
OLAP 实践 | 京东 OLAP 亿级查询高可用实践
OLAP(On-Line Analytical Processing)是联机分析处理,它主要用于支持企业决策和经营管理,是许多报表、商业智能和分析系统的底层支撑组件,支持从海量数据中快速获取数据指标。
京东OLAP的发展历经Druid、Kylin、Doris和ClickHouse,广泛服务于京东各个子集团和各类场景中,经历了数次大促的考验无事故,本文会重点以ClickHouse为主,介绍京东OLAP高可用实践情况,如业务场景和选型的考量,运维部署方案,高可用架构以及在使用过程中遇到的问题和未来改进计划。
京东数据分析的场景非常多,零售集团主营业务是在线电商业务,既有电商交易数据又有用户流量数据,同时也有物流、健康、京喜等线下业务线。
1)交易数据的难点,就是业务复杂,需要关联多张表,SQL中逻辑多;另外就是数据会更新,比如交易状态和金额的变化,组织架构的变化会导致数据需要更新或删除重新导入。
2)流量数据有几个特点,一是只追加不修改;二是量大,因为包含用户的点击和浏览等各类行为数据,以及由此衍生的各种指标,比如UV计算;三是数据字段会经常变化。
3)实时大屏是618大促时常见一种数据展现形式,这种场景都是实时数据,一块大屏展现数据指标比较多并发大,涉及订单数据还需要更新,比如北京消费卷就有各种状态,可用性要求也非常高。实时写入、数据更新、高并发以及海量数据,这些条件综合在一起,对OLAP来说是一个不小的挑战。
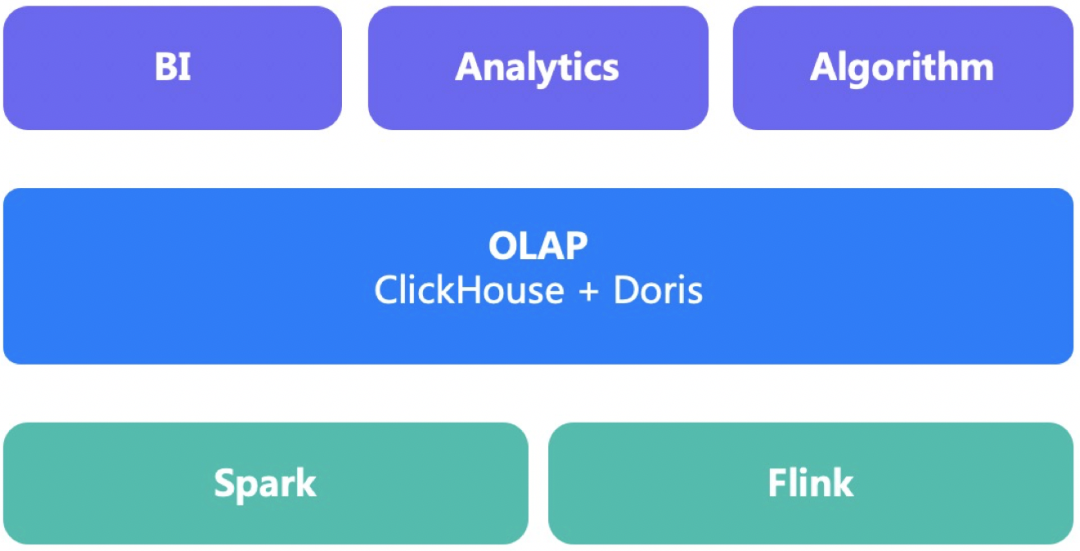
在大数据架构中,OLAP的上游是Spark/Flink等计算引擎,下游对接报表、分析系统或策略系统。通过实施OLAP组件,可以加快需求响应速度,简化计算过程降低IDC成本。京东大数据发展较早,大数据体系也比较成熟,陆续引入了很多OLAP组件,主流OLAP技术都正式使用过,目前形成了ClickHouse为主Doris为辅的实施策略。
Druid是实时预聚合的技术,用于计算广告领域比较多,面向广告主或内部产研的广告数据指标的计算;Kylin的技术特点是预聚合,Cube计算方式能够加快计算速度,内置存储逻辑,提供友好SQL查询接口;ElasticSearch本身基于Lucence改进,用到搜索引擎的索引技术,一般用于半结构化的数据如日志或文本分析。

如上图,选择合适的OLAP组件,需从海量、时效性、灵活性和适应性这几个层面来考虑。
海量则是指单一集群是否能够支撑百亿甚至千亿的数据分析,是否能够处理海量数据是衡量OLAP组件的一个基础指标,抛开海量去谈其他的没有意义;
时效性可以提升决策的效率,能快速迭代检验决策效果,比如是否支持分钟级或亚秒级端到端数据分析;
灵活性指能够快速响应业务需求,灵活调整指标计算方式和任意维度组合分析,而不用重新部署和预计算;
适应性指能否覆盖大部分的数据分析场景,还是只能满足特性场景,因为靠多个组件组合去满足需求会增加复杂度。
ClickHouse和Doris是分析型数据库,能够很好的满足以上四点,也非常好适应绝大部分场景,因而成为京东内部主流的OLAP引擎,他们能组成一个互补的搭配,因为ClickHouse性能强悍,扩展性好,但使用门槛和运维成本较高,在大数据量和极限场景下使用;Doris使用简单,运维也简单,适用于中小数据量业务场景。
京东业务线多,数据需求旺盛,我们建立起一套小集群多租户的模式,部署多个百台左右的集群服务于大量业务;同时针对不同场景的特点定制化部署方案,比如存储量大、并发大或有大查询等不同情况。一个合理的集群规划是实施OLAP成功的关键,如果刚开始方案不合适,亦或没考虑到运维和运营成本,后面的麻烦事会接踵而来,所以我们花一些篇幅来说明这个问题。

如何配置集群和业务有多种方式,一个方案是部署一个超大的OLAP集群把所有业务放在一起,另一个方案是每个业务都独立部署一套集群。前者业务响应速度快,资源利用率高,但业务间互相影响,大集群运维难度大;后者完全隔离,但资源无法调配,数量庞大的集群运维投入大。因此,我们选择了分场景隔离和多租户的模式,能一定程度上兼顾业务高可用、资源利用率和运维的方便性。
离线和实时分离,因为离线大批量数据导入,消耗CPU和磁盘,会影响实时数据的写入;
报表和分析型分离,因为分析型有大查询,会占用较多资源,同时几个大查询会把CPU打满,影响其他业务;
高并发分离,因为高并发会大量占用集群CPU和内存,影响其他业务的查询和写入;低延时分离,低延时指数据需要秒级写入,势必会大量小文件写入,后台合并负担较重,影响其他业务的写入;
总体来说,就是回答是否实时、是否大查询、是否高并发等问题,如果回答“是”,则需要考虑独立一个集群来。
多租户来服务众多业务,因为集团内业务线众多,为了保证服务质量,及时响应需求,提升资源利用率,我们提供了共享集群多租户的运营方案,在一个集群中让数十个业务一起使用,每个业务分别建立一到多个账号,多个账号可以是不同的团队、产品或模块使用,为了避免资源抢占和互相影响,多账号通过配额来限制,也可以控制不同账号权限比如读、写和DDL权限,进行分级管理。我们在CH中主要通过查询量(并发数+Query次数)、查询大小(内存限制+超时时间)来控制,我们统称为用户配额。
1)查询量(并发数和Query次数):并发数指同时执行的Query数量,设置为CPU核数的1-3倍,具体到每个账号,可以根据在线人数峰值来预估。Query次数,在CH的Quota设置中,计数窗口是可以自定义的,为了避免峰值波动以及能快速生效,我们定义的是10秒的时间窗口,10秒内的Query数量不能超过某个限制,同时我们修改了内核对读和写的Query分别统计。
2)查询大小(内存限制和超时时间):为了避免执行时间过长的查询对集群的影响,限制查询内存大小和超时时间,单个查询内存限制为节点内存的1/4-1/2,达到超时时间的查询将会被终止。如果出现超过内存或时间的情况,需要降低查询范围以及Group By的数据量,另外看是否需要优化存储和SQL来提升单个查询的性能。
通过多租户和配额的机制,可以快速响应业务侧新申请账号或配额变更的需求,同时也对不符合最佳实践的使用进行约束,比如慢查询或穿透缓存的查询。同时这个方案对独占集群也是有效的,因为不同账号对应的模块之间也需要分别来控制。多租户方案的另一个好处在出现问题时,我们可以根据账号来缩小排查范围,快速定位问题。
通过上云让业务自主化使用,另一个支持业务方案是上云,通过K8S来部署集群,容器化的优势是标准化和资源隔离,我们通过标准化的资源搭配供用户去选择。我们自研了OLAP管控面,用户可以通过管控面申请资源,配置监控和报警以及查看查询情况。管理员也可以进行日常运维操作,集群部署、上下线、配额调整等,当集群故障时也可通过预设方案进行自愈。
OLAP中既有存储又有计算,是计算和存储都密集型,资源选型和搭配合理性尤为重要。
资源类型配比要合理。不同场景资源类型的需求是不一样的。按照我们的经验,计算量大的业务,选择CPU核数多主频高的,比如分组和去重的计算;数据保留时间长的业务,磁盘空间则需要大;如果使用字典,数据需要加载到内存,则需要考虑大一点内存。一般来说CPU32核内存64-128G磁盘2-10T。
离线推荐HDD磁盘。在离线场景中,需要存储数年的数据,存储空间占用大,一般采用普通机械磁盘,数据在外部排序顺序写入,磁盘写入速度和IO都能满足要求。使用HDD磁盘时,需要坚持小批次大批量的原则,尽量降低小文件对系统的负担,采用大容量的磁盘,一个好处就是可以做一些物化视图,来提升查询性能,以空间换时间。而实时场景,我们一般选择SSD或NVME,随机写入能性能好,可以低延时高频写入小文件,能获得更低的数据延时,更低的IO繁忙率。
优先选择单机性能高。分组或去重计算,需要把全部或部分数据汇聚到少量实例中,然后在汇聚实例中计算,依赖单节点的计算性能,集群相同核数的情况下优先选择CPU核数多和主频高的,比如32核的10台和64核的5台,后者在某些场景下计算性能更优。
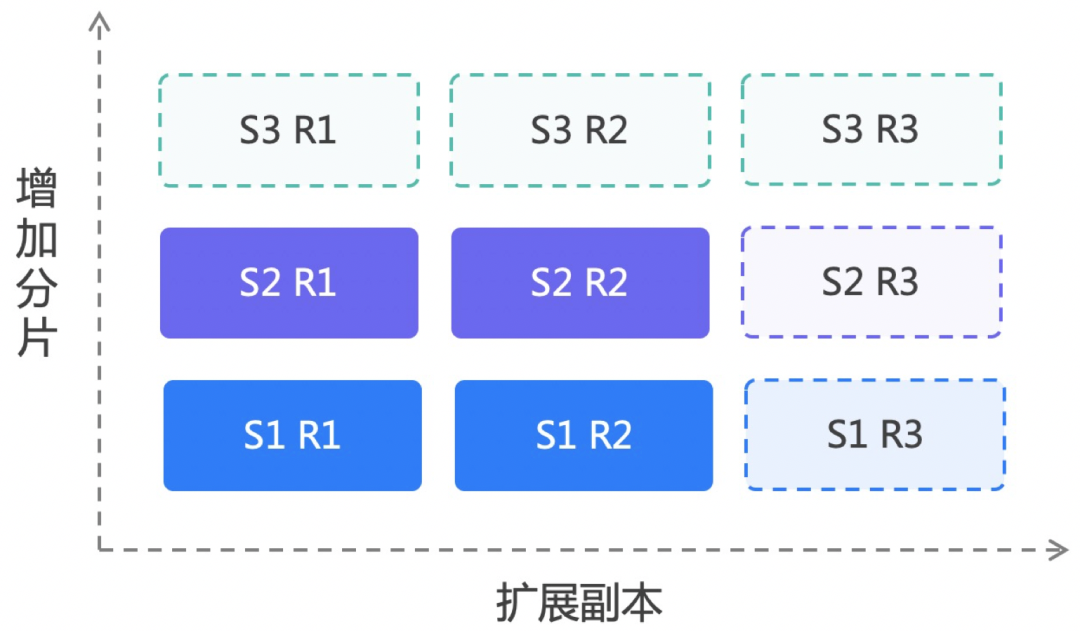
分片和副本数量,需要根据数据规模和并发量来确定。
如何确定分片数,计算单副本未压缩的数据量,然后除以单节点磁盘容量,除以压缩率,就是分片数。另一个计算方式是,一个分片一天写入条数为5亿条,一是兼顾了写入速度二是考虑到每个分区下的分片数据量不能过大。
如何确定副本数,通常可以按单副本100QPS来计算(和查询复杂度密切相关以实际压测为准),假如有500QPS,则需要5个副本来做负载均衡;另一个考虑是,数据的可靠性,所以我们一般推荐2副本以上,避免机器故障导致数据丢失。
流行的CH部署方是单实例的,比如5分片2副本,需要10台服务器,每台服务器部署一个节点,如果查询并发少,CPU和内存会有浪费。因此,我们采用多实例多副本的部署模式,如下图4台服务器,我们部署了4分片和2副本。
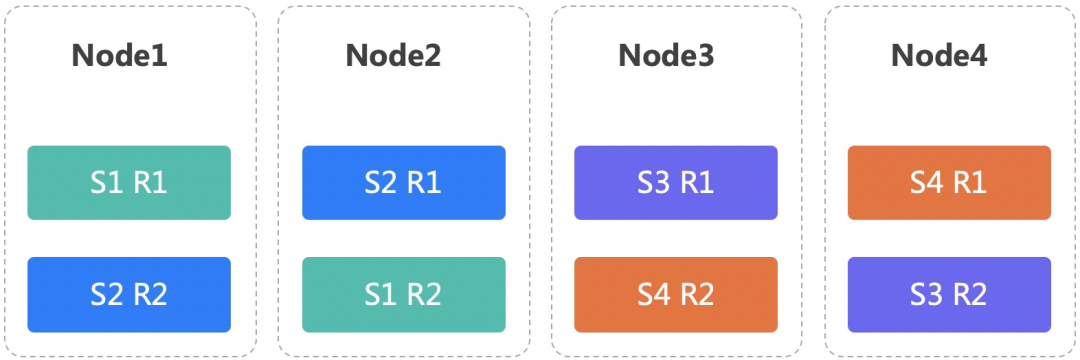
1)支持多实例:我们支持一台物理机部署1-N个实例,每个实例对应不同的网络端口和磁盘目录,单实例是多实例的一种特例。
2)支持多副本:通过配置不同的副本在不同的机器上,保证了数据可靠性,如上图,S指分片R指副本,相同分片的不同副本间互为主备。同时多副本也能充分利用多块磁盘减轻IO压力。
从过往的使用经验来看,OLAP具有一定的高可用性,但是依然有一些情况会引发集群不稳定,如数据或查询不均衡、硬件故障等,我们一直在架构侧努力去弥补这些薄弱环节。
硬件故障是无法避免的,因此如何做到在硬件故障时使用上无感知是我们努力的方向。我们部署CH集群是三层结构:域名 + CHProxy + CH节点,域名转发请求到CHProxy,再由CHProxy根据集群节点状态来转发。CHProxy的引入是为了让Query均匀分布在每个节点上,自动感知集群节点的状态变化,我们对CHProxy做了一定的改进。当集群节点故障时,分为查询、写入和DDL操作来考虑如何规避其影响。
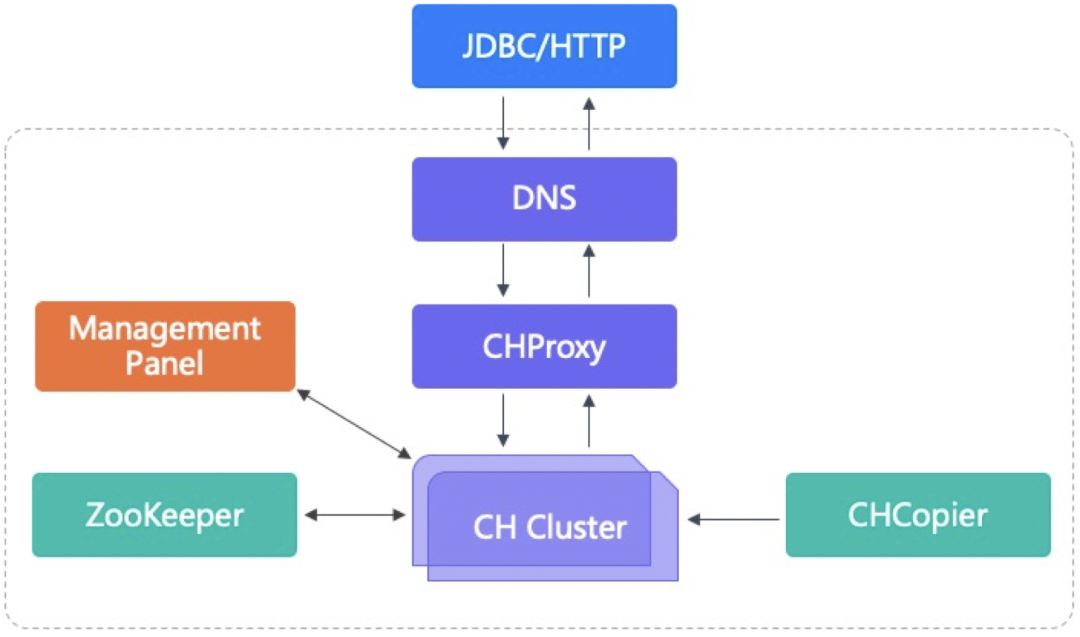
查询时,CHProxy会转发到健康节点,接收查询的节点对副本有Load_balancing策略,执行查询计划时会把子查询发给健康副本,故障节点不会收到查询请求。
写入时,情况稍微复杂,如通过域名来写分布式表或随机写本地表和查询的机制类似。如果指定分片写入本地表,可以在QUERY中指定分片序号,CHProxy会转发写入到指定分片的某个副本上,同样会跳过故障副本节点。
DDL操作,DDL指元数据的修改,在ZooKeeper中有一个DDL队列,如果故障节点短时间内修复后又上线了,会继续执行队列中的DDL操作。如果长时间未能修复,再次上线时,会导致该节点和其他节点的元数据不一致,因此需要手工去修复。我们开发了元数据一致性检查工具,去检测节点元数据、ZooKeeper元数据、数据之间的一致性。
假如CHProxy故障了,域名服务有探测机制,如果请求超时或失败不再转发请求到故障的CHProxy节点。
而Doris在这方面要强很多,因为他有一个完善的元数据管理功能,校验并修复元数据的一致性,有副本的校验和均衡机制,自动修复副本故障,所以,节点故障后下线以及修复后上线,业务侧几乎感知不到。
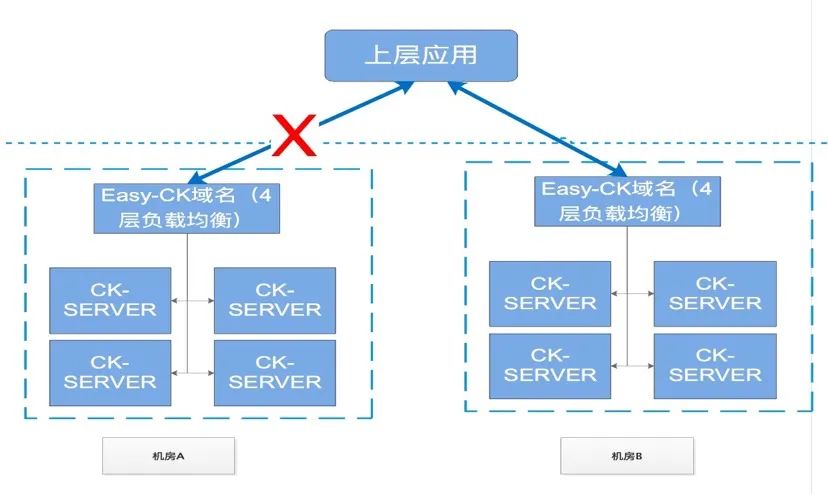
如果是集群单节点故障,可以快速下线该节点,对业务影响较小;如果集群大面积故障,比如机房机架故障,或需要对集群进行停机维护,对于特别重要的报表,我们有主备双流的机房,能够快速切换到备用集群中。
双机房之间的数据同步,目前是通过外部双写双集群的方式来处理,写入程序需要检查双写的一致性。这种方式会增加外部写入的复杂度,同时带来不必要的资源消耗,有较大的优化空间。
我们有一套较为完备的故障发现和处理机制,比如定期的硬件检测、监控和报警系统和定期的冒烟测试。冒烟测试指对集群进行最常见的常规操作,比如建表、写入数据和删除表等操作,是集群健康度的最后一道防线。
在发现硬件故障时,能及时下线故障节点,待问题修复之后再重新上线,或者用备用机替换故障机;在程序崩溃时,能够自动拉起等,这些操作都在我们管控面中进行,可以做到分钟级处理。而针对这些故障,每次大促前都会进行演练以提升操作熟练度。在上层应用中,也有响应的缓存、限流和分流功能。
我们在ClickHouse的日常使用中,积累了较多的经验也遇到不少问题,部分问题通过某些手段进行了规避和优化,如上文的集群规划和高可用架构,但是依然存在一些从架构层面比较难以解决的问题。
ClickHouse并发能力,因为CH是MPP架构,分布式表的查询会分发到所有节点去执行,每个分片的节点都会参与计算,并发能力和单机是一样的,增加副本可以提升并发能力。另一方法是提升单个查询的查询性能,比如通过改写SQL、物化视图或者字典表的使用降低查询时间。在查询时间优化到几十毫秒以内,增加副本数可以让QPS达到数千甚至上万。
ClickHouse Join优化,CH的Optimizer不够自动化,很多SQL需要显式的指定执行顺序和优化参数。我们之前做过ClickHouse的TPC-DS的测试,大部分多表Join的SQL都需要改写,比如把Join改为子查询,改为本地表Join,设置distributed_group_by_no_merge去做分布式GroupBy等,改写之后的性能比较好,但大表和大表的Join在右表数据量达到千万级别之后,性能会急剧下降。
分布式的一系列问题。这个问题比较复杂,简单来说,CH中强依赖于ZK,而ZK的性能瓶颈和不可扩展性决定了CH的使用局限,另外一方面ClickHouse中的元数据管理很松散,缺乏统一的完整的解决方案。
1. ClickHouse把数据同步和DDL操作放在ZK中,产生两个问题,第一个问题是ZNode会随着节点和数据规模扩大,ZNode达到一定数量会引发访问ZK超时,第二个问题是没有保证ZK和CH之间元数据的一致性,经常出现ZK的元数据、节点的元数据、节点的本地数据之间不一致。
2. 不方便扩缩容,增加和减少副本是可以的,但是扩分片需要数据均衡,比如下图S1和S2两个分片,增加S3这个分片,需要把S1和S2的数据分发一部分到S3,这样就会涉及到数据在分片间移动,如何在线平滑的移动数据,是一个难解决的问题。
3. 导入事务和幂等性, ClickHouse可以支持100万内数据导入的原子性,这批数据要么都成功,要么都失败,但没有保证数据一致性和持久化,比如数据写入到某个副本中,写入后副本数据还没同步到其他副本,此时节点故障了,数据就丢失了。当开启了Spark的推测执行,或导数程序故障重启等问题时,会导入重复数据。也就是说CH的导数并未实现Exactly-once的语义。
京东的OLAP的实践规划,大致上按照提升高可用性,降低使用门槛,提升需求响应速度等方面展开。
统一元数据管理:为了解决上面的问题,我们目前正在研究基于Raft的ZooKeeper替代方案,一方面是提升吞吐量和容量,另一方面是需要和ClickHouse结合更加紧密,保存更多元数据类型以增强CH的分布式能力,比如节点状态,元数据管理,副本、分区和文件信息,并在此基础上形成弹性扩缩容的能力,集群迁移和备份恢复能力,以及跨数据中心数据复制能力。
管控面产品化:在使用CH和Doris的过程中,特别是大促的经历,让我们积累了大量的运维和故障处置脚本,我们正在把这些脚本进行产品化,让用户自助式使用OLAP,如资源申请,创建用户和库,自助式的监控报警,异常处理和性能诊断,对管理员侧,做到集群部署和管控,以及故障自动诊断和治愈。
云原生的OLAP:在容器化部署的同时,进一步实现云原生,利用HDFS和对象存储的优势,把存储层放到外部,避免数据的重复存储,节省导入时间,计算节点可以弹性扩缩容。存储分离出来之后,存储如何扩缩容,以及计算节点和存储分片之间如何映射,都是新的问题,这块需要继续研究。
其他方面如查询优化、分布式缓存、易用性提升等也都在规划之中。京东数据中心的OLAP团队,已有几千台服务器,覆盖交易、流量、算法等场景,同时我们也积极参与和回馈社区。
