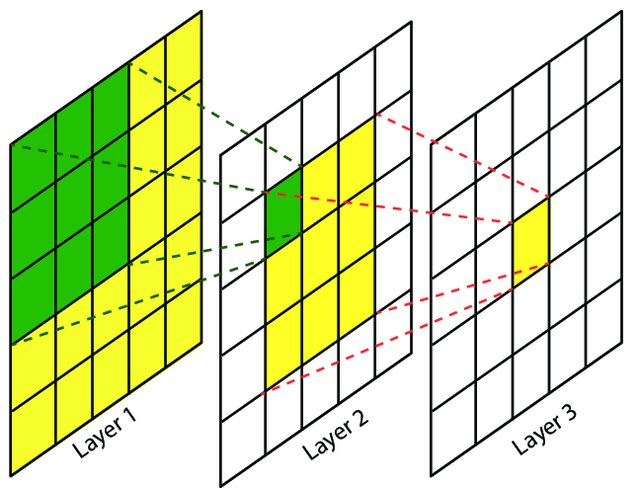
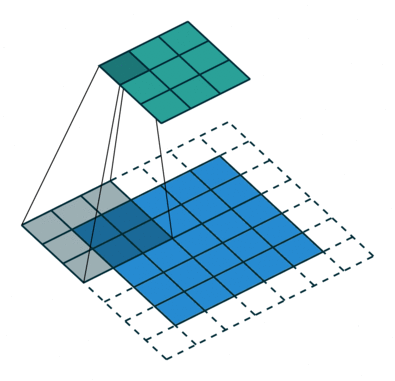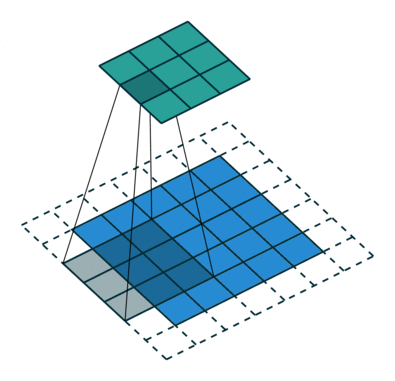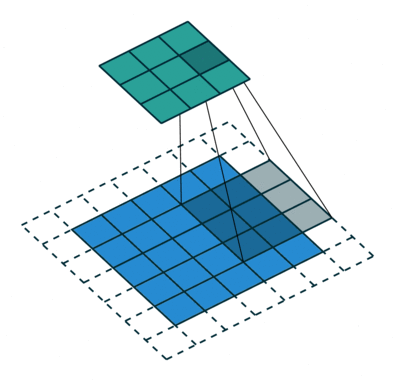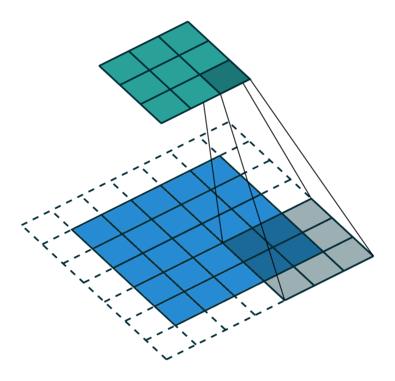
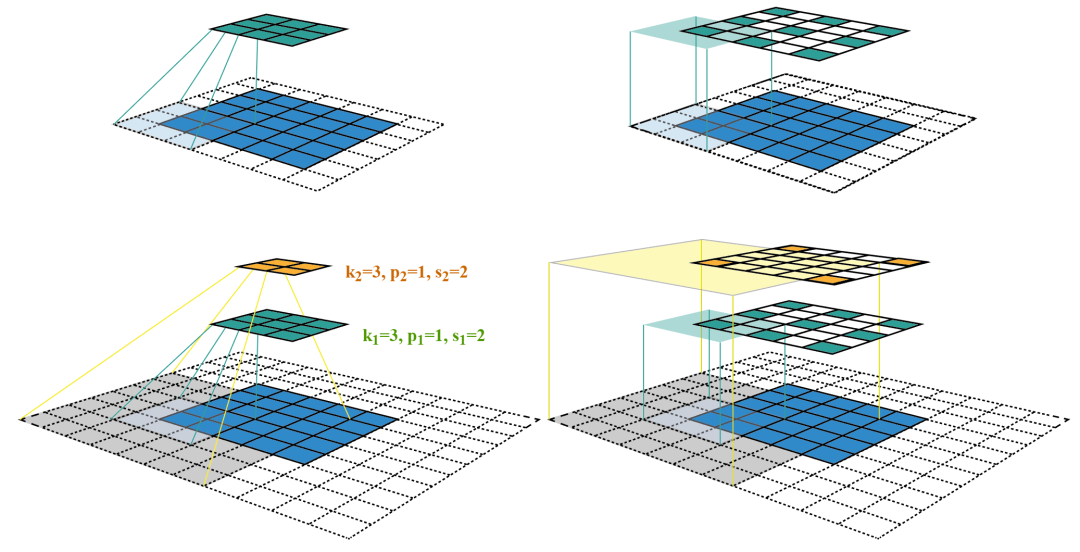
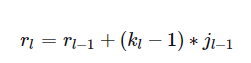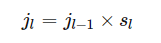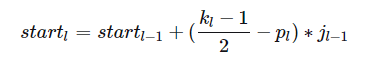The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by).—— A guide to receptive field arithmetic for Convolutional Neural Networks
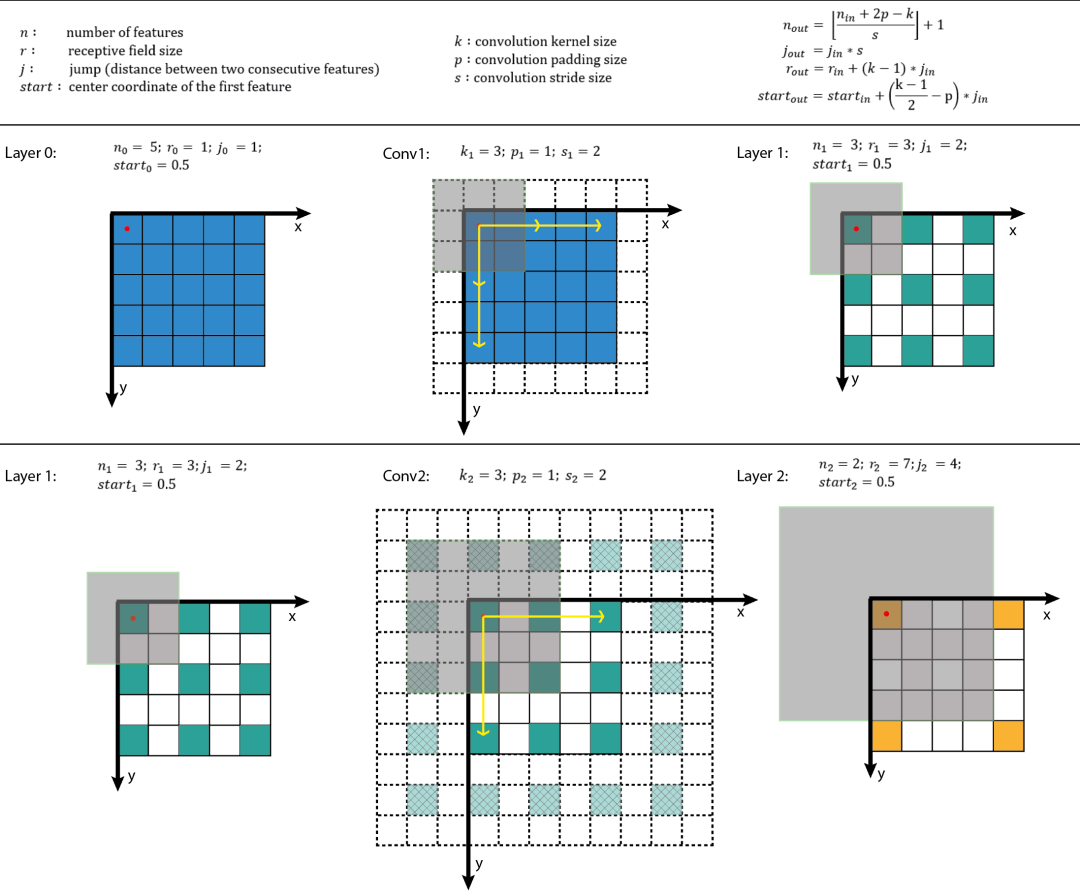
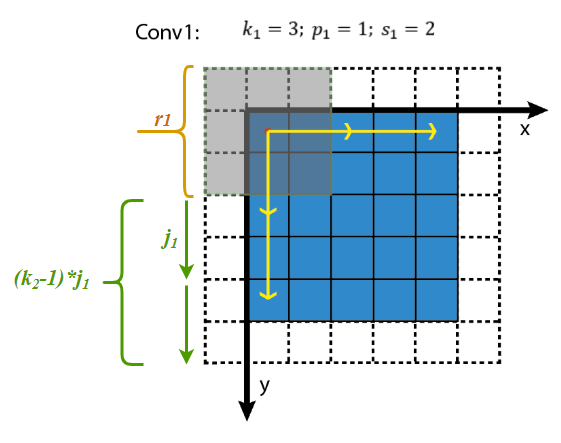
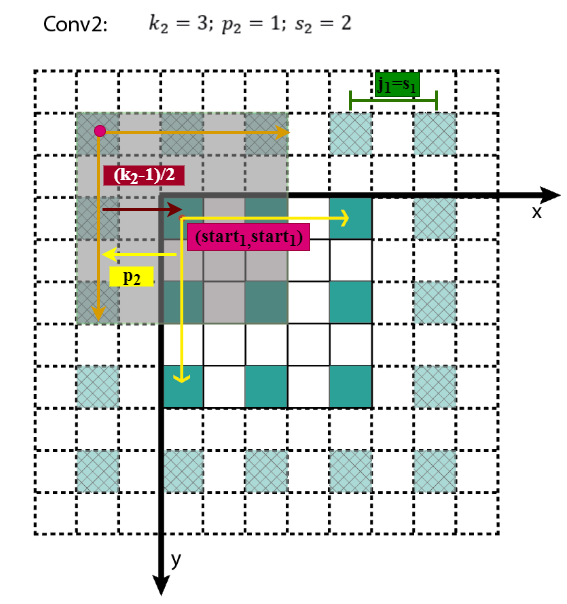
感受野中心的计算也是个递推公式。 在上一节中计算得,表示feature map Layerl上前进1个元素相当于在输入图像上前进的像素数目,如果将feature map上元素与感受野中心对齐,则jl为感受野中心之间的像素距离。如下图所示, receptive field center其中,各层的kernel size、padding、stride超参数已在图中标出,右侧图为feature map和感受野中心对齐后的结果。相邻Layer间,感受野中心的关系为:所有的start坐标均相对于输入图像坐标系。其中,start0=(0.5,0.5),为输入图像左上角像素的中心坐标,startl−1表示Layerl−1左上角元素的感受野中心坐标,(2kl−1−pl)为Layerl与Layerl−1感受野中心相对于Layerl−1坐标系的偏差,该偏差需折算到输入图像坐标系,其值需要乘上jl−1,即Layerl−1相邻元素间的像素距离,相乘的结果为(2kl−1−pl)∗jl−1,即感受野中心间的像素距离——相对输入图像坐标系。至此,相邻Layer间感受野中心坐标间的关系就不难得出了,这个过程可视化如下。 receptive field center calculation知道了Layerl左上角元素的感受野中心坐标(startl,startl),通过该层相邻元素间的像素距离jl可以推算其他元素的感受野中心坐标。
wiki-Receptive fieldwiki-Receptive Field CalculatorarXiv-Understanding the Effective Receptive Field in Deep Convolutional Neural Networksmedium-A guide to receptive field arithmetic for Convolutional Neural Networksmedium-Topic DL03: Receptive Field in CNN and the Math behind itppt-Convolutional Feature Maps: Elements of Efficient (and Accurate) CNN-based Object DetectionSIGAI-关于感受野的总结Calculating Receptive Field of CNN