
GPT-4就是AGI!谷歌斯坦福科学家揭秘大模型如何超智能

新智元报道
新智元报道
【新智元导读】谷歌研究院和斯坦福HAI的两位专家发文称,现在最前沿的AI模型,未来将会被认为是第一代AGI。最前沿的LLM已经用强大的能力证明,AGI即将到来!





什么是通用人工智能?

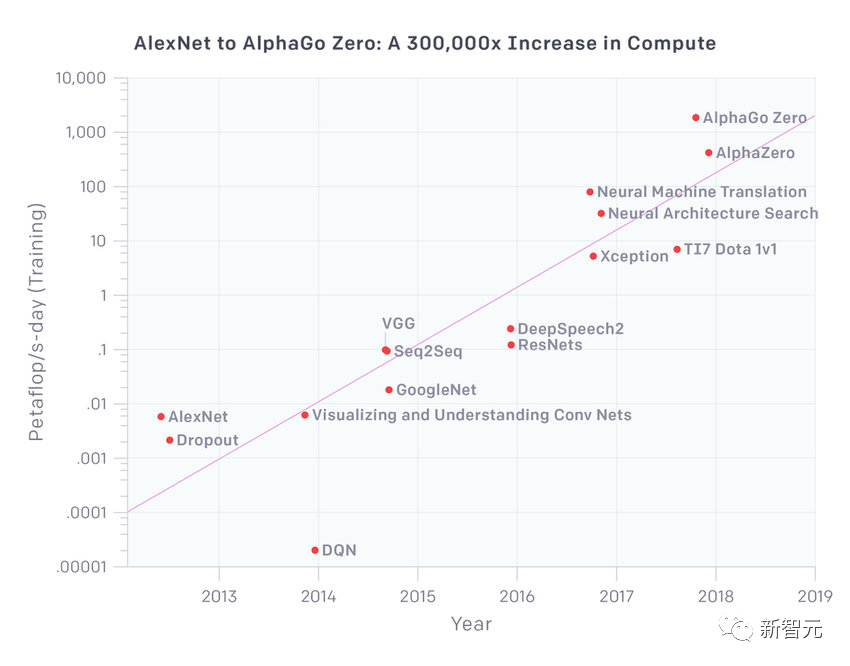
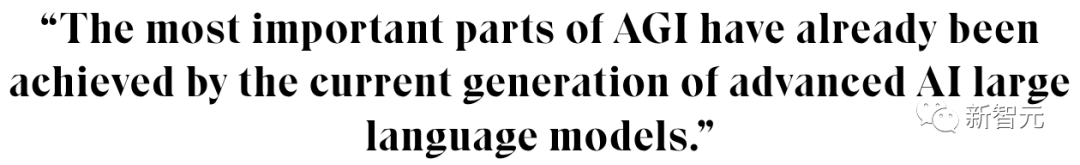

如何设定AGI的评价指标

LLM能考试,却不能当医生

说话流畅=智能高?

忽然涌现的LLM能力


为什么计算机编程+语言学≠AGI?

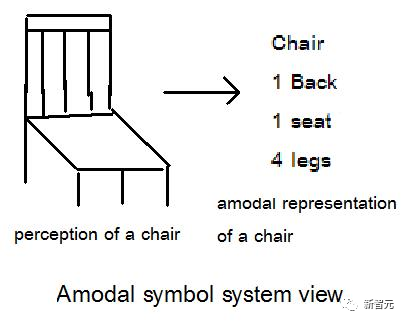

LLM的推理和语言跟人类截然不同







人类凭什么是「独一无二」的?

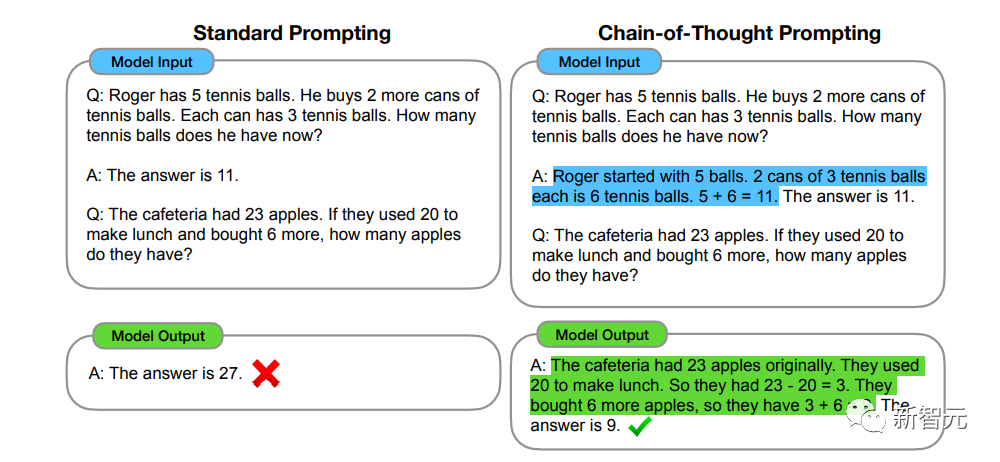



AGI会对人类社会造成什么样的影响?




评论