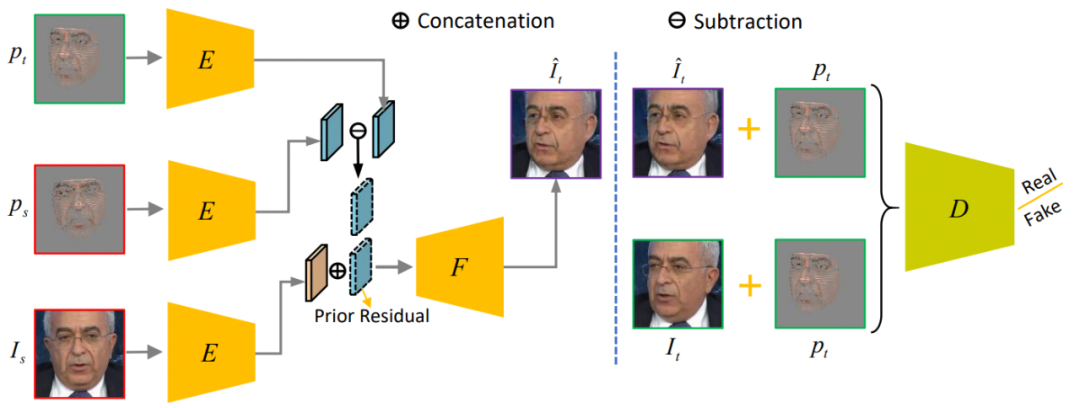
FaceAnime的整体框架图,PGFG网络部分
3D人脸重建和稀疏纹理映射
3D形变模型(3D Morphable Model, 3DMM)用来从2D人脸图像中预测相应的3D人脸。
其中,描述3D人脸的顶点(vertex)可由一系列2D人脸中的正交基线性加权得出:
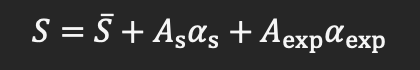
其中,S bar是平均脸, As是形状主成分基, as是相应的形状系数,Aexp是表情主成分基,aexp是对应的表情系数。
反过来,3D人脸顶点也可以通过变换映射到一个2维图像平面上,对应的公式可以表达为:
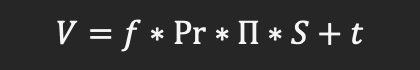
其中,V表示3D顶点在2维平面上的映射坐标,∏是固定的正交映射矩阵,Pr是对应的旋转矩阵,而t为偏移向量。
通过最小化映射landmarks和检测的landmarks之间的l2距离,最终可以求得3DMM中的系数。
给定一张源人脸图像(Source Face),其3D形状可以通过改变重建的3DMM系数来进行任意的修改, 则目标人脸的稀疏纹理可以由修改后的3DMM系数获得。
在人脸重定向任务中,修改的3DMM系数可由参考人脸视频帧得到,而在人脸预测任务中,则由LSTM模块预测得到。
为了防止在纹理映射中,密集的纹理先验信息太强而导致目标动作中出现不符合期望的结果,因此在纹理映射过程中本文采用间隔采样即稀疏纹理映射,以适应不同的人脸运动变化。

给定不同的3DMM系数所得到的不同三维人脸重建和稀疏映射的结果
不同于以往只针对某一种任务的视频生成,在本文中作者提出了三个不同的生成任务,即人脸视频重定向(Face video retargeting),视频预测(Video prediction)以及目标驱动的视频预测(Target-driven video prediction)。
对于retargeting任务,作者使用参考视频来提供序列的变化信息,而不使用3DDP来预测。
视频预测:
给定一个观测到的动态序列(3DMM coefficients),LSTM对其进行编码:
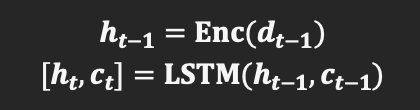
为了预测出一个合理的动作,LSTM不得不首先学习大量的动作输入以识别在姿态序列中运动的种类以及随时间的变化。
在训练过程中,未来动态序列可以由下式生成:
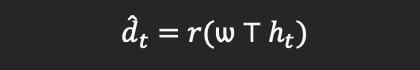
其中dt hat表示预测得到的3DMM系数,其表示在时刻t的3D dynamic。
基于以上公式,模型可以从一个初始的dynamic d0学到一个合理的未来序列。
目标驱动的视频预测:
对于LSTM来讲,要实现目标引导的运动生成,模型需要两个输入,即source dynamic和target dynamic。
不同于视频预测,作者使用了一个计时器来对target dynamic进行重新赋权。
整体的LSTM预测可以用公式表示为:
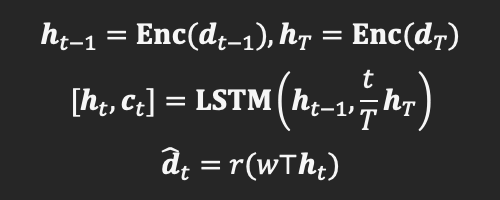
这里dT表示target dynamic,T为预测长度,即t=0表示序列开始时间,t=T为序列结束。
损失函数:
给一个source人脸图像,作者使用2DAL模型回归出相应的3DMM系数,用来表示初始的3D dynamic d0。之后模型通过观测d0来生成一个系数序列d1:T hat。
在训练过程中,作者使用3DMM coefficient loss和3D vertex loss两个损失函数进行监督学习。
3DMM coefficient loss定义为预测3DMM 系数和ground truth 3DMM系数之间的欧式距离:
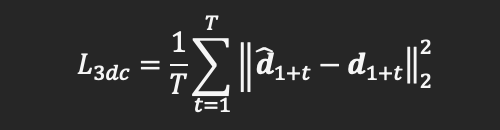
而3D vertex loss定义为:
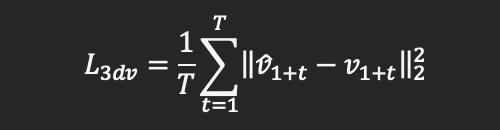
其中v1+t hat和v1+t分别为预测得到的系数和标准系数对应的人脸三维顶点信息。则整体的损失函数可以表述为:
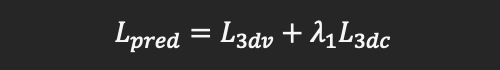
先验引导的人脸生成:基于提出的稀疏纹理映射,source人脸图像被用于渲染预测的3D dynamics。在这里,稀疏纹理作为引导人脸生成的先验信息。
文中提到的网络PGFG(Prior-Guided Face Generation Network)主要由条件GANp网络来组成。
PGFG网络的结构:
PGFG生成器G有三个输入,分别是source人脸Is,Is对应的纹理先验ps和pt目标的纹理先验。
在这里,作者并没有直接使用目标的纹理先验pt作为先验引导,而是使用了先验残差来引导人脸生成,在特征空间可以获得运动残差:E(pt)-E(ps)。由此可得最终人脸为:

为了进一步利用不同空间位置的特征信息,编码器和解码器均由Dense blocks组成。
判别器有两个输入,即目标人脸图像的纹理先验分别和生成人脸、目标人脸结合的输入[pt, It hat],[pt, It]。
损失函数:
网络PGFG由三个损失函数进行监督,分别为图像像素间的损失Limg,对抗损失Ladv和身份信息损失Lid。
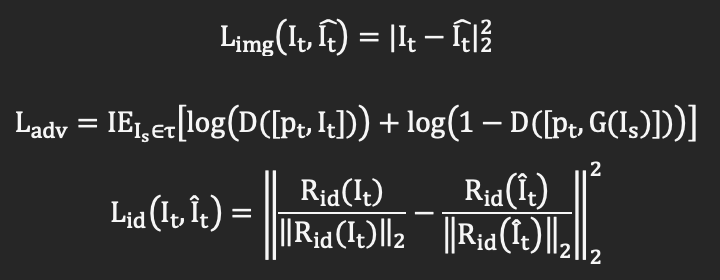
需要注意的是,在身份信息损失中,R为预训练的人脸识别模型。网络整体的损失函数为:

结果和分析
作者分别对人脸视频重定向、视频预测以及目标驱动的视频预测三个任务做了相应的大量实验。
人脸视频重定向:
在这个任务中,作者分别对人脸表情的重定向以及头部讲话重定向两个子任务进行了实验。
实验表明,所提出的FaceAnime模型可以很好的将source人脸图像中的表情和动作重定向到目标图像上,生成相对应的姿态和讲话表情。

FaceAnime的人脸表情重定向(a)和头部讲话重定向(b)实验结果
人脸视频预测:
这个任务中包含视频预测以及目标驱动的视频预测两个子任务。
对每一个预测任务,实验过程中作者随机选取一张从人脸图像测试集IJB-C中抽取的单张人脸图像。
对于视频测试,作者首先使用3DDP网络从source人脸中预测一个运动序列,然后用该序列引导人脸视频的生成。
而对于目标引导的人脸预测任务,则需要两个输入图像。一个是source人脸,另一个为target人脸。
3DDP网络用于预测从source人脸到target人脸之间平滑的运动变化,从而引导人脸视频的生成。
 FaceAnime的视频生成结果
FaceAnime的视频生成结果
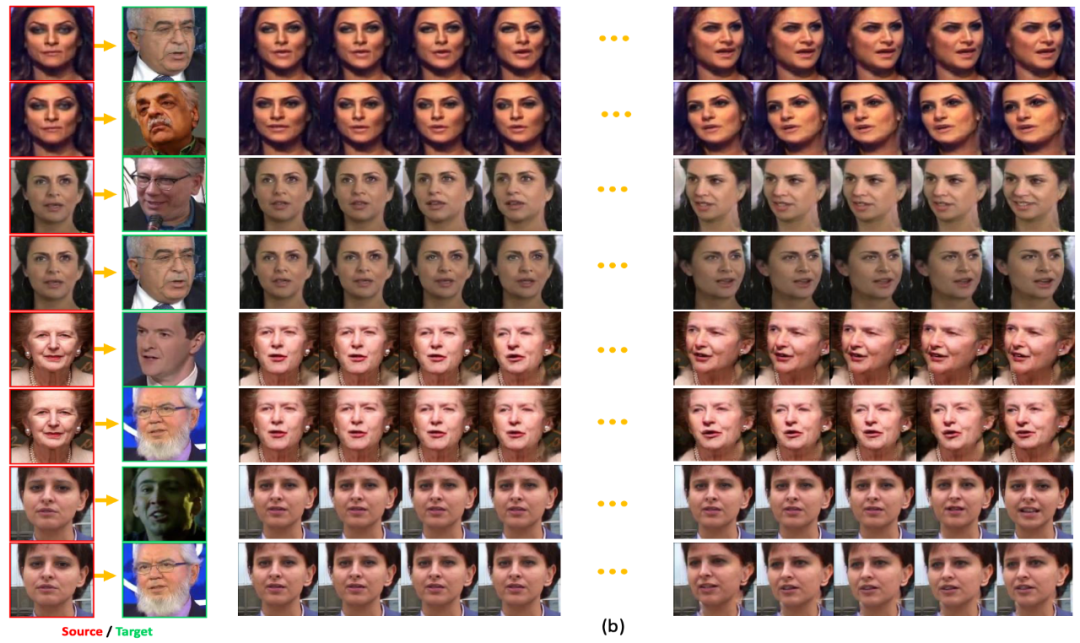
FaceAnime的目标驱动视频生成的结果
为了展示所提出方法的先进性,作者还同其他类似任务的算法进行了效果对比。

FaceAnime和其它方法的对比结果
通过比较,FaceAnime不仅可以生成高质量且真实的人脸视频序列,同时生成的视频图像可以精确的还原参考视频中人脸表情和姿态变化,还能较好的保持人脸的身份信息。
大量实验表明,作者提出的方法可以将参考视频的姿态和表情变化重定位到source人脸上,并且对于一个随机的人脸图像,其可以生成合理的未来视频序列。
对比其他最先进的人脸生成方法,所提出的方法在生成高质量和身份信息保持的人脸方面具有更好的效果。
作者介绍
涂晓光,2020年在中国电子科技大学获得博士学位。2018年至2020年在新加坡国立大学学习与视觉实验室做访问学者,师从冯佳时博士。研究兴趣包括凸优化,计算机视觉和深度学习。
邹应天,新加坡国立大学计算机学院在读博士。2018年,他在中国武汉的华中科技大学获得计算机科学学士学位。他的研究兴趣是计算机视觉、实用机器学习算法及其理论。
赵健,2012年获得北京航空航天大学学士学位,2014年获得国防科技大学硕士学位,2019年获得新加坡国立大学博士学位。他的主要研究兴趣包括深度学习、模式识别、计算机视觉和多媒体分析。曾获ACM MM 2018年最佳学生论文奖。曾担任NSFC、T-PAMI、IJCV、NeurIPS(2018年NeurIPS最高分前30%的审稿人之一)、CVPR等的邀请审稿人。
艾文杰,电子科技大学信息与通信工程学院在读硕士。他感兴趣的研究领域主要包括计算机视觉和深度学习,特别是超级分辨率和去模糊。
董健,IEEE会员,在新加坡国立大学获得博士学位。目前是Shopee公司的董事。曾任360的高级总监和亚马逊的研究科学家。他的研究兴趣包括机器学习和计算机视觉,并在PASCAL VOC和ILSVRC比赛中获得了优胜奖。
遥远,Pensees新加坡研究院的人工智能科学家。2019年在新加坡国立大学获得电子和计算机工程硕士学位。2019年在剑桥大学剑桥图像分析组做访问学者。他的研究兴趣包括生成式对抗网络、光流估计和人脸识别。
王智康,西安电子科技大学电子工程学院在读硕士。2019年至2020年在新加坡国立大学学习与视觉实验室做访问学者。他的研究兴趣包括计算机视觉、深度学习和多媒体数据处理。
李志锋,腾讯人工智能实验室的顶级首席研究员。2006年在香港中文大学获得博士学位。之后在香港中文大学和密歇根州立大学做博士后研究。在加入腾讯人工智能实验室之前,他是中国科学院深圳先进技术研究院的一名全职教授。他的研究兴趣包括深度学习、计算机视觉和模式识别,以及人脸检测和识别。目前在《神经计算》和《IEEE视频技术电路与系统》的编辑委员会任职,并且是英国计算机学会(FBCS)的研究员。
郭国栋,在美国威斯康星大学麦迪逊分校获得计算机科学博士学位。目前是百度研究院深度学习研究所的副所长,同时也是美国西弗吉尼亚大学(WVU)计算机科学和电子工程系的副教授。他的研究兴趣包括计算机视觉、生物统计学、机器学习和多媒体。他在2008年获得北卡罗来纳州优秀创新奖,在西弗吉尼亚大学CEMR获得杰出研究员(2017-2018),在西弗吉尼亚大学CEMR获得年度最佳新研究员(2010-2011)。
刘威,腾讯人工智能实验室计算机视觉中心的主任。曾于2012年至2015年在美国纽约州约克敦高地的IBM T. J. Watson研究中心担任研究人员。他致力于机器学习、计算机视觉、模式识别、信息检索、大数据等领域的研究和开发。目前在IEEE Transactions on Pattern Analysis and Machine Intelligence、IEEE Transactions on Neural Networks and Learning Systems、IEEE Transactions on Circuits and Systems for Video Technology、Pattern Recognition等刊物的编委会任职。他是国际模式识别协会(IAPR)的会员和国际统计学会(ISI)的当选成员。
冯佳时,2007年在中国科技大学获得工学学士学位,2014年在新加坡国立大学获得博士学位。2014年至2015年,他在美国加州大学担任博士后研究员。目前是新加坡国立大学电子和计算机工程系的助理教授。研究兴趣集中在大规模数据分析的机器学习和计算机视觉技术。
参考资料:
https://arxiv.org/pdf/2105.14678.pdf
