
新兴前端框架 Svelte 从入门到原理
在这篇文章中,我们将会介绍 Svelte 框架的特性、优缺点和底层原理。
本文尽量不会涉及 Svelte 的语法,大家可以放心食用。因为 Svelte 的语法极其简单,而且官方教程学习曲线平缓https://www.sveltejs.cn/,相信大家很快就会上手语法的,这里就不做官网搬运工了。
前端领域是发展迅速,各种轮子层出不穷的行业。最近这些年,随着三大框架React、Vue、Angular版本逐渐稳定,前端技术栈的迭代似乎缓慢下来,React 16版本推出了 Fiber, Vue 3.0 也已经在襁褓之中。
如果我们把目光拉伸到未来十年的视角,前端行业会出现哪些框架有可能会挑战React或者Vue呢?我们认为,崭露头角的 Svelte 应该是其中的选项之一。
Svelte 简介
Svelte叫法是[Svelte], 本意是苗条纤瘦的,是一个新兴热门的前端框架。

在最新的《State of JS survey of 2020》中,它被预测为未来十年可能取代React和Vue等其他框架的新兴技术。如果你不确定自己是否该了解 Svelte,可以先看一下 Svelte 的一些发展趋势。
开发者满意度
从2019年开始, Svelte出现在榜单中。刚刚过去的2020年,Svelte在满意度排行榜中超越了react,跃升到了第一位。
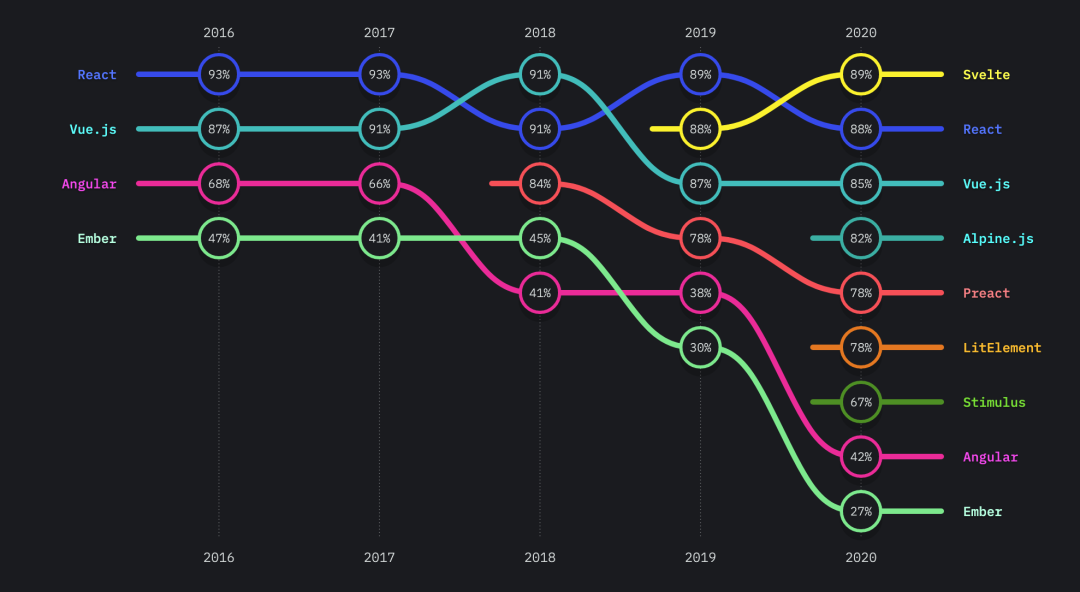
开发者兴趣度
在开发者兴趣度方面,Svelte 蝉联了第一。
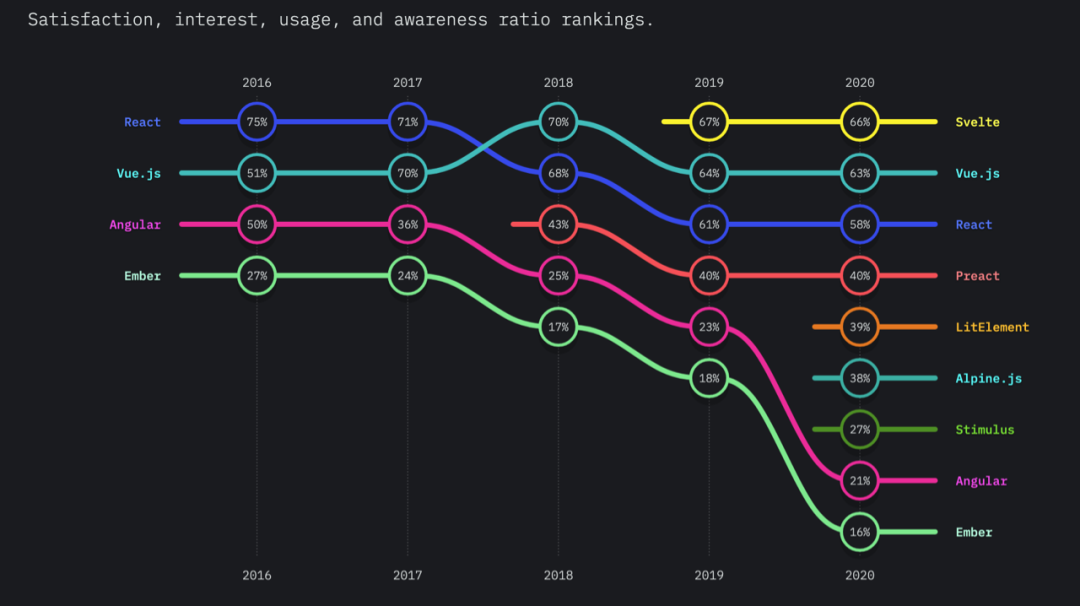
市场占有率
如果你在19年还没有听说过Svelte,不用紧张,因为svelte 当时仍是小众的开发框架,在社区里仍然没有流行开来。
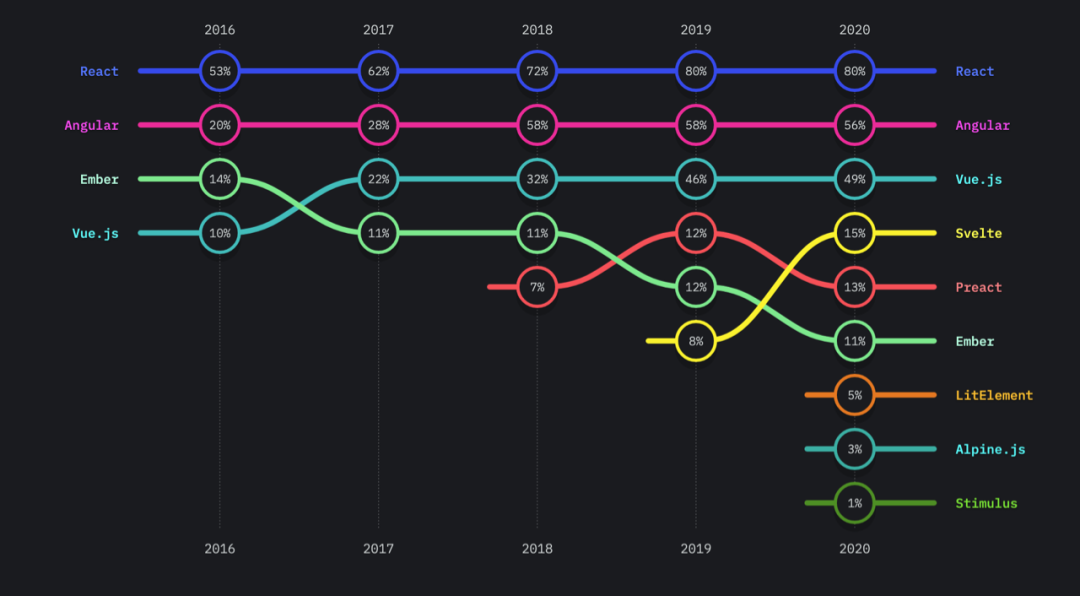
2020年,Svelte 的市场占有率从第6名跃升到第4名,仅次于 React、Angular、Vue 老牌前端框架。
svelte作者——Rich Harris

Svelte作者是前端轮子哥 Rich Harris,同时也是 Rollup 的作者。Rich Harris 作者本人在介绍 Svelte 时,有一个非常精彩的演讲《Rethinking reactivity》,油管连接:https://www.youtube.com/watch?v=AdNJ3fydeao&t=1900s,感兴趣的同学不要错过。
他设计 Svelte 的核心思想在于『通过静态编译减少框架运行时的代码量』,也就是说,vue 和 react 这类传统的框架,都必须引入运行时 (runtime) 代码,用于虚拟dom、diff 算法。Svelted完全溶入JavaScript,应用所有需要的运行时代码都包含在bundle.js里面了,除了引入这个组件本身,你不需要再额外引入一个运行代码。
Svelte 优势有哪些
我们先来看一下 Svelte 和React,Vue 相比,有哪些优势。
No Runtime —— 无运行时代码
React 和 Vue 都是基于运行时的框架,当用户在你的页面进行各种操作改变组件的状态时,框架的运行时会根据新的组件状态(state)计算(diff)出哪些DOM节点需要被更新,从而更新视图。
这就意味着,框架本身所依赖的代码也会被打包到最终的构建产物中。这就不可避免增加了打包后的体积,有一部分的体积增加是不可避免的,那么这部分体积大约是多少呢?请看下面的数据:

常用的框架中,最小的Vue都有58k,React更有97.5k。我们使用React开发一个小型组件,即使里面的逻辑代码很少,但是打包出来的bundle size轻轻松松都要100k起步。对于大型后台管理系统来说,100k 不算什么,但是对于特别注重用户端加载性能的场景来说,一个组件100k 多,还是太大了。
如果你特别在意打包出来的体积,Svelte 就是一个特别好的选择。下面是Jacek Schae大神的统计,使用市面上主流的框架,来编写同样的Realword 应用的体积:

从上图的统计,Svelte简直是神奇!竟然只有 9.7 KB ! 果然魔法消失 UI 框架,无愧其名。
可以看出,Svelte的bundle size大小是Vue的1/4,是React的1/20,体积上的优势还是相当明显的。
Less-Code ——写更少的代码
在写svelte组件时,你就会发现,和 Vue 或 React 相比只需要更少的代码。开发者的梦想之一,就是敲更少的代码。因为更少的代码量,往往意味着有更好的语义性,也有更少的几率写出bug。
下面的例子,可以看出Svelte和React的不同:
React的代码
const [count, setCount] = useState(0);
function increment() {
setCount(count + 1);
}
Svelte的代码
let count = 0;
function increment() {
count += 1;
}
虽然用上了16版本最新的 hooks,但是和svelte相比,代码还是很冗余。
在React中,我们要么使用useState钩子,要么使用setState设置状态。而在Svelte中,可以直接使用赋值操作符更新状态。
如果说上面的例子太简单了,可以看下面的统计,分别使用 React 和 Svelte 实现下面的组件所需要的代码行数
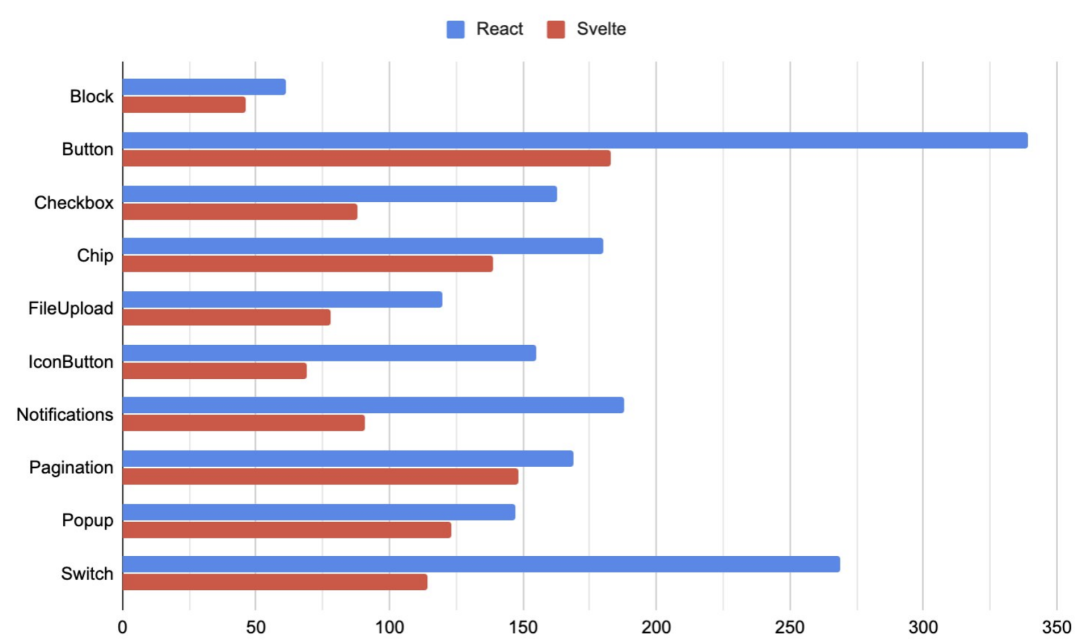
下面还是 Jacek Schae 老哥的统计,编写同样的Realword 应用,各个框架所需要的行数

Vue 和 React 打了平手,Svelte 遥遥领先,可以少些 1000 行代码耶!早日下班,指日可待。
Hight-Performance ——高性能
在Virtual Dom已经是前端框架标配的今天, Svelte 声称自己是没有Virtual Dom加持的, 怎么还能保证高性能呢?
不急,慢慢看。
性能测评
Jacek Schae 在《A RealWorld Comparison of Front-End Frameworks with Benchmarks》中用主流的前端框架来编写 RealWorld 应用,使用 Chrome 的Lighthouse Audit测试性能,得出数据是Svelte 略逊于Vue, 但好于 React。
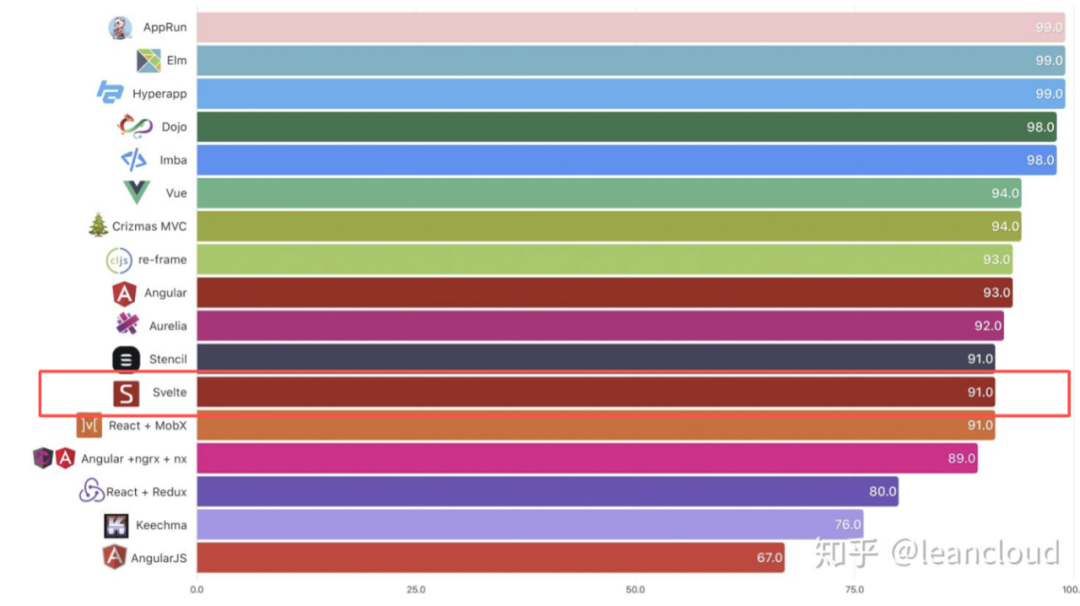
是不是很惊奇?另外一个前端框架性能对比的项目也给出了同样的答案:https://github.com/krausest/js-framework-benchmark。
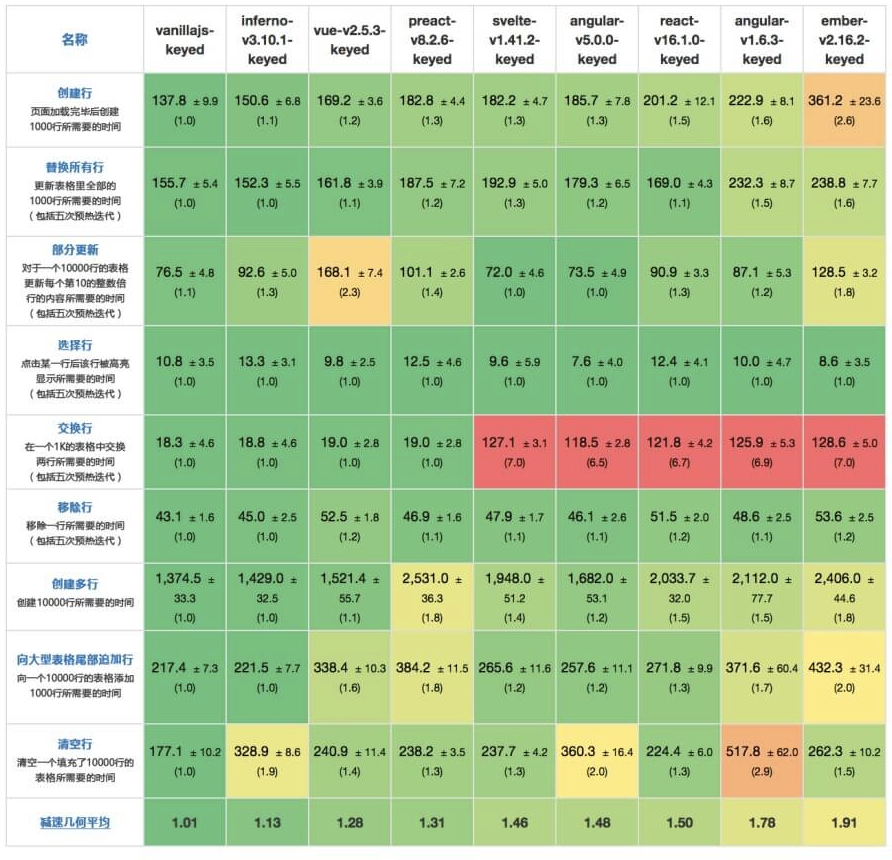
为什么 Svelte 性能还不错,至少没有我们预期的那么糟糕?我们接下来会在原理那一小结来介绍。
Svelte 劣势
说完了 Svelte 的优势,我们也要考虑到 Svelte 的劣势。
和Vue, React框架的对比
在构建大型前端项目时,我们在选择框架的时候就需要考虑更多的事情。Svelte 目前尚处在起步阶段,对于大型项目必要的单元测试并没有完整的方案。目前在大型应用中使用 Svelte , 需要谨慎评。
| 类目 | Svelte | Vue | React |
|---|---|---|---|
| UI 组件库 | Material design ( 坦率的说,不好用 ) | Element UI / AntD | AntD / Material design |
| 状态管理 | 官网自带 | Vuex | Redux/MobX |
| 路由 | Svelte-router | Vue-router | React-router |
| 服务端渲染 | 支持 | 支持 | 支持 |
| 测试工具 | 官方网站没有相关内容 | @vue/test-utils | Jest |
我们在用 Svelte 开发公司级别中大型项目时,也发现了其他的一些主要注意的点
没有像AntD那样成熟的UI库。比如说需求方想加一个toast提示,或者弹窗,pm:”很简单的,不用出UI稿,就直接用之前的样式好啦~“
但是 Svelte 需要从0开始 ”抄“ 出来一个toast或者弹窗组件出来,可能会带来额外的开发量和做好加班的准备。
Svelte 原生不支持预处理器,比如说
less/scss,需要自己单独的配置 webpack loader。Svelte 原生脚手架没有目录划分
暂时不支持typescript,虽然官方说了会支持, 但是不知道什么时候.
还需要注意的一点是,React / Vue等框架自带的runtime虽然会增加首屏加载的bundle.js,可是当项目变得越来越大的时候,框架的runtime在bundle.js里面占据的比例也会越来越小,这个时候我们就得考虑一下是不是存在一个Svelte生成的代码大于React和Vue生成的代码的阈值了。
原理篇
Svelte 原理相对于 React 和 Vue 来说,相对比较简单,大家可以放心的往下看。
首先,我们从一个问题出发:
Virtual Dom 真的高效吗
Rich Harris 在设计 Svelte 的时候没有采用 Virtual DOM 是因为觉得Virtual DOM Diff 的过程是非常低效的。
在他的一文《Virtual DOM is pure overhead》原文连接:https://www.sveltejs.cn/blog/virtual-dom-is-pure-overhead,感兴趣的同学可以翻一下。
人们觉得 Virtual DOM高效的一个理由,就是它不会直接操作原生的DOM节点。在浏览器当中,JavaScript的运算在现代的引擎中非常快,但DOM本身是非常缓慢的东西。当你调用原生DOM API的时候,浏览器需要在JavaScript引擎的语境下去接触原生的DOM的实现,这个过程有相当的性能损耗。
但其实 Virtual DOM 有时候会做很多无用功,这体现在很多组件会被“无缘无故”进行重渲染(re-render)。
比如说,下面的例子中,React 为了更新掉message 对应的DOM 节点,需要做n多次遍历,才能找到具体要更新哪些节点。

为了解决这个问题,React 提供pureComponent,shouldComponentUpdate,useMemo,useCallback让开发者来操心哪些subtree是需要重新渲染的,哪些是不需要重新渲染的。究其本质,是因为 React 采用 jsx 语法过于灵活,不理解开发者写出代码所代表的意义,没有办法做出优化。
所以,React 为了解决这个问题,在 v16.0 带来了全新的 Fiber 架构,Fiber 思路是不减少渲染工作量,把渲染工作拆分成小任务思路是不减少渲染工作量。渲染过程中,留出时间来处理用户响应,让用户感觉起来变快了。这样会带来额外的问题,不得不加载额外的代码,用于处理复杂的运行时调度工作
那么 Svelte 是如何解决这个问题的?
React 采用 jsx 语法本质不理解数据代表的意义,没有办法做出优化。Svelte 采用了Templates语法(类似于 Vue 的写法),更加严格和具有语义性,可以在编译的过程中就进行优化操作。
那么,为什么Templates语法可以解决这个问题呢?
Template 带来的优势
关于 JSX 与 Templates ,可以看成是两种不同的前端框架渲染机制,有兴趣的同学可以翻一下尤雨溪的演讲《在框架设计中寻求平衡》:https://www.bilibili.com/video/av80042358/。
一方面, JSX 的代表框架有 React 以及所有 react-like 库,比如 preact、 stencil, infernal 等;另一方面, Templates 代表性的解决方案有 Vue、Svelte、 ember,各有优缺点。

JSX 优缺点
jsx 具有 JavaScript 的完整表现力,非常具有表现力,可以构建非常复杂的组件。
但是灵活的语法,也意味着引擎难以理解,无法预判开发者的用户意图,从而难以优化性能。你很可能会写出下面的代码:
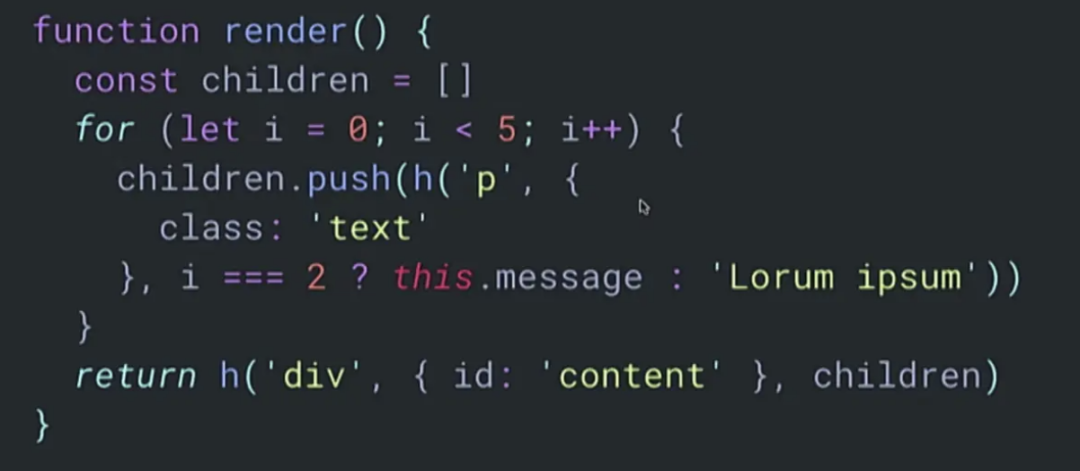
在使用 JavaScript 的时候,编译器不可能hold住所有可能发生的事情,因为 JavaScript 太过于动态化。也有人对这块做了很多尝试,但从本质上来说很难提供安全的优化。
Template优缺点
Template模板是一种非常有约束的语言,你只能以某种方式去编写模板。
例如,当你写出这样的代码的时候,编译器可以立刻明白:”哦!这些 p 标签的顺序是不会变的,这个 id 是不会变的,这些 class 也不会变的,唯一会变的就是这个“。

在编译时,编译器对你的意图可以做更多的预判,从而给它更多的空间去做执行优化。

左侧 template 中,其他所有内容都是静态的,只有 name 可能会发生改变。
右侧 p 函数是编译生成的最终的产物,是原生的js可以直接运行在浏览器里,会在有脏数据时被调用。p 函数唯一做的事情就是,当 name 发生变更的时候,调用原生方法把 t1 这个原生DOM节点更新。这里的 set_data 可不是 React 的 setState 或者小程序的 setData ,这里的set_data 就是封装的原生的 javascript 操作DOM 节点的方法。

如果我们仔细观察上面的代码,发现问题的关键在于 if 语句的判断条件——changed.name, 表示有哪些变量被更新了,这些被更新的变量被称为脏数据。
任何一个现代前端框架,都需要记住哪些数据更新了,根据更新后的数据渲染出最新的DOM
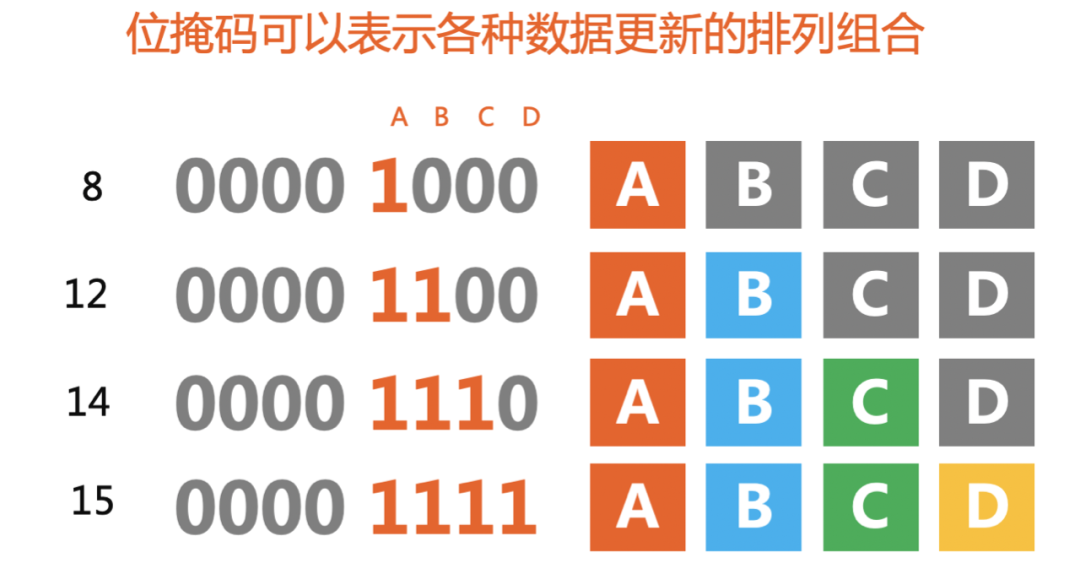
Svelte 记录脏数据的方式:位掩码(bitMask)
Svelte使用位掩码(bitMask) 的技术来跟踪哪些值是脏的,即自组件最后一次更新以来,哪些数据发生了哪些更改。
位掩码是一种将多个布尔值存储在单个整数中的技术,一个比特位存放一个数据是否变化,一般1表示脏数据,0表示是干净数据。
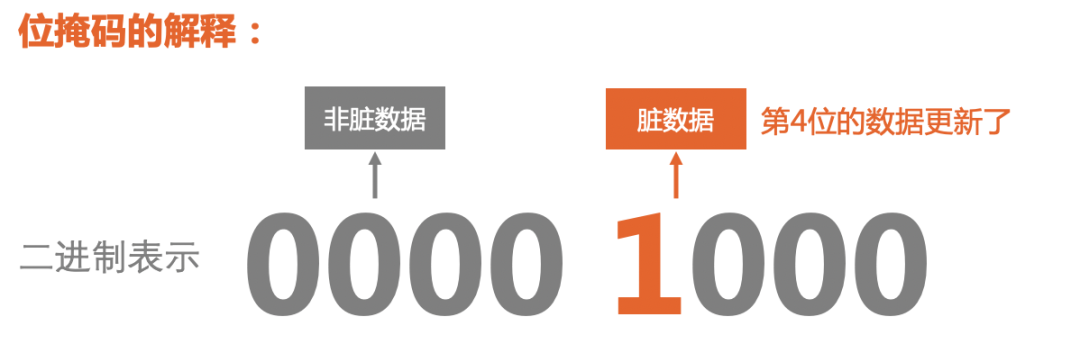
用大白话来讲,你有A、B、C、D 四个值,那么二进制0000 0001表示第一个值A发生了改变,0000 0010表示第二个值B发生了改变,0000 0100表示第三个值C发生了改变,0000 1000表示第四个D发生了改变。
这种表示法,可以最大程度的利用空间。为啥这么说呢?
比如说,十进制数字3就可以表示 A、B是脏数据。先把十进制数字3, 转变为二进制0000 0011。从左边数第一位、第二位是1,意味着第一个值A 和第二个值B是脏数据;其余位都是0,意味着其余数据都是干净的。
JS 的限制
那么,是不是用二进制比特位就可以记录各种无穷无尽的变化了呢?
JS 的二进制有31位限制,number 类型最长是32位,减去1位用来存放符号。也就是说,如果 Svelte 采用二进制位存储的方法,那么只能存 31个数据。
但肯定不能这样,对吧?
Svelte 采用数组来存放,数组中一项是二进制31位的比特位。假如超出31个数据了,超出的部分放到数组中的下一项。
这个数组就是component.$.dirty数组,二进制的1位表示该对应的数据发生了变化,是脏数据,需要更新;二进制的0位表示该对应的数据没有发生变化,是干净的。
一探究竟component.$.dirty
上文中,我们说到component.$.dirty是数组,具体这个数组长什么样呢?
我们模拟一个 Svelte 组件,这个 Svelte 组件会修改33个数据。
我们打印出每一次make_dirty之后的component.$.dirty, 为了方便演示,转化为二进制打印出来,如下面所示:

上面数组中的每一项中的每一个比特位,如果是1,则代表着该数据是否是脏数据。如果是脏数据,则意味着更新。
第一行
["0000000000000000000000000000001", "0000000000000000000000000000000"], 表示第一个数据脏了,需要更新第一个数据对应的dom节点第二行
["0000000000000000000000000000011", "0000000000000000000000000000000"], 表示第一个、第二个数据都脏了,需要更新第一个,第二个数据对应的dom节点。……
当一个组件内,数据的个数,超出了31的数量限制,就数组新增一项来表示。
这样,我们就可以通过component.$.dirty这个数组,清楚的知道有哪些数据发生了变化。那么具体应该更新哪些DOM 节点呢?
数据和DOM节点之间的对应关系
我们都知道, React 和 Vue 是通过 Virtual Dom 进行 diff 来算出来更新哪些 DOM 节点效率最高。Svelte 是在编译时候,就记录了数据 和 DOM 节点之间的对应关系,并且保存在 p 函数中。

这里说的p 函数,就是 Svelte 的更新方法,本质上就是一大堆if判断,逻辑非常简单
if ( A 数据变了 ) {
更新A对应的DOM节点
}
if ( B 数据变了 ) {
更新B对应的DOM节点
}
为了更加直观的理解,我们模拟更新一下33个数据的组件,编译得到的p 函数打印出来,如:

我们会发现,里面就是一大堆if判断,但是if判断条件比较有意思,我们从上面摘取一行仔细观察一下:

首先要注意,&不是逻辑与,而是按位与,会把两边数值转为二进制后进行比较,只有相同的二进制位都为1 才会为真。
这里的if判断条件是:拿compoenent.$.dirty[0](00000000000000000000000000000100)和4(4 转变为二进制是0000 0100)做按位并操作。那么我们可以思考一下了,这个按位并操作什么时候会返回1呢?
4是一个常量,转变为二进制是0000 0100, 第三位是1。那么也就是,只有dirty[0]的二进制的第三位也是1时, 表达式才会返回真。换句话来说,只有第三个数据是脏数据,才会走入到这个if判断中,执行set_data(t5, ctx[2]), 更新t5这个 DOM 节点。
当我们分析到这里,已经看出了一些眉目,让我们站在更高的一个层次去看待这 30多行代码:它们其实是保存了这33个变量 和 真实DOM 节点之间的对应关系,哪些变量脏了,Svelte 会走入不同的if体内直接更新对应的DOM节点,而不需要复杂 Virtual DOM DIFF 算出更新哪些DOM节点;
这 30多行代码,是Svelte 编译了我们写的Svelte 组件之后的产物,在Svelte 编译时,就已经分析好了,数据 和 DOM 节点之间的对应关系,在数据发生变化时,可以非常高效的来更新DOM节点。
Vue 曾经也是想采取这样的思路,但是 Vue 觉得保存每一个脏数据太消耗内存了,于是没有采用那么细颗粒度,而是以组件级别的中等颗粒度,只监听到组件的数据更新,组件内部再通过 DIFF 算法计算出更新哪些 DOM 节点。Svelte 采用了比特位的存储方式,解决了保存脏数据会消耗内存的问题。
整体流程
上面就是Svelte 最核心更新DOM机制,下面我们串起来整个的流程。
下面是非常简单的一个 Svelte 组件,点击<button>会触发onClick事件,从而改变name 变量。

上面代码背后的整体流程如下图所示,我们一步一步来看:
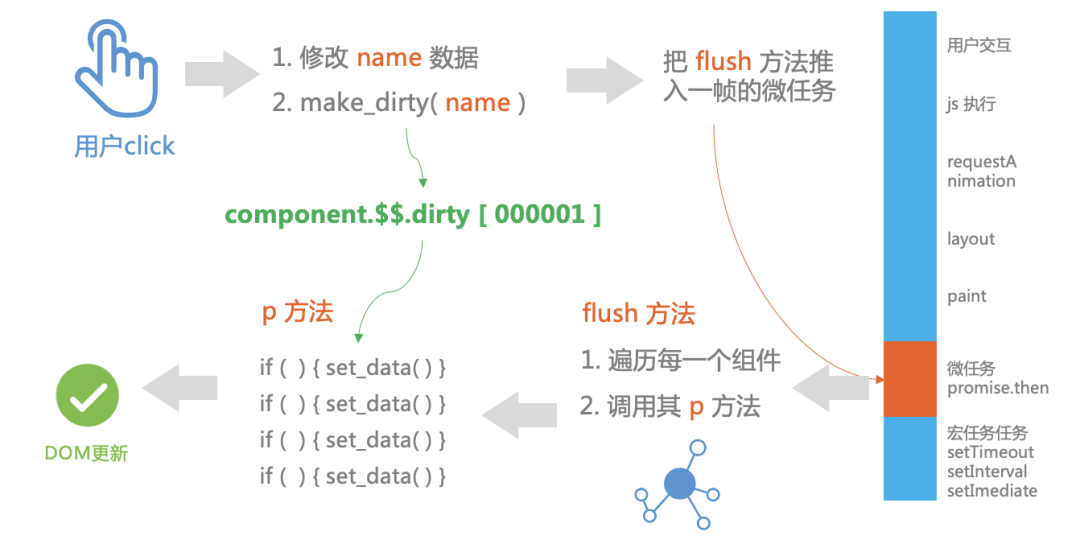
第一步,Svelte 会编译我们的代码,下图中左边是我们的源码,右边是 Svelte 编译生成的。Svelte 在编译过程中发现,『咦,这里有一行代码 name 被重新赋值了,我要插入一条make_dirty的调用』,于是当我们改写 name 变量的时候,就会调用make_dirty方法把 name 记为脏数据。

第二步,我们来看make_diry方法究竟做了什么事情:
把对应数据的二进制改为1
把对应组件记为脏组件,推入到 dirty_components 数组中
调用
schedule_update()方法把flush方法推入到一帧中的微任务阶段执行。因为这样既可以做频繁更新 的截流,又避免了阻塞一帧中的 layout, repaint 阶段的渲染。

schedule_update 方法其实就是一个promise.then(),

一帧大概有 16ms, 大概会经历 layout, repaint的阶段后,就可以开始执行微任务的回调了。
flush 方法做的事情也比较简单,就是遍历脏组件,依次调用update方法去更新对应的组件。

update方法除了执行一些生命周期的方法外,最核心的一行代码是调用p方法,p方法我们已经在上文中介绍过很熟悉了。
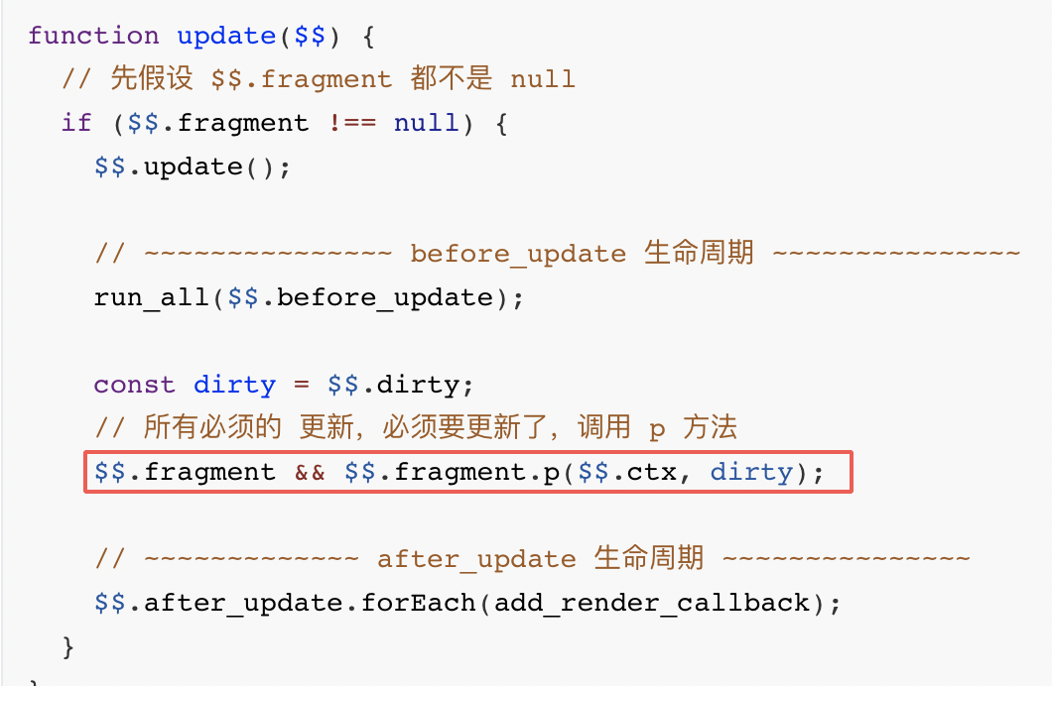
p 方法的本质就是走入到不同的if 判断里面,调用set_data原生的 javascript 方法更新对应的 DOM节点。

至此,我们的页面的DOM节点就已经更新好了。
上面的代码均是剔除了分支逻辑的伪代码。
Svelte 在处理子节点列表的时候,还是有优化的算法在的。比如说[a,b,c,d] 变成 [d, a, b, c] ,但是只是非常简单的优化,简单来说,是比较节点移动距离的绝对值,绝对值最小的节点被移动。
所以,严格意义上来说,Svelte 并不是100%无运行时,还是会引入额外的算法逻辑,只是量很少罢了。
总结
一个前端框架,不管是vue还是react更新了数据之后,需要考虑更新哪个dom节点,也就是,需要知道,脏数据和待更新的真实dom之间的映射。vue, react 是通过 virtualDom 来 diff 计算出更新哪些dom节点更划算,而sveltedom 是把数据和真实dom之间的映射关系,在编译的时候就通过AST等算出来,保存在p函数中。
Svelte 作为新兴的前端框架,采用了和 React, Vue 不同的设计思路,其独特的特性在某些场景下还是很值得尝试的。