
你走阳光道,我走独木桥
哈哈哈哈哈哈哈,笑死我了,文章封面最左边的是鸡蛋。
大家好,我是3y
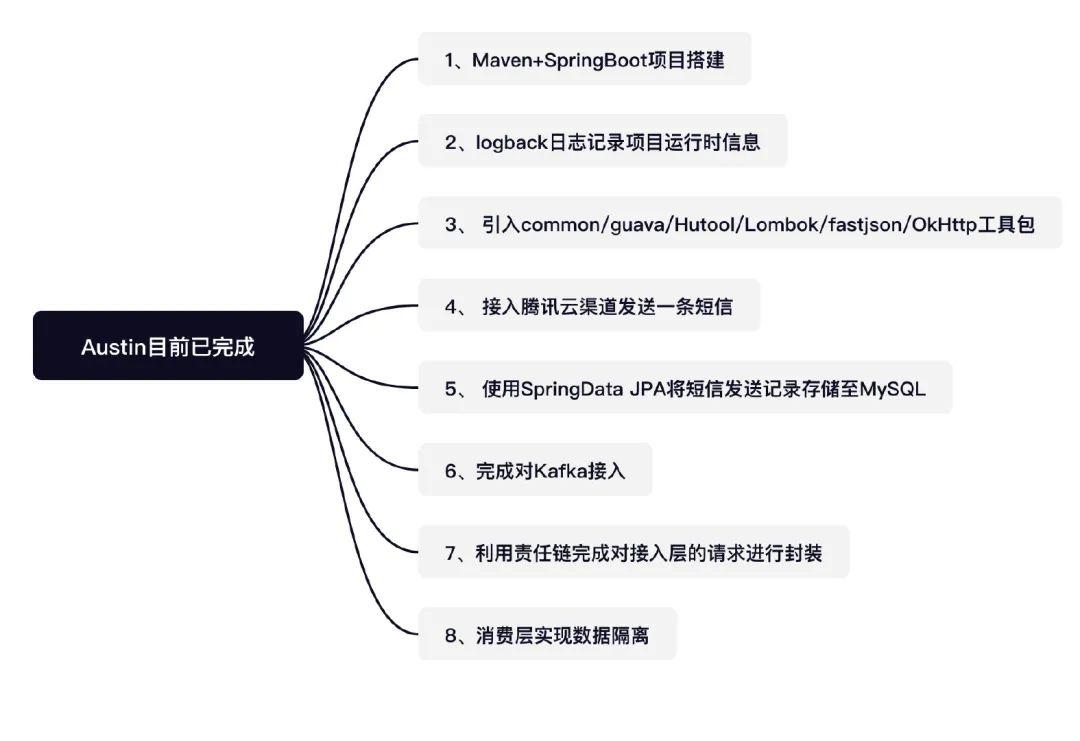
今天继续更新austin项目,如果还没看过该系列的同学可以点开我的历史文章回顾下,在看的过程中不要忘记了点赞哟!建议不要漏了或者跳着看,不然这篇就看不懂了,之前写过的知识点和业务我就不再赘述啦。
今天要实现的是handler模块的消费数据隔离。在聊这个之前,先看下之前的实现是怎么样的。

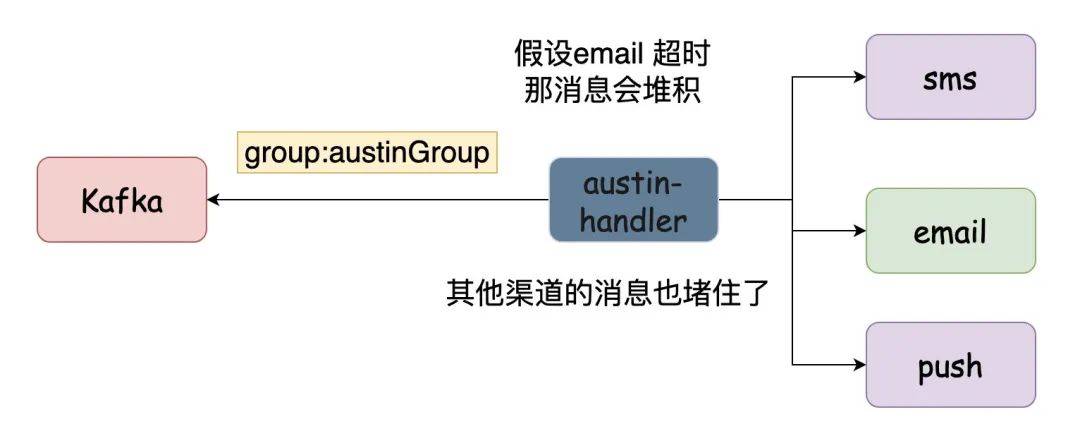
austin-api接收到了请求之后,将请求发往Kafka,topicName为austin。而在austin-handler起了一个groupName名为austinGroup监听austin这个topic的数据,进而实现消息发送。
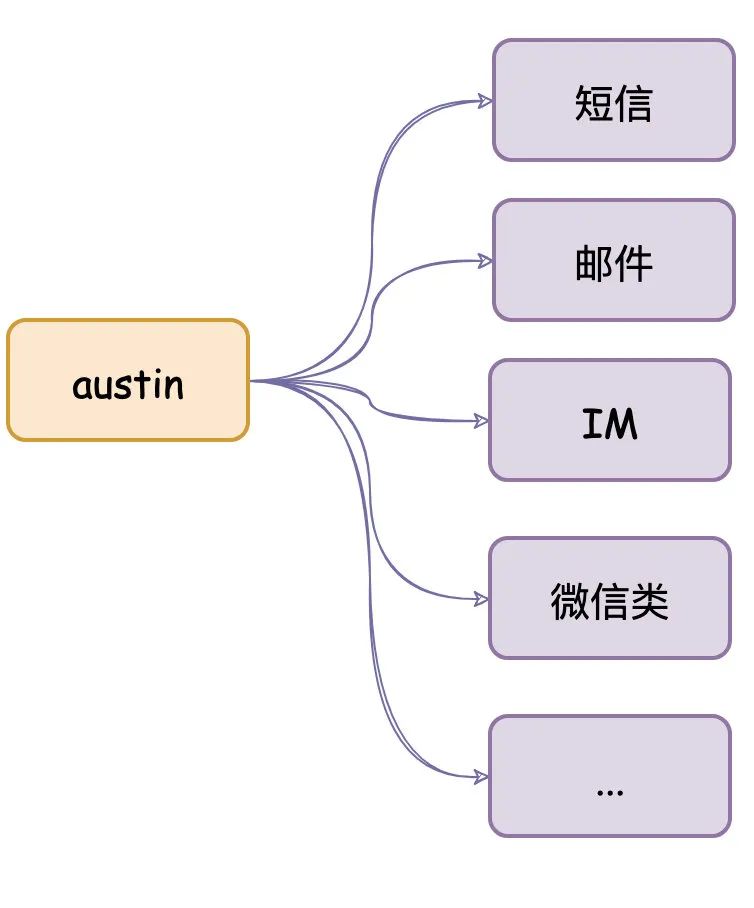
从系统架构来说,austin项目是可以发送多种类型消息的:短信、微信小程序、邮件等等等
那如果是单个topic单个group的话,有没有想过一个问题:如果某个发送渠道接口存在异常,超时了,此时会怎么样?
没错,消息都会堵住,因为它们消费同一个topic,用的是同一个消费者。
01、数据隔离
要破局?很简单。多topic多group就行啦。
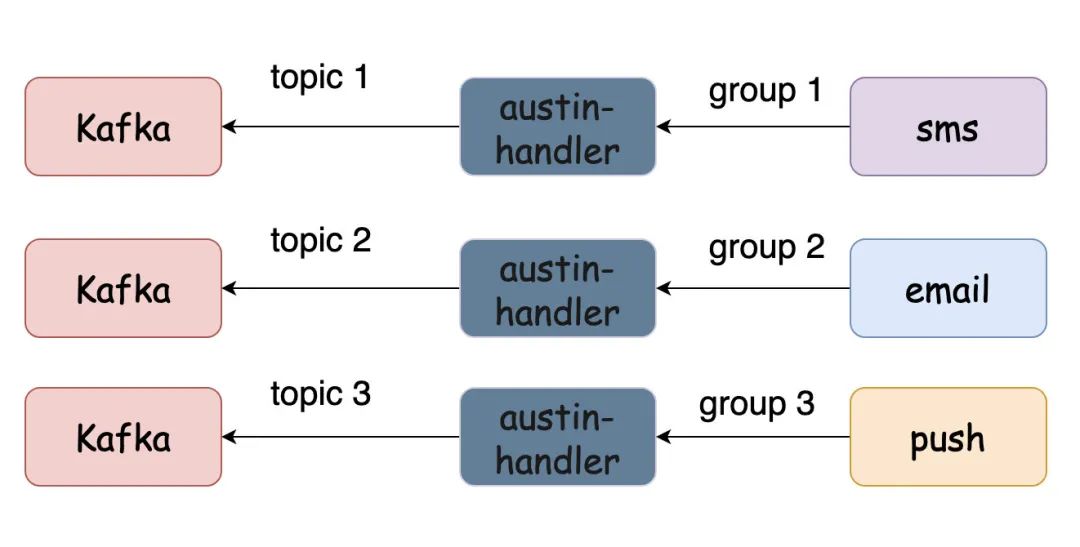
上面这种能解决所有问题吗?并不。即便是同一个渠道,但不同类型的消息发送特性是不一样的。比如我要发push营销消息,有可能在某个时刻就要推送4000W的人群。
那这4000W人在短时间内完全发送出去,不太现实。这很可能意味着会影响到通知类的push消息
还要破局?很简单。毕竟我们在设计消息模板的时候就已经考虑到这点了。消息模板有msgType字段来标识当前的模板属于哪种类型,那我们可以根据不同的消息类型再划分对应的group。
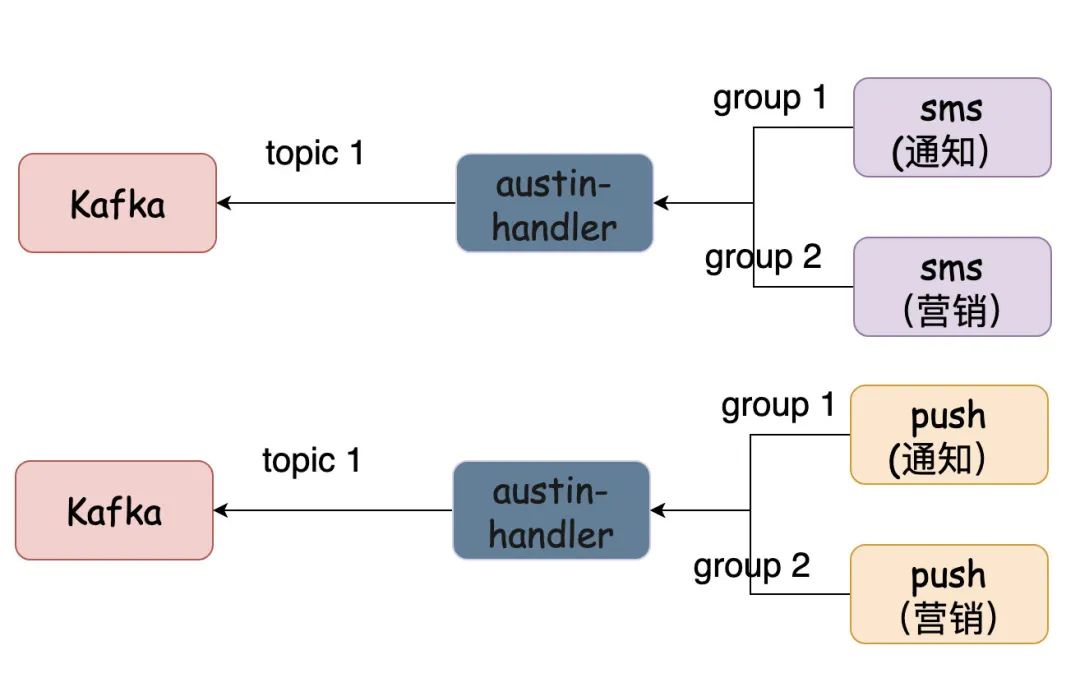
从理论上来说,我们可以为每种渠道的每种消息类型单独区分一个topic和group。因为topic间的数据是隔离的,不同的group间消费也是隔离的,那我们消费时肯定是数据隔离的。
不过,我目前的做法是:单topic多group。消费是隔离的,但生产的topic是共享的。我认为这样代码会更加清晰和易懂些,后期如果存在瓶颈了我们可以继续改。
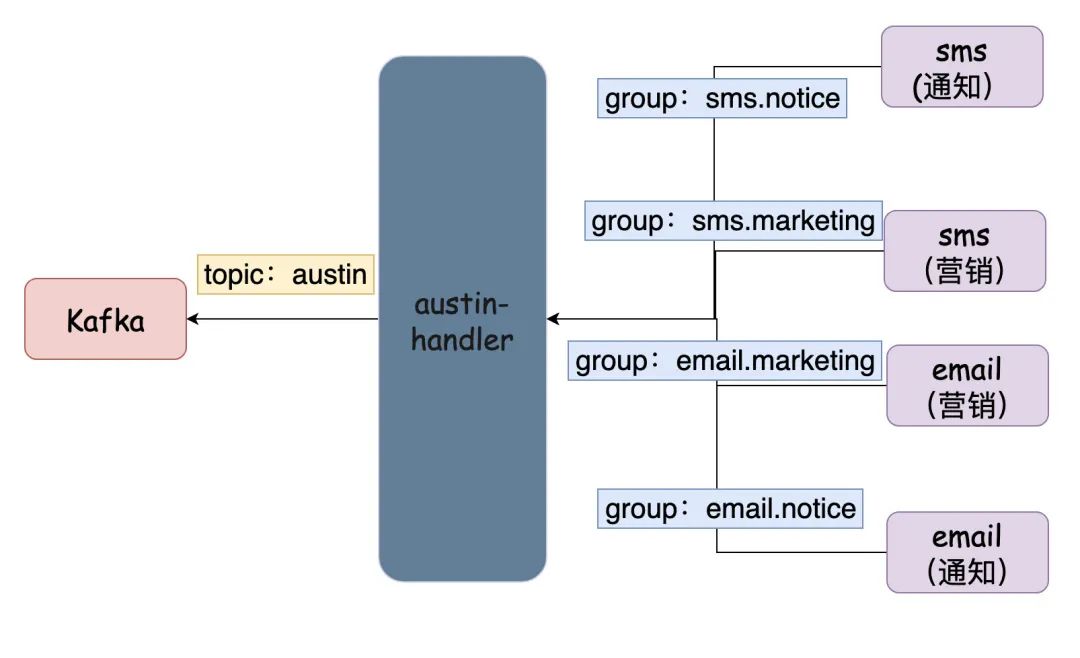
02、消费端设计
从上面已经定了通过单topic多group来实现数据隔离。比如,我目前定义了6个渠道(im/push/邮件/短信/小程序/微信服务号)和3种消息类型(通知/营销/验证码),那相当于起了18个消费者。
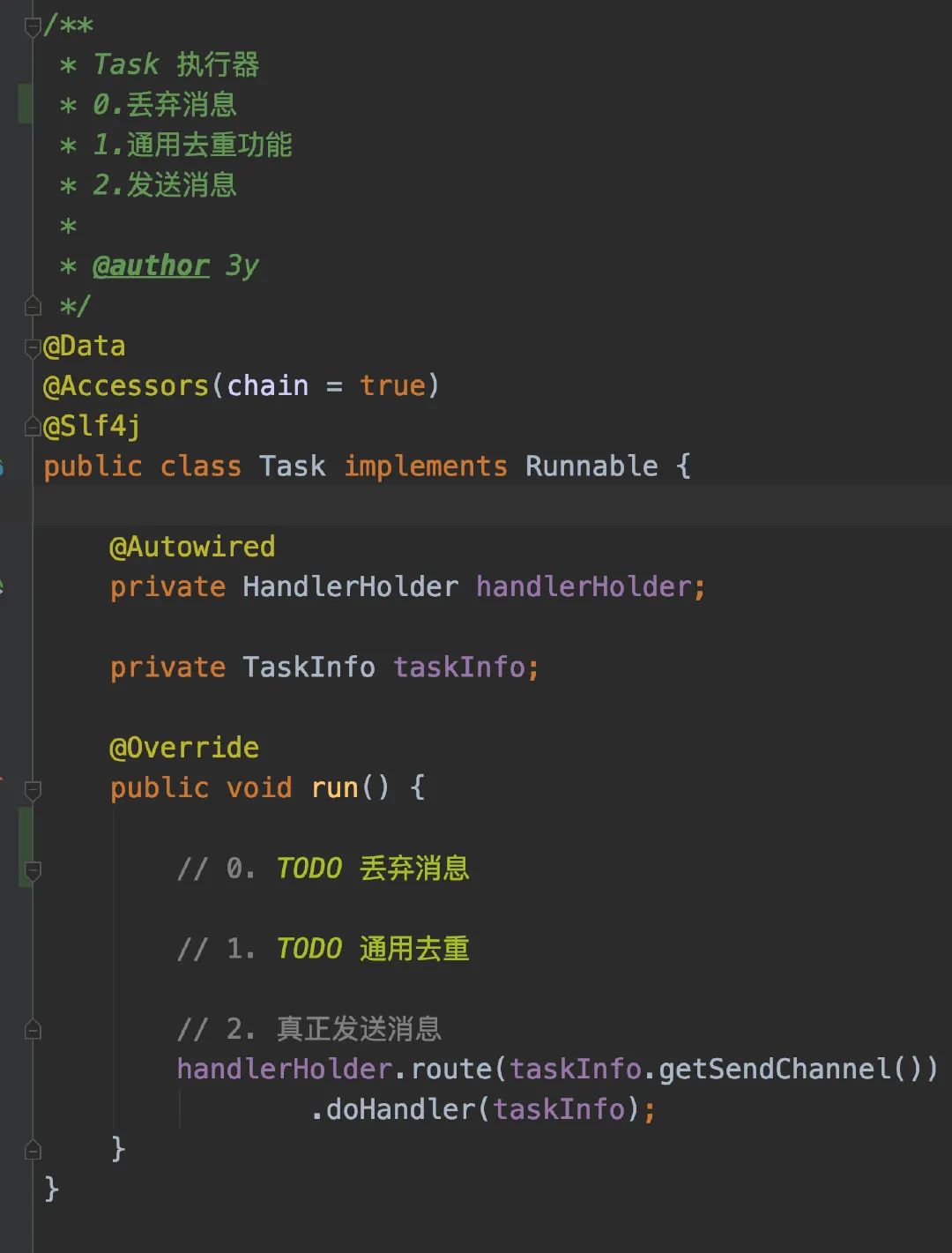
从kafka获取得到消息以后,我暂定规划是走几个步骤:消息丢弃->去重->真正发送
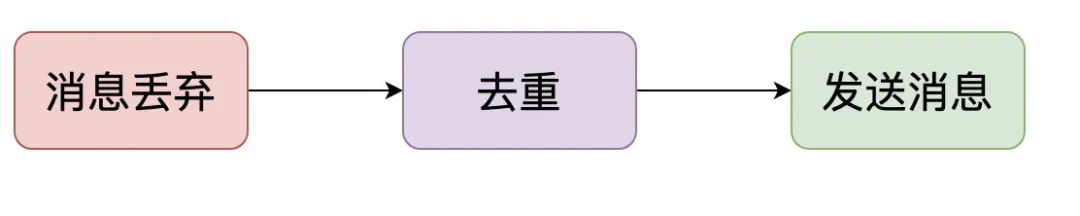
从本质上看去重和发送消息都是网络IO密集型。于是,为了提高吞吐量,我这边决定消费Kafka后存入缓存,做一层缓冲区。

做一层缓冲区可提高吞吐量,但同样会带来别的问题。如:当应用重启时,缓冲区的数据还没消费完,那是不是就会丢失?
这个我们可以后面再看看怎么把带来的问题给搞掂(持续关注,项目优化后面多着呢)。现在还是认为缓冲区的利大于弊,所以回到缓冲区上。
缓冲区给我的第一反应是实现生产者消费者模式

要实现这种模式,我初想了下挺简单的:消费Kafka的消息作为生产者,然后把数据扔进阻塞队列上,开多个线程去消费阻塞队列的数据就完事了。
后来又想了下,直接线程池不就完事了吗?线程池不就是生产者和消费者的实现吗。
于是乎,架构就变成了下图:
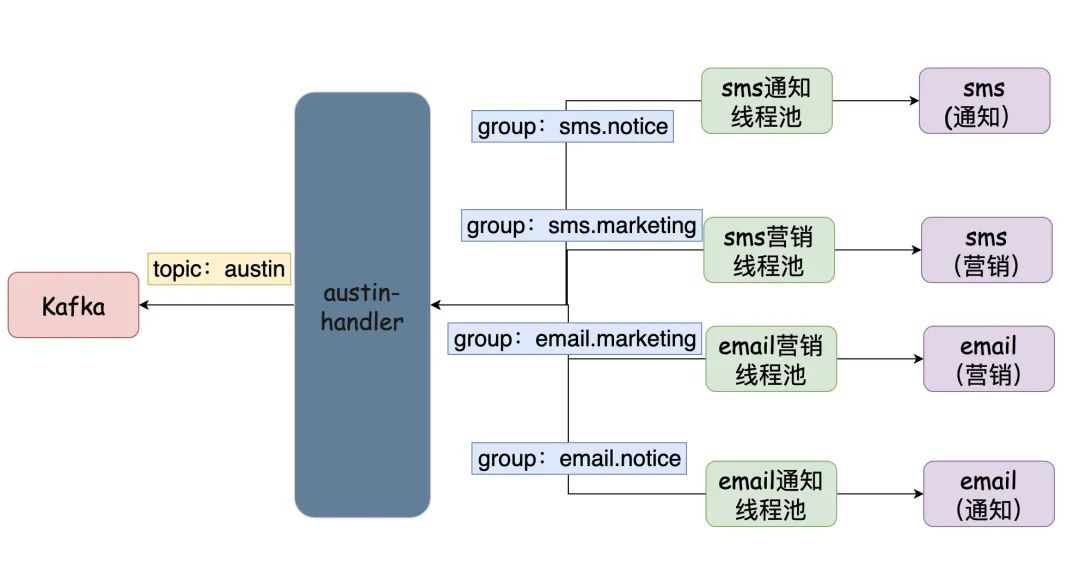
03、代码设计
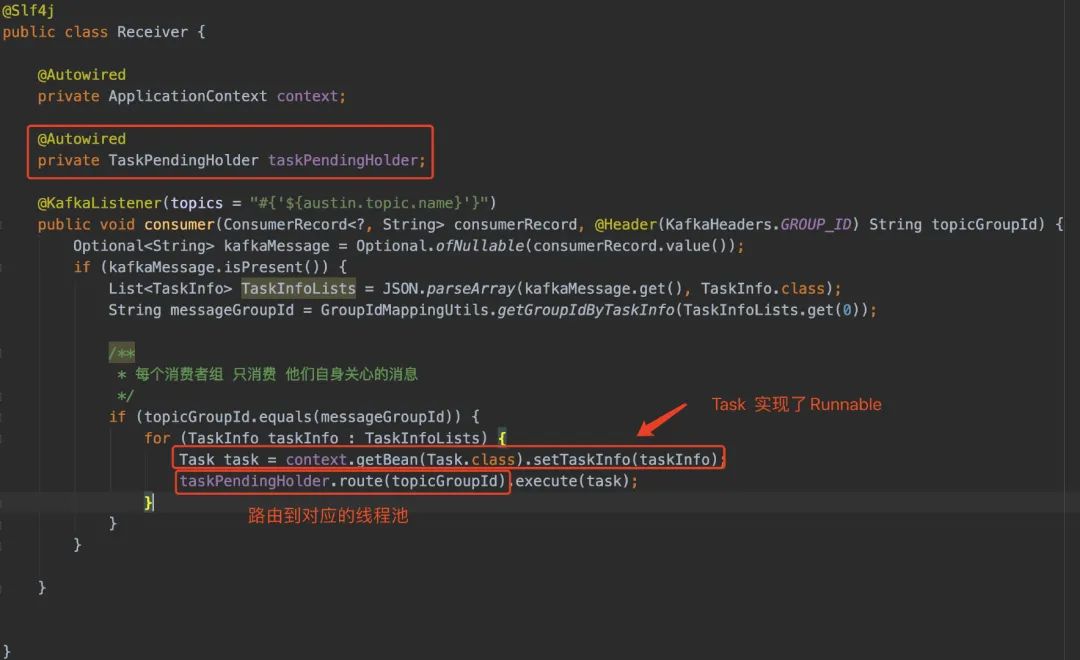
在消费端首先看Receiver的代码,该类看起来看简单,就只有一个@KafkaListener注解修饰方法,从Kafka消费出来随后交给pending做处理
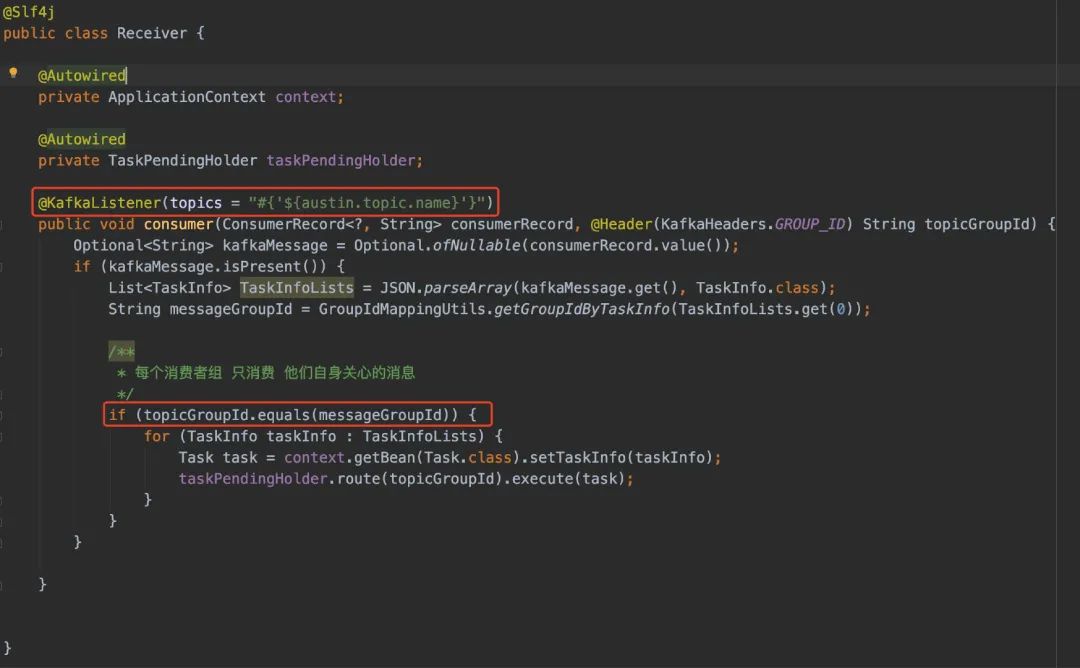
我用的是@KafkaListener注解从Kafka拉取消息,而没有用低级的Kafka api,原因无他:在项目前期无需做到完美,等有瓶颈的时候再想办法就好了。虽说如此,但我写的时候还是给我带来了不少的麻烦。
第一个问题:@KafkaListener是一个注解,从源码注释看它的传值只能够用Spring EL表达式和读取某个配置。但要知道的是,我的目的是想有多个group消费同一个topic。而我不可能说给每个group都定义一个消费的方法吧?(写这种破代码,我都睡不着觉)
翻了一个晚上技术博客我都没找到方案,甚至还发了个朋友圈吐槽下有没有人遇到过。第二天我仔细翻了下Spring的官方文档,终于给我找到了方案。
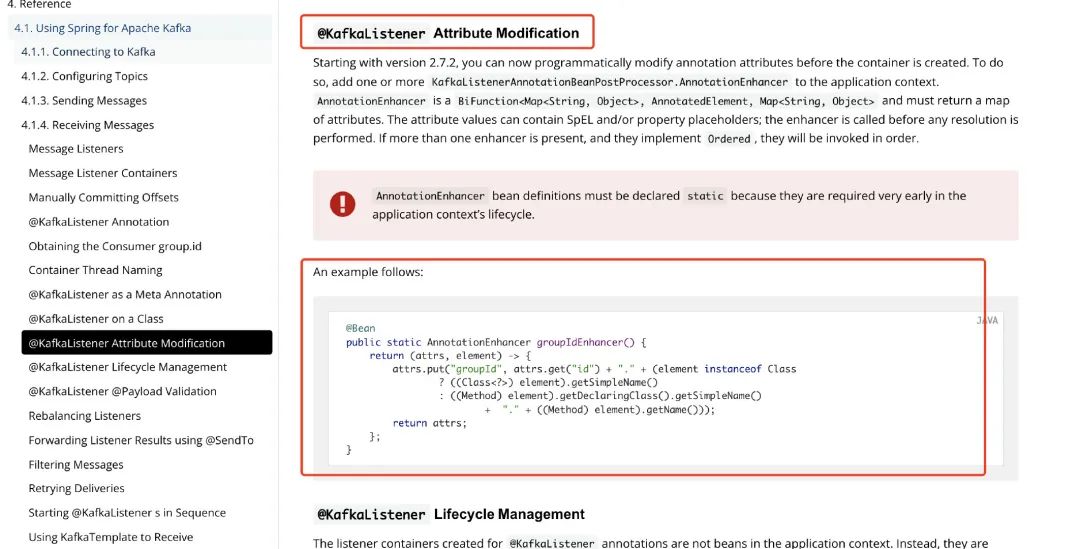
还是官方文档实在!
有了解决办法了以后,那事情就好办了。既然我是每种消息渠道的每种消息类型都要隔离,那我把这给枚举出来就完事啦!
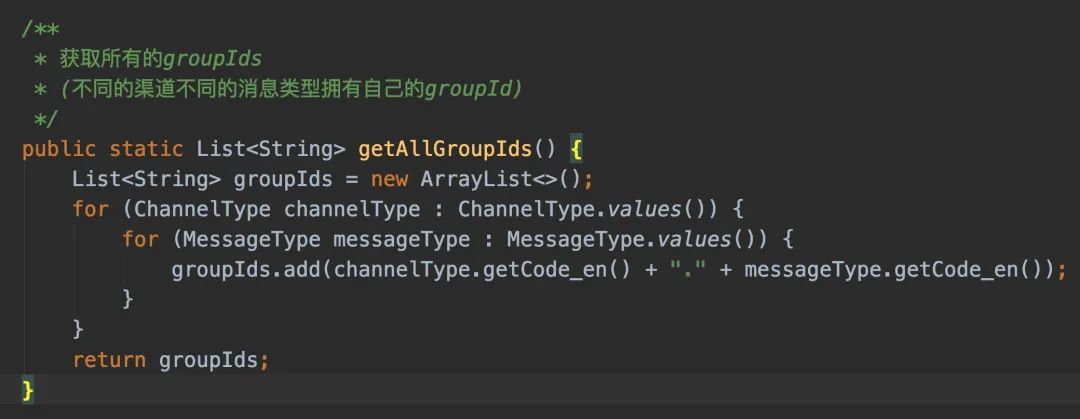
我的Receiver是多例的,那么只要我遍历这个List就好了(初始化消费者在ReceiverStart类上)。
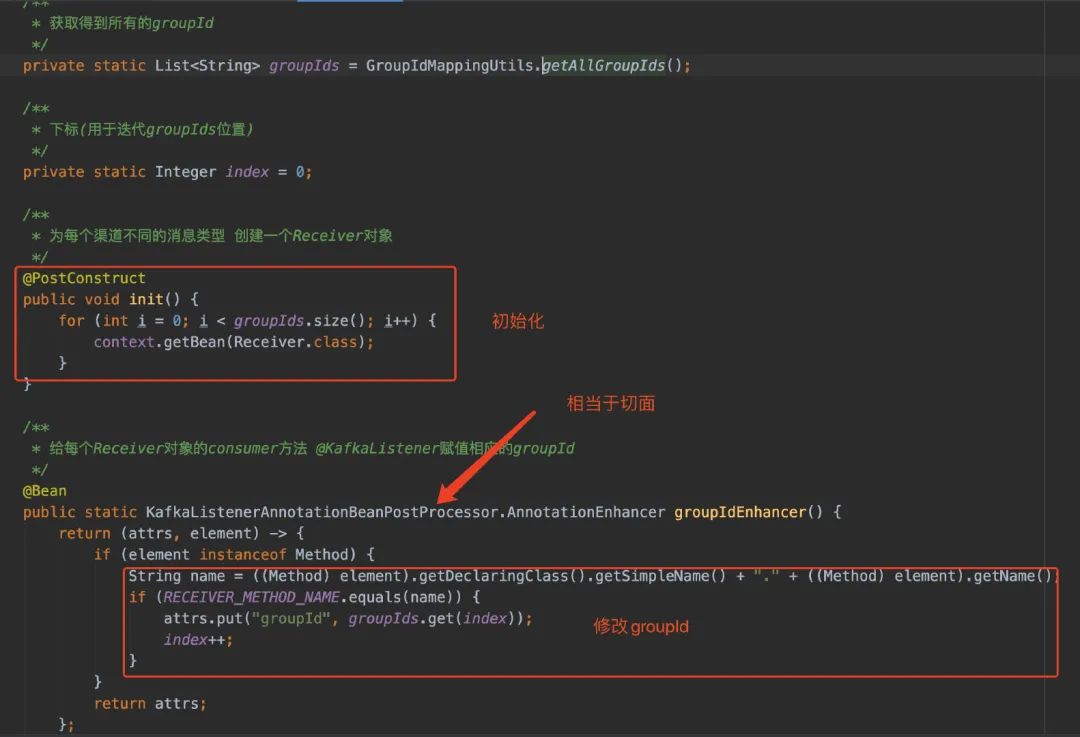
有了AnnotationEnhancer就解决了用@KafkaListener注解动态传入groupId的问题了。
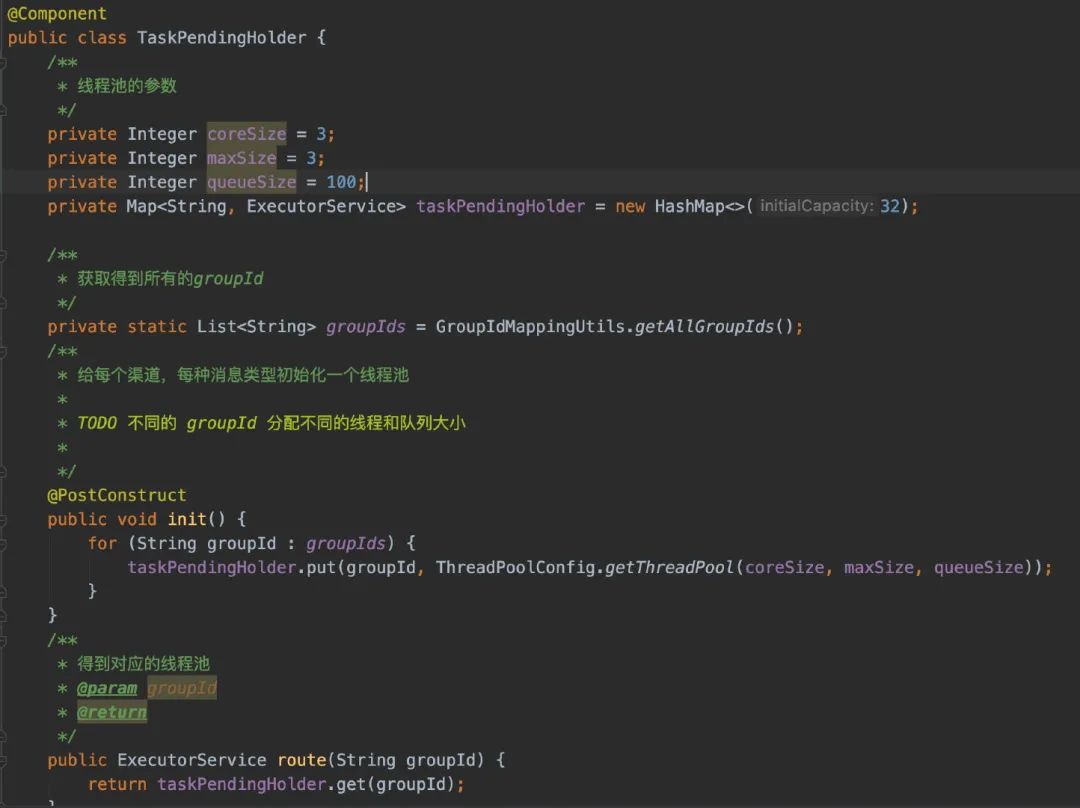
但我又遇到了第二个问题:Spring有@Async注解来优雅实现线程池的方法调用。我之前是没用过@Async注解的,但我看了下原理和使用姿势。我感觉这样挺优雅的(优雅永不过时)。但是用@Async是肯定要自己创建线程池,并且我要给每个消费者都创建自己独有的线程池。而我不可能说给每个group都定义一个创建线程池的方法吧?(写这种破代码,我都睡不着觉)
这次翻了官网和各种技术博客,都没能解决掉我的问题:在Spring环境下@Async注解上动态传入线程池实例,以及创建线程池实例时可支持根据条件传参。
最后只能放弃掉@Async注解了,以编程的方式去实现:
下面是TaskPendingHolder的实现(无非就是给每个消费者创建对应的线程池):
而Task实现目前就比较简单啦,直接调用对应的Handler进而下发消息就好:
04、总结
代码看似简单,业务看似容易理解,但是要知道的是即便是很多小公司的生产项目都没有这种设计。一把梭可真的是太常见了(功能又不是不能实现,代码又不是不能跑,最主要的:人也不是不能跑)
这篇文章主要讲述了一个思路:在消费MQ的时候,多group是可以实现数据隔离的,想要提高消费的吞吐量,可以再做一层缓冲区(前提是消费是IO密集型的)
Gitee链接:https://gitee.com/zhongfucheng/austin
GitHub链接:https://github.com/ZhongFuCheng3y/austin

《对线面试官》公众号还在持续分享面试题,没关注的同学可以关注一波!这是austin项目的上一个系列,质量杆杆的