
C++常见的三种内存破坏的场景和分析

比如某个变量整形,在程序中只可能初始化或者赋值为 1或者2, 但是在使用的时候却发现其为0或者其他的情况。对于其他类型,比如字符串等,可能出现了一种出乎意料的值!程序在堆上申请内存或者释放内存的时候,在内存充足的情况下,居然出现了堆错误。
1. 内存破坏之强制类型转换
#include#includeclass DemoClass{public:DemoClass() : m_bInit(true), m_tRecordTime(0){time((time_t *)(&m_tRecordTime));};void DoSomething(){if (m_bInit)std::cout << "Do Task!" << std::endl;}private:int m_tRecordTime;bool m_bInit;};int main(){DemoClass testObj;testObj.DoSomething();return 0;}
time_t time( time_t *destTime );,在VC6中time_t默认是32位,而在VS2017中默认是64位。早期程序以为32位中表达最大的时间是2038年,那时候完全够用,但随着计算机本身的发展64位逐渐成为主流time_t在最新的编译器中也默认采用64位,这样时间完全够用以亿年为单位了,那时候计算机发展超出我们想象了。程序的问题所在m_tRecordTime采用的是int类型,默认为32位,那么其地址作为time_t time( time_t *destTime );函数实参后,在VC6中time_t本身为32位自然也不会出错,但是在VS2017中因为time_t为64位,则time((time_t *)(&m_tRecordTime));后写入了一个64位的值。结合下图,看下这个对象的内存布局,m_bInit的值将会被覆盖,而这里原先的m_bInit的值为1,被覆盖为0,从而导致内存破坏,导致程序执行意想不到的结果。这里只是不输出,那在真实程序中,可能会导致某个逻辑错乱,发生严重的问题。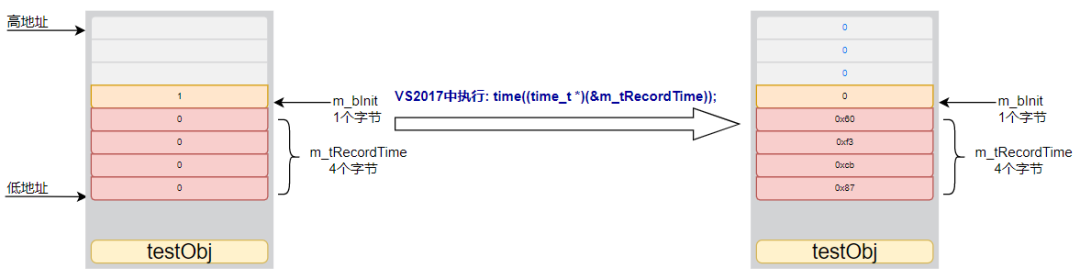
m_tRecordTime定义为time_t类型就可以了。在定义类型的时候,尽量和原始类型一致,比如这里的 time_t有些程序员可能惯性的认为就是32位,那就定义一个时间戳的时候就定义为int了,而我们要做的应该是和原始类型匹配(也就是函数的输入类型),将其定义为time_t,于此类似的还有size_t等,这样可以避免未来在数据集变化或者做平台迁移的时候造成不必要的麻烦。在有一些复杂的场景的下,也许你不得不做类型转换,而这个时候就格外的需要注意或者了解清楚,转换带来的情况和后果,保持警惕,否则就可能是一个潜在的 bug。这和开车一样,当你开车的时候如果看到前方车辆忽然产生一个不合常理的变道行为,首先要做的不是喷那辆车,而是集中注意力,看看是否更前方有障碍物或者事故放生,做出相应的反应。
2. 字符串拷贝溢出
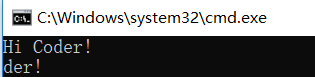
#include#define BUFER_SIZE_STR_1 5#define BUFER_SIZE_STR_2 8class DemoClass{public:void DoSomething(){strcpy(m_str1, "Hi Coder!");std::cout << m_str1 << std::endl;std::cout << m_str2 << std::endl;}private:char m_str1[BUFER_SIZE_STR_1] = { 0 };char m_str2[BUFER_SIZE_STR_2] = { 0 };};int main(){DemoClass testObj;testObj.DoSomething();return 0;}
errno_t strcpy_s(
char *dest,
rsize_t dest_size,
const char *src
);
3. 随机性的内存被修改
#include#define BUFER_SIZE_STR_1 5#define BUFER_SIZE_STR_2 8class DemoClass{public:void DoSomething(){strcpy_s(m_str2, BUFER_SIZE_STR_2, "Coder");strcpy_s(m_str1, BUFER_SIZE_STR_1, "Test");//Notice this line:m_str1[BUFER_SIZE_STR_2 - 1] = '\0';std::cout << m_str1 << std::endl;std::cout << m_str2 << std::endl;}private:char m_str1[BUFER_SIZE_STR_1] = { 0 };char m_str2[BUFER_SIZE_STR_2] = { 0 };};int main(){DemoClass testObj;testObj.DoSomething();return 0;}
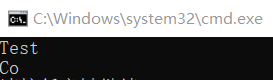
#include#define BUFER_SIZE_STR_1 5#define BUFER_SIZE_STR_2 8#define BUFFER_SIZE_UNUSED 100class DemoClass{public:void DoSomething(){strcpy_s(m_str2, BUFER_SIZE_STR_2, "Coder");strcpy_s(m_str1, BUFER_SIZE_STR_1, "Test");//Notice this line:m_str1[BUFER_SIZE_STR_2 - 1] = '\0';std::cout << m_str1 << std::endl;std::cout << m_str2 << std::endl;}private:char m_str1[BUFER_SIZE_STR_1] = { 0 };char m_strUnused[BUFFER_SIZE_UNUSED] = { 0 };char m_str2[BUFER_SIZE_STR_2] = { 0 };};int main(){DemoClass testObj;testObj.DoSomething();return 0;}
0:000> bp ObjectMemberBufferOverFllow!main*** WARNING: Unable to verify checksum for ObjectMemberBufferOverFllow.exe0:000> gBreakpoint 0 hiteax=010964c0 ebx=00e66000 ecx=00000000 edx=00000000 esi=75aae0b0 edi=0109b390eip=003a1700 esp=00defa00 ebp=00defa44 iopl=0 nv up ei pl nz na pe nccs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000206ObjectMemberBufferOverFllow!main:003a1700 55 push ebp
0:000> dv /t /v00def984 class DemoClass testObj = class DemoClass
0:000> ba w1 00def984+70:000> g
0:000> k# ChildEBP RetAddr00 00def97c 003a1720 ObjectMemberBufferOverFllow!DemoClass::DoSomething+0x41 [......\strcpybufferoverflow.cpp @ 16]01 00def9fc 003a1906 ObjectMemberBufferOverFllow!main+0x20 [......\strcpybufferoverflow.cpp @ 30]02 (Inline) -------- ObjectMemberBufferOverFllow!invoke_main+0x1c [d:\agent\_work\3\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 78]03 00defa44 75818494 ObjectMemberBufferOverFllow!__scrt_common_main_seh+0xfa [d:\agent\_work\3\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 288]04 00defa58 770a40e8 KERNEL32!BaseThreadInitThunk+0x2405 00defaa0 770a40b8 ntdll!__RtlUserThreadStart+0x2f06 00defab0 00000000 ntdll!_RtlUserThreadStart+0x1b
总结
评论