
记一次 datax 数据导出作业 (从hive导出到oracle)的性能排查与优化
不管企业数据平台的底座是企业级数仓平台 eds,还是大数据数据湖 datalake,或者当前大热的湖仓一体 lakehouse, 抑或所谓的数据中台,大数据与RDBMS之间的数据导入和导出都是企业日常数据处理中常见的一环,该环节一般称为 e-t-l 即 extract-transform-load。市面上可用的 etl 工具和框架很多,如来自于传统数仓和BI圈的 kettle/informatica/datastage, 来自于hadoop生态圈的sqoop/datax,抑或使用计算引擎 spark/presto/flink 直接编写代码完成etl作业。
笔者在这里分享一次使用 datax 从 hive 导出数据到 oracle 的作业的性能问题的排查和优化思路,希望对大家类似问题的排查有所帮助。
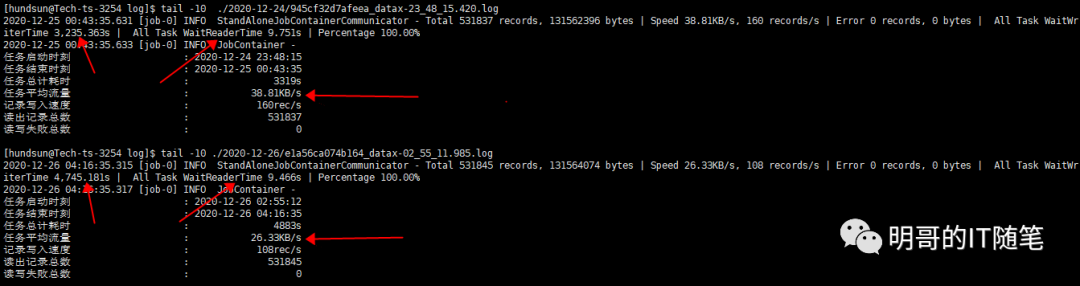
接到业务人员反馈导出作业执行很慢的消息后,笔者首先查看了对应的作业的datax的日志,以获得详细的性能指标,如下是最近两次作业执行的datax的日志,可见任务平均流量分别是上一次的 38KB/S 和 最近一次的26KB/S,这样的速度确实是有问题的,需要进一步排查;仔细留意日志可以发现Task waitWriterTime 是远远大于Task waitReaderTime,也就是说等待写的时间是远远大于等待读的时间的,所以性能跟读取上游 hive 数据 没有关系,瓶颈是在写入 Oracle 数据。
datax是相对成熟的框架,oracleWriter 插件也比较成熟,所以接下来的排查思路,一方面是去排查 oracle 数据库服务器的性能和oracle性能相关参数配置,另一方面是排查 oracle表的结构和索引等是否合理。
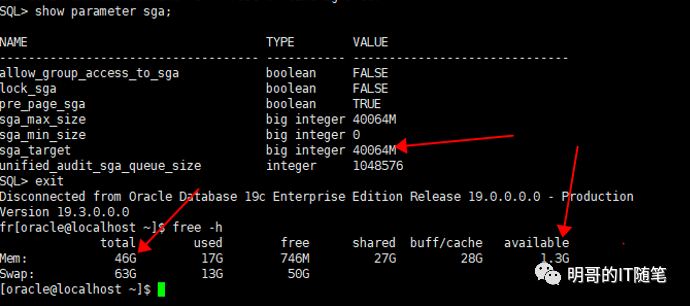
首先登陆数据库服务器节点,通过 df -h, free -h 和 top 三连发查看机器配置和当前负载, 磁盘和cpu都还好,但明显看到内存只有46g 且当前 available的只有1.3G了 (且配置的swap 为 63g);使用 sqlplus 登陆 oracle 数据库后,通过show parameter sga 可以看到配置的 sga_target 是40064MB, 相对于该节点实际的内存明显超配了;
尝试在该数据库服务器上执行一些简单的 sql 比如 select count(1) from tableA, 在后台通过 iostat -dmx 5 5 可以看到磁盘很容易就被打满到100%了:
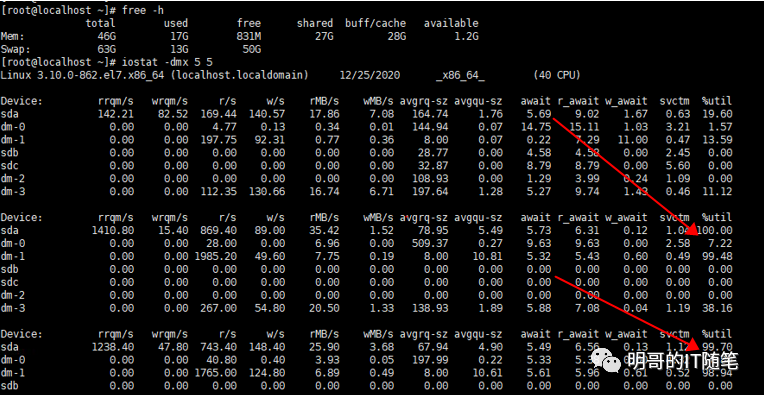
通过以上现象,可以确定数据库服务器的 io 性能有问题,且 oracle 中sga 等相关参数的设置跟机器实际情况不符;进一步跟其他没有问题的数据库节点对比了下磁盘io,差异不太大,至此可以确认 Io 问题主要是因为内存太小加上sga 参数超配造成了io 性能瓶颈。
为进一步确认表结构和使用方式有没有问题,可以查看数据库在对应sql执行时间段的 aws (automatic workloadrepository) 报告 (当然,需要 oracle数据库中生成了 sql 执行时间段前后的快照,才能生成 该时间段的 awr 报告。)。获得 awr 报告,需要在 plsql 中使用具有 dba 权限的用户登录oracle服务器,然后执行 @$ORACLE_HOME/rdbms/admin/addmrpt.sql。如下是使用该时间
段前后的快照生成的 awr 报告的关键截图:
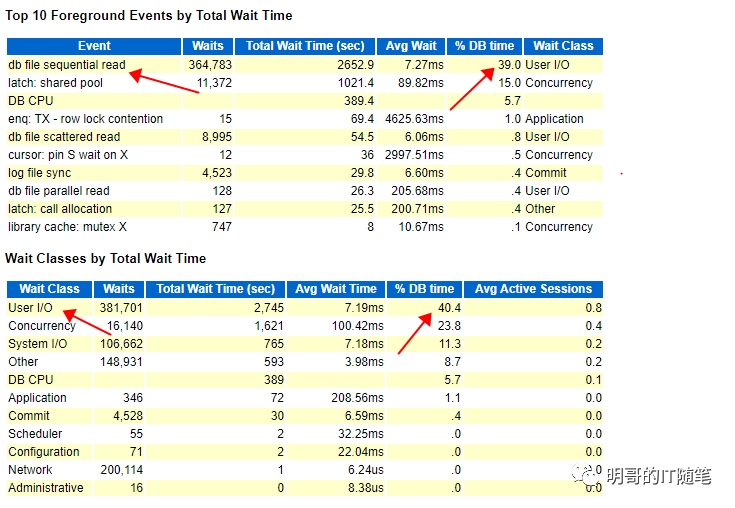
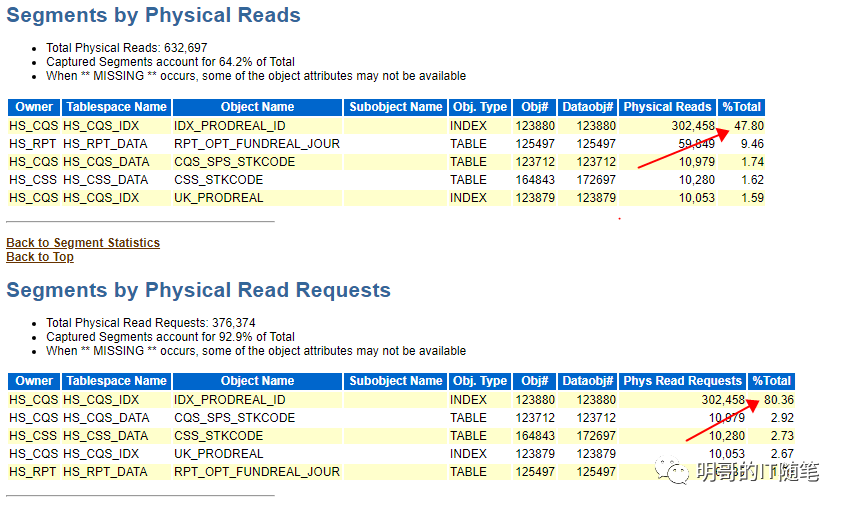
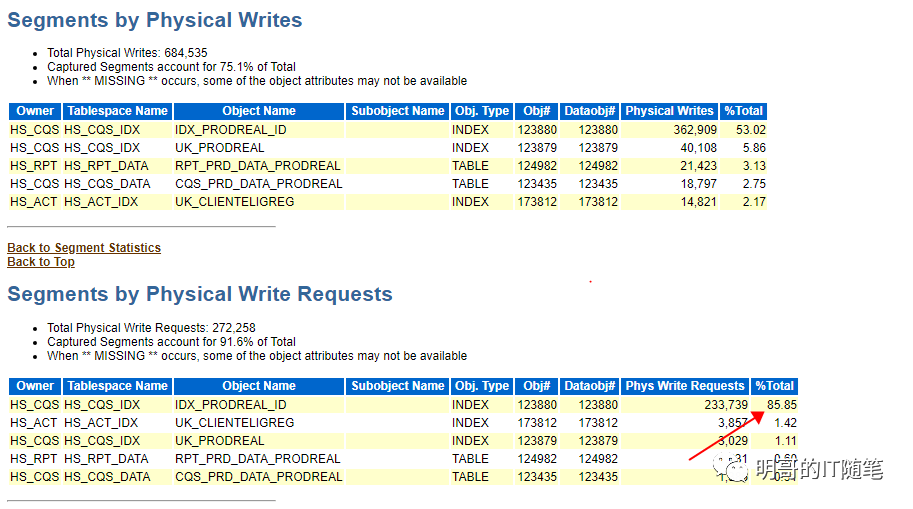
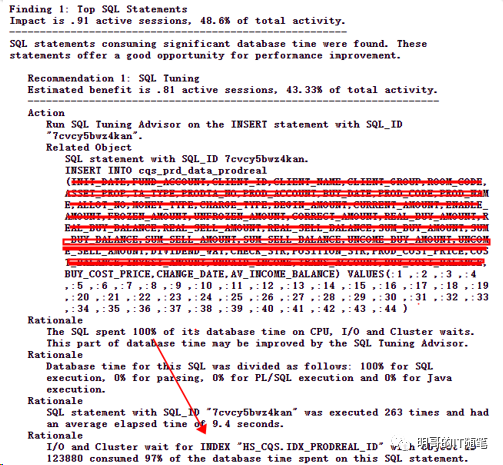
以上 awr 报告还是很详细的,反应出的问题也是比较明确,瓶颈在于hs_cqs.idx_prodreal_id 这个索引大量频繁的读和写,几个关键指标是 "top 10 foreground events by total time" 中 排名第一的是db filesequential read 占用了 39% db time; "segments by physical reads" 和 "segments by physical writes"排名第一的都是索引 "hs_cqs.idx_prodreal_id"且分别占用了 47% 和53%;在最后的 "find1: top sql statements" 部分,明确指出了 "i/o and cluster wait for index "hs_cqs.idx_prodreal_id" with object id xxx consumed 97% of the database time spend on this sql statemnt".
接下来顺藤摸瓜,查看下该表的结构和索引,发现该表是普通的 oracle 表没有分区,有唯一索引UK_PRODREAL (包含字段 INIT_DATE 和 POSITION_STR)和 普通索引IDK_PRODREAL_ID (包含字段CLIENT_ID 和 POSITION_STR);咨询业务人员,该表是历史产品持仓表,会保存大量历史数据,且业务日常查询中这两个索引都需要使用到,在每日的大数据批量插入时,插入的数据都是当天的数据。至此表结构和使用方式上的问题也比较清晰了,该表作为历史持仓表会保留大量数据,在批量插入某天数据时,需要维护包括 init_date 字段的索引和包括 client_id字段的另一个索引,由于插入的数据包含所有client的数据,所以维护包括client_id字段在内的那个索引也就是 awr 报告注指出的 IDK_PRODREAL_ID 索引时,需要大量的读和写该索引,开销很大,造成了大量 IO 等待。(维护包括inti_date 字段的索引相对来讲开销不会这么大,因为插入的所有数据都是属于一天的)。所以该表的结构需要调整,适合使用按月或按天的分区表而不是普通表,且索引比较适合使用分区表的 local 索引,这样实际批量插入数据时所需的耗时就不会受到历史存量数据的多少影响,而只会受需要插入的表分区的存量数据,需要插入的数据量,和数据库服务器性能的影响了。
综合以上所有分析,该问题的性能优化需要从两个方面着手:
一是业务调整:在表结构上调整目标表为按月或按天的分区表,并切换使用分区 local 索引,从而减少历史存量数据对插入速度的影响;在批量插入时批量的大小上,修改datax 作业配置参数batchSize调大批次大小;(datax中该参数默认值是1024,该值可以极大减少DataX与Oracle的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。)
二是数据库服务器端调整:需升级数据库服务器从当前的 40 cores, 46GB 升级为 比如48 cores, 128GB,服务器升级完毕后需要 DBA进一步相应调整该oracle实例的 SGA 等性能相关参数。
生成 oracle awr 和 addm报告的方式如下:( awr 报告包括 addm 报告的内容):首先通过 plsql 使用有 dba 权限的用户登录:sqlplus <用户名>[/<密码>][@<服务名>] as sysdba,然后执行以下命令生成报告:(互动式生成报告,需要指定报告对应的起始快照和结束快照,如果数据库没有配置自动定时生成快照,没有对应时间点的起始快照和结束快照,则无法生成对应时间点的 awr 或 addm 报告;手工生成快照可以使用命令exec dbms_workload_repository.create_snapshot):
@$ORACLE_HOME/rdbms/admin/awrrpt.sql
@/$ORACLE_HOME/rdbms/admin/addmrpt.sql
oracel关键性能参数的查看和修改:
show parameter sga;
show parameter pga;
show parameter db_cache;
show parameter shared_pool;
alter system set sga_target=350m scope=spfile/both/memory;
alter system set SGA_MAX_SIZE=270m scope=spfile;
alter system set db_cache_size=50M scope=both;
alter system set shared_pool_size=90M scope=both;
alter system set pga_aggregate_target=90M scope=both;
select name,bytes/1024/1024 "size(MB)",resizeable from v$sgainfo;
select component,current_size/1024/1024 "size(MB)" from v$sga_dynamic_components;
select name,issys_modifiable from v$parameter where name like '%sga%';
select sum(pinhits) / sum(pins) * 100 "hit-ratio" from v$librarycache;
SELECT a.VALUE "cache-hit-ratio" FROM V$PGASTAT a where a.NAME = 'cache hit percentage';
select (1 - ((physical.value - direct.value - lobs.value) / logical.value)) * 100 "命中率"
from v$sysstat physical,
v$sysstat direct,
v$sysstat lobs,
v$sysstat logical
where physical.name = 'physical reads'
and direct.name = 'physical reads direct'
and lobs.name = 'physical reads direct (lob)'
and logical.name = 'session logical reads';
注意:
oracle10g 后有了内存动态分配的新特性,只要设置 SGA_TARGET 为非零值,那么内存组件就是采用自动动态分配原则,由Oracle自动调整各内存组件的大小;相反如果把SGA_TARGET设置为0,即表示禁用10g中自动动态分配内存新特性,这样我们可以对各个内存组件的值进行单独设置。(一般不建议禁用自动动态分配内存的新特性,只有特殊的应用场景才需要);
alter system 有一个scope选项,它有三个可选值:memory,spfile,both:
memory:只改变当前实例的参数,如果重启Oracle,则会恢复到修改前的值;spfile:只改变spfile的参数,在Oracle重启后会使用修改后的值,spfile是指Oracle启动时用到的配置文件,一些参数都保存在这个文件里,Oracle在启动时读取这个文件并进行相应的初始化设置;both:改变实例及spfile的参数。
参考链接:
https://docs.oracle.com/database/121/CNCPT/intro.htm#CNCPT88788