
嵌入式模块化编程—— 层次框架初探
【说在前面的话】
模块化的目的是什么?—— 复用代码,节省开发时间;
阻碍模块化实现其最初目的的障碍是什么?—— 把原本的黑盒子当成白盒子,或者更通俗的说:阅读模块的源代码;
能不能介绍一种模块化的方法?—— Service模型;
如何在Service模型的基础上真正把模块做成黑盒子?—— 掩码结构体;
如果你错过了上述内容,可以单击破折号后面的关键字跳转到对应的文章进行阅读。正如你所看到的,这一系列问题实际上也正是沿着一个常见的思维过程展开的。一般来说,当我们学习过Service模型后,就有能力制作出一个个积木,并将这些积木在各种不同的项目环境中使用起来——我们可以这么理解:
模块的内部不仅对外是不可见的,本质上也不依赖于模块的外部环境;
模块的内部可以被认为是一个独立的小世界:
一方面根据事先约定的有限的接口通过接口头文件与外界交互;
一方面通过配置头文件(app_cfg.h)从外界接收“范围可控”的配置信息;
既然是独立的小世界,无论外部的工程环境如何,模块本身都可以正常的编译或者参加链接——换句话说,通过拷贝模块目录的方式应该就算是带上了模块的全部家当;
【从平面到立体的转变】
它们是如何组装在一起的;
它们之间的领导和被领导关系是怎样的。
对于第一个问题,可以打个比方:
我家仓库里有很多书,这些书最初是杂乱的堆积在地上,查找书籍非常痛苦。 我先找来几个盒子,把同类书籍都放在相同的盒子里。此时,盒子上就可以贴上标签,比如,编程类图书、小说、厨艺书籍、杂志等等(当然分类可以更细); 接下来,我又找来更大的箱子,贴上标签:工作类的书籍、休闲类的书籍、要收藏的书籍、要捐献的书籍等等。然后把之前的几个纸盒子按照这些属性放置到大箱子里。 最后,我给仓库贴了一个标签:傻孩子的私人藏书。如果家里来了同样是书虫的客人,便会不无炫耀的带着他们参观一番。
这种按照功能或者某种功能原则对内容进行归类,并套娃式的封装的行为,跟我们进行层次化封装时候所做的事情是一样的。如你所见,如何分类、遵循怎样的原则是一个非常主观的事情,可以非常确定的说,这里没有永远正确的方法和标准,只有不同人基于自己能力、阅历、经验以及项目的不同要求而做出的判断——很多时候,评论他人的模块封装如何的不好,基本上就等于评论他人的能力或者品味——是引战的代名词。
本文也许会不小心介绍一些所谓的“划分原则”,这里首先约定一下,无论我说的如何“言之凿凿”、仿佛是“普世真理”一般,请相信我,这仍然只是基于我个人的主观看法——并不具有任何客观性(这也是为什么我一再强调“计算机科学是唯心”的这一说法的原因)。基于这样的约定,如果你对我的所谓“划分原则”有什么腹诽,还请多多见谅,请记住这句话:这里不存在什么“我是对的你就是错的”之类的问题——如果你坚持,那么结论就是“我是错的,你是对的”——结案了。
原本平铺在地上的书被立体的堆积了起来,这就是层次框架;而堆积过程中的指导原则就是整个框架的设计理念——记住,混乱的理念也是理念;前后矛盾的理念也是理念——只要你把书堆起来了,就有一个理念,哪怕你说,“我没想那么多,也就是看到空盒子就装起来”——不好意思,这也是你的理念。
对应到软件框架上,我们可以看到,实践中有大量理念混乱复杂的系统,仍然运行的非常好,只不过人们亲切的称呼他们为祖传屎山,然后默默的敬而远之。

实际上,1)设计理念统一、2)简洁、3)可执行且4)执行力充分是每一个好框架在设计之初都曾设立过的美好梦想——可惜最终基本上没有谁完全实现这一愿景——如果每一项都用5星来衡量的话,对一个项目来说,平均下来这里列举的每一个目标都达到3星就是一个很好很好的软件框架了。

#include 本质上就是将指定的文件直接“包含”到当前的文件中,这一工作在预编译阶段完成——当进入编译阶段时,已经看不到任何#include了;
C编译器支持多个锚点,用户可以通过命令行 "-I<路径>"的方式添加一个新的锚点(或者通过IDE用户界面的方式来辅助添加);
每一个#include 都有一个默认锚点,也就是#include所在文件的当前目录;
对于每一个 "#include",编译器会按照一定的顺序尝试多个锚点——去看看,按照以某个锚点为基准的相对路径能不能找到对应的文件:如果找得到,则大功告成,找不到则再试试别的锚点。我们常说的 #include <> 和 include "" 的区别就是编译器尝试锚点的顺序区别,其中:
使用<> 表示编译器会首先从用户指定的锚点去查找路径,找不到了再去找默认锚点(也就是当前目录);
使用"" 表示编译器会首先尝试默认锚点,找不到了再去尝试用户指定的锚点;
基于上述事实,我们可以规定:
在一个层次框架模型中,只允许使用相对路径来进行模块间的引用;
除了默认锚点外,一个层次框架中,应该包含一个指向模块顶层模块目录的锚点——我们称之为根锚点。
当一个模块明确知道自己所引用的目标模块(或者头文件)相对自己的位置在未来是不太可能会变化时,推荐使用默认锚点——也就是以#include所在文件自己为锚点来描述相对路径;
当一个模块明确知道自己与目标模块的相对位置在未来是很可能会变化的;但目标模块相对根锚点的位置却不太可能会变化时,推荐使用根锚点来描述相对路径;
在某些极端(且应该极力避免)的情况下,一个模块完全不能确定目标模块的位置会如何变化——也就是即不知道相对自己会怎么变化,也不知道目标模块相对根锚点会如何变化——此时,应该直接#include 目标文件名,而不包含任何路径信息。这样做的目的本质上就是甩锅给用户——请“您”在工程配置里为这个“只有您会知道会放在那里”的目标模块配置一个锚点。我们把这种锚点叫做用户锚点。这里,我们人为规定:应该避免用户锚点的使用——需要注意的是,这里没有任何客观的关于对错的判断,请避免不必要的对错性争论。
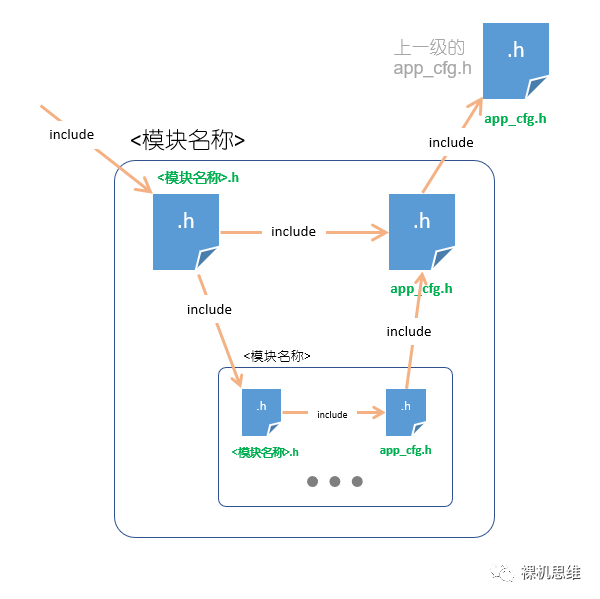
在介绍service模型的文章末尾,我们指出了一个令人头疼的问题:即,如果每个模块都有一个app_cfg.h,那么层次结构下往往会有一串的“app_cfg.h”。这一问题在IDE环境下进行头文件包含路径展开时尤为突出——简直到了不能容忍的地步——广大service模型爱好者亲切的称之为“app_cfg.h的鬼畜”。借助锚点,我们就能轻松的解决这一问题,思路如下:
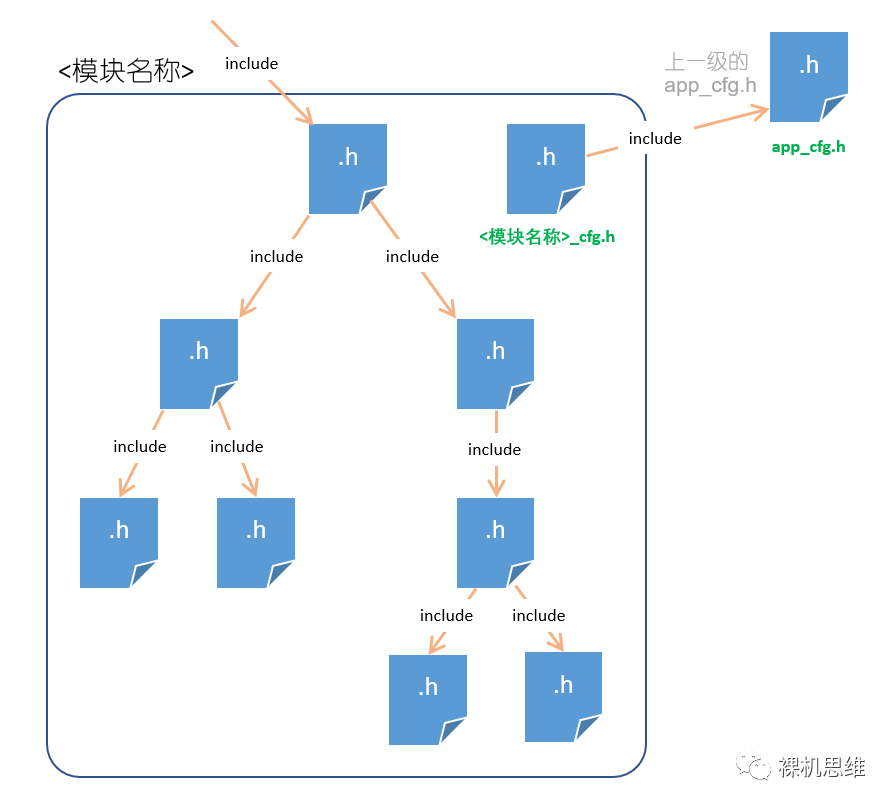
每一个拥有复杂纵深的大模块在最顶层,根据模块的名称建立一个唯一的配置头文件 "<模块名称>_cfg.h";
删除所有子模块自己的 app_cfg.h;
由于该配置头文件相对模块顶层目录的位置是固定的,因此大模块内所有的文件都以相对根锚点描述的相对路径来包含"<模块名称>_cfg.h";
具体情况如下图所示(注意,为了美观,这里把每个子模块对"<模块名称>_cfg.h"的#include箭头都省略了):
【模块间调用/引用规约】
它们是如何组装在一起的;
它们之间的领导和被领导关系是怎样的。
其中,模块间的领导与被领导关系与现实中的公司内部结构非常类似,表现为部门间的协作原则也可以被“直接”拿过来用于指导模块间的协作关系。下面,我就为大家介绍三条关键的基本原则:
跨部门(必须)调老大原则;
同部门(至少)平级调用原则;
以及
领导避讳原则。
跨部门(必须)调用老大原则
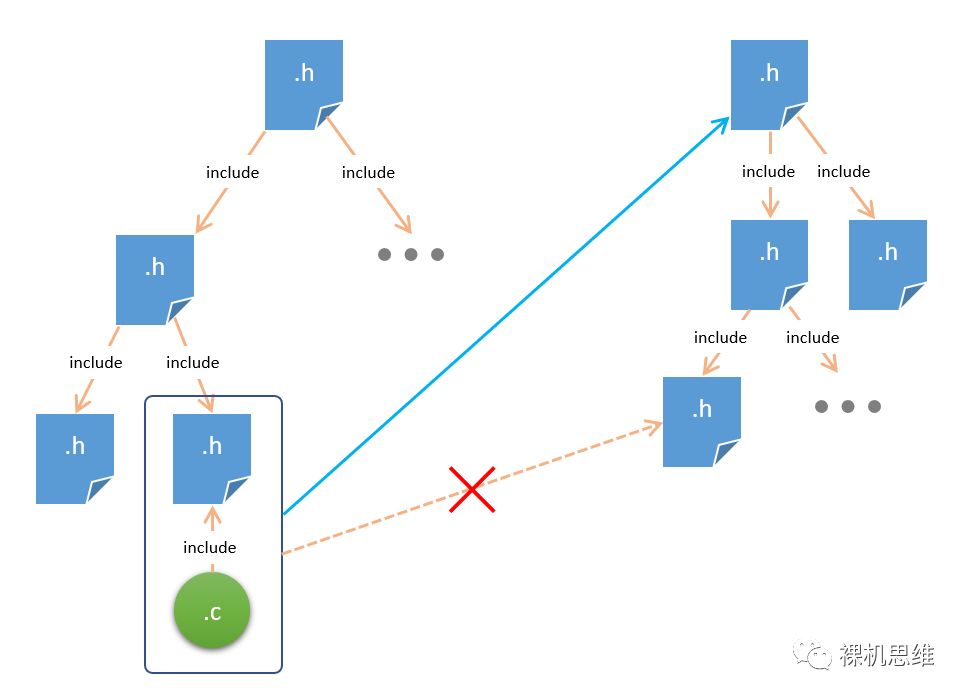
在这一图中,左边方框所表示的模块尝试去包含右边大部门内的一个子模块(橙色虚线所示),根据“调老大”原则,我们不能绕开“隔壁部门”的老大而去直接给它的小弟布置任务。
同部门(至少)平级调用原则
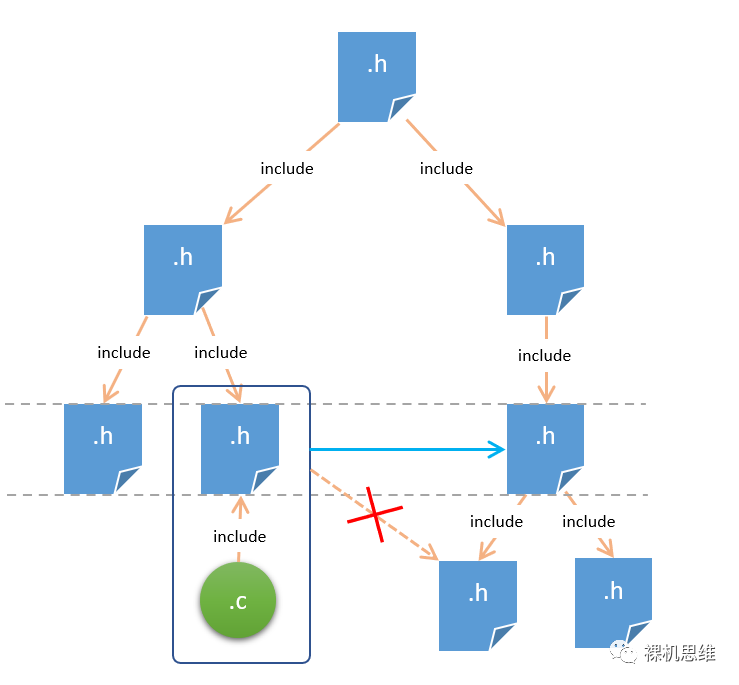
在图中,左边方框中的模块与右边它想包含的模块同属于一个大部门。由于“平级调用”原则的限制,我们同样不能绕开隔壁团队的领导而去直接招呼人家的小弟。
领导避讳原则
对一个接口头文件来说,无论如何都不能直接或者间接的包含自己的“领导”;
在这一前提基础上,我们应该尽可能也去“调老大”——哪怕隶属于同一大模块。
一个具体的例子如下图所示:
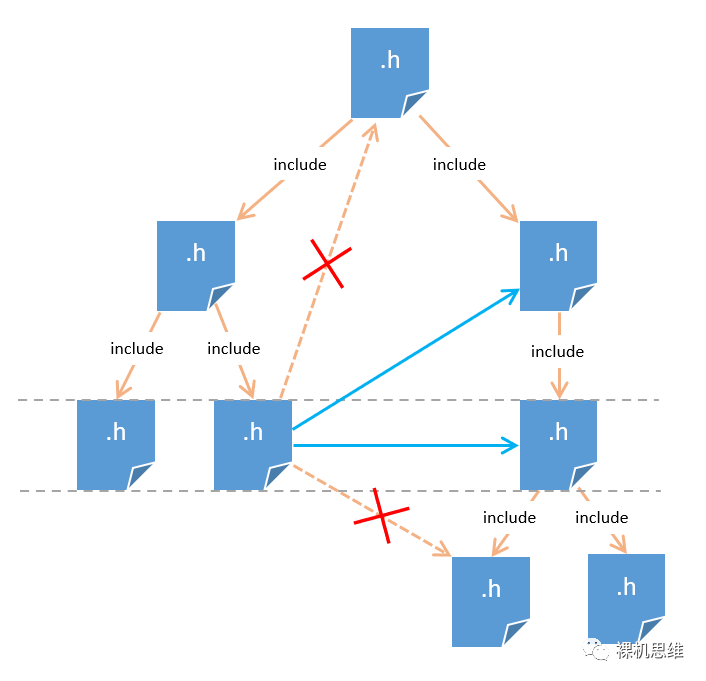
在途中,一个模块的接口头文件试图去包含隔壁部门的小弟,考虑到“尽快可能掉老大”的要求,以及“避讳领导”的限制,图中就有了两条可行的包含方案(以蓝色箭头表示)——实际上,选择最大的有效领导(也就是斜向上的蓝色箭头所示的头文件)才是我们所推荐的。
其实,如果你理解了上述三条原则,你很快就会发现一句更为凝练的口诀,即:避开自己的领导,尽可能调老大,完毕。
【不是结束的后记】
计算机技术是“唯心的”,只不过,谁的话语权强大,谁说了算;
除了少数与数学、物理、经济学(分配资源相关的知识)有关的硬核理论外,更多的计算机技术和术语都是像你我这样普普通的一线程序员从生活中借鉴而来的——所以说,加油吧,打工人。
如果你喜欢我的思维、觉得我的文章对你有所启发,
请务必 “点赞、收藏、转发” 三连,这对我很重要!谢谢!
欢迎订阅 裸机思维