
统计学小抄:常用术语和基本概念小结

来源:DeepHub IMBA 本文约2200字,建议阅读5分钟
统计学是涉及数据的收集,组织,分析,解释和呈现的学科。
统计的类型
数据的类型
数据分布度的度量
按顺序排列数字 将列表切成4个相等的部分 4分的切分点就是4分位数的值
正态分布
P[mean - std_dev <= mean + std_dev] = 68%P[mean - 2*std_dev <= mean + 2*std_dev] = 95%P[mean - 3*std_dev <= mean + 3*std_dev] = 99.7%
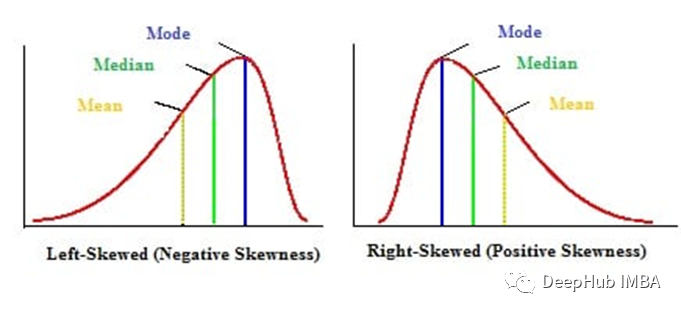
偏态
中心极限定理
概率密度函数(PDF)
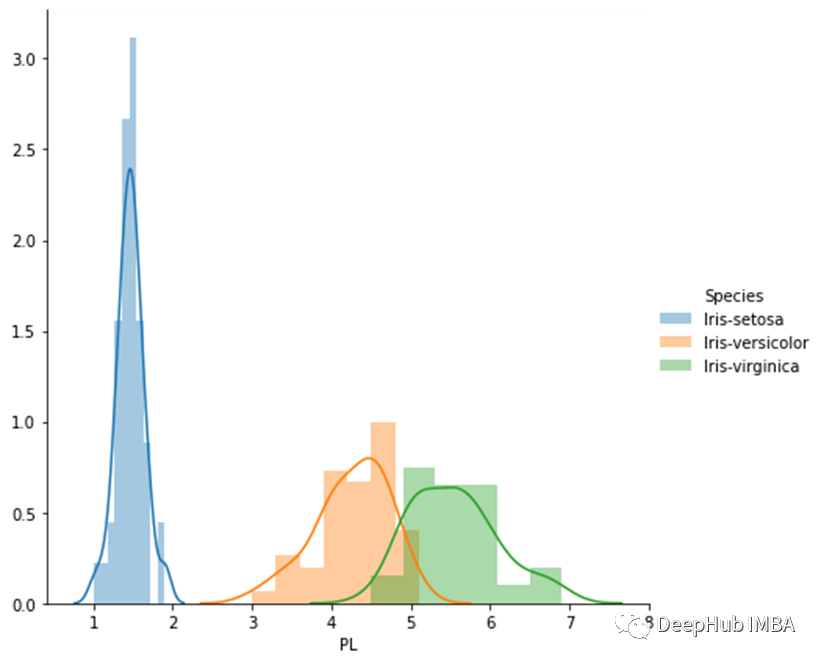
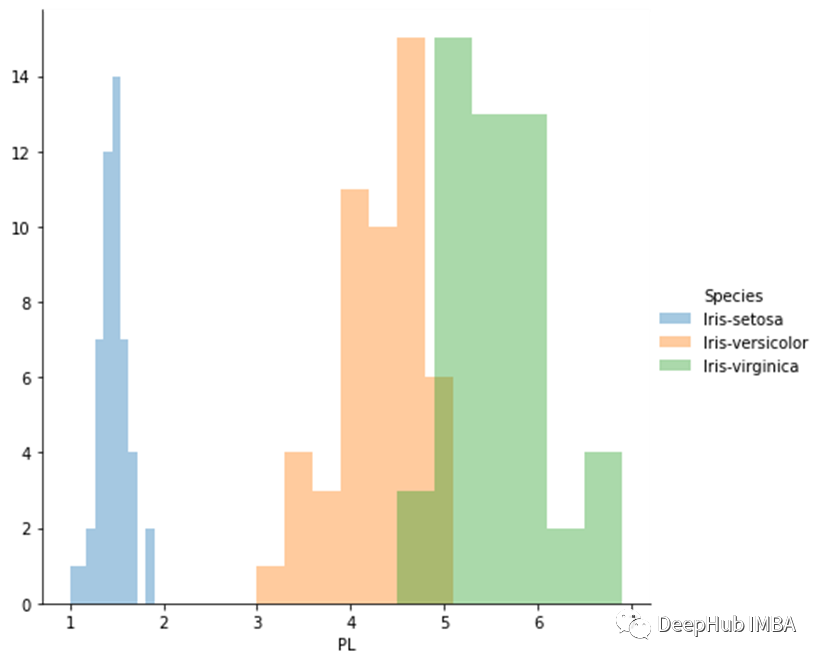
累积分布函数(CDF)
如何计算PDF和CDF
ounts, bin_edges = np.histogram(iris_setosa[‘PL’], bins=10)pdf = counts / sum(counts)cdf = np.cumsum(pdf)print(pdf)print(cdf)
评论