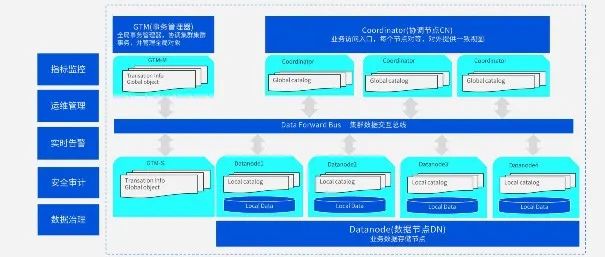
十问十答,带你全面了解TDSQL-A核心优势腾讯云数据库关注共 3018字,需浏览 7分钟 ·2021-08-17 14:23 在“国产数据库硬核技术沙龙-TDSQL-A技术揭秘”系列分享中,5位腾讯云技术大咖分别从整体技术架构、列式存储及相关执行优化、集群数据交互总线、分布式执行框架以及向量化执行引擎等多方面对TDSQL-A进行了深入解读。在本系列分享的最后一期,我们整理了关于TDSQL-A大家最关心的十个问题,腾讯云技术大咖们将对这些问题一一解答。TDSQL-A是腾讯首款分布式分析型数据库引擎,采用全并行无共享架构,具有自研列式存储引擎,支持行列混合存储,适应于海量OLAP关联分析查询场景。它能够支持2000台物理服务器以上的集群规模,存储容量能达到单数据库实例百P级。Q1: TDSQL-A目前有哪些用户在使用?TDSQL-A是伴随腾讯自身业务发展过程中衍生出来的产品,在腾讯内部有非常广泛的应用,像腾讯广告、QQ音乐核心业务都在使用TDSQL-A。Q2: TDSQL-A的主要优势是什么?TDSQL-A的主要优势在于,它是一个分布式的超大规模数据仓库集群,其应用场景主要面向超大规模数据集合的高速计算,在达到数千台服务器单个数据库集群超大规模的同时,还能做到高效的查询的执行。Q3: TDSQL-A在支持国产化硬件和操作系统方面做了哪些工作?近年来,随着国家芯创事业的推进,以及自主研发的硬件和软件的大规模应用,TDSQL-A也一直在做相关的适配工作。在国产化硬件方面,像鲲鹏、海光等主流国产化芯片,我们都做了很好的支持。在国产操作系统方面,我们也通过了一系列主流厂家的认证。Q4: TDSQL-A是否支持强同步复制?在PostgreSQL流程中,事务在提交前会记录WAL日志。对于行存表和列存表,我们都有对应的WAL日志去支持主备间的流式复制,用户还可以选择具体的复制级别或者是复制的同步配置。用户可以根据不同场景去选择是否需要高级别或者偏低级别的主备同步级别。另外,TDSQL-A也支持Hot Standby,即备平面可读。这些都可以通过TDSQL-A的管控平台来进行便捷的配置。Q5: TDSQL-A如何进行高效的分布式Join?这主要涉及到优化器、执行器、向量化等多个方面。我们以优化器为例。如果是带有CTE或者子查询比较多的复杂查询,TDSQL-A优化器会首先进行查询重写(rewrite),把CTE进行inline操作,随后尽量把子查询提升成Join来进行优化。这样做可以降低查询的执行复杂度,如果是特定查询甚至可能达到成百上千倍的提升。Rewrite之后,优化器还会自动对Join的顺序进行调整,相当于进行一个全面的遍历,然后去选择一个最优执行代价的计划。在分布式场景下,我们做了很多优化。比如Join关联的列是否是数据分布列,是否需要进行重分布,是否添加延迟物化算子,TDSQL-A会智能地根据cost来进行调整。另外,在物理算子选择时,根据不同的场景、选择率、代价评估,TDSQL-A会选择不同的关联算法,比如Nestloop join、HashJoin、MergeJoin。同时TDSQL-A还支持全流程的并行执行和向量化执行,以此来保证整体的高效的分布式Join计算能力。Q6: TDSQL-A目前支持哪些算子?其算子级别的并行能力又在哪些方面得到增强?我们基于PG 10对TDSQL-A做了很多自研和功能增强。因为PG 10本身在并行能力上存在欠缺,比如像Hash Join支持外表的并行,但像Build Hash Table就不支持并行。为了弥补欠缺,我们基于PG 10开发了完成的Hash Join的并行来同时支持Inner/Outer Plan的并行。另外就是聚合算子。因为很多分布式场景需要进行两阶段的聚合计算。这种两阶段聚合可能会在中间进行数据重分布,对于这种情况我们也需要支持完整的并行能力。TDSQL-A会根据聚合的列去做一个hash的计算,来选择在哪个work上计算,同时在不同的执行分片之间进行绑定,保证不同的分片执行时,它的不同并行进程之间可以收到正确的数据然后做并行计算。TDSQL-A还支持一些其它的算子,后面我们会不断去更新。Q7: TDSQL-A是否可以直接访问包括Oracle在内的外部数据源?Oracle以及Hive/Spark等大数据项目对接是比较广泛的应用场景。针对Oracle兼容和国产数据库替换,我们做了很多兼容性能力增强方面的工作。另外用户可以直接在TDSQL-A中用dblink来直接访问Oracle外部数据源,去做数据变更或者做查询。像Hive或者其他的第三方数据源,PG有Foreign Data Wrapper这样的接口。用户可以使用我们支持的插件或者适配丰富的第三方插件来访问异构外部数据源。如果需要把数据拉到TDSQL-A来,我们可以用TDSQL-A配套的数据导入工具TDX去进行数据导入。实际上我们会有比较丰富的协议,可以通过不同的外部数据源,把数据流导到TDX上面。数据库会并行地从TDX往DN节点进行数据抽取,这样可以访问外部数据源,也可以享受数据加载的便捷服务。Q8: TDSQL-A能否快速把数据导入到数据库系统里?是否能与其他系统进行数据交互?TDSQL-A支持在PG数据源上进行copy,可以将数据copy in、copy from,同时还支持外表定义,我们可以去创建外部表,直接把外部的数据文件在数据库里进行定义,从而进行一些操作。同时,我们还支持DB bridge——云上的数据同步工具,它可以实时同步其他系统的数据进来,然后再通过Kafka同步出去。此外,我们还开发了一个专门的数据导入导出工具TDX,它可以借助多DN并行高效地进行数据导入导出。Q9: TDSQL-A目前最多能支持多少个节点的部署?在TDSQL-A中,部署节点数量是一个配置参数,在一开始初装时就可以进行配置,默认值为2048,具体可以根据用户需要进行调整。Q10: 大规模部署时,FN如何保证通信更高效?我们先来假设在没有FN的情况下,由于系统集群规模比较大,集群内又在不停地创建连接,这样就会导致整个系统网络的socket数量成为瓶颈。这也是我们引入FN数据交互总线的初衷,用来有效减少连接数量。通过FN节点,具体计算进程不需要直接进行全链接,而是通过FN节点进行数据路由,极大的减少了socket连接数。FN如何保证高效性,这个问题可以从两方面来回答。一方面,在同一个服务器内部,FN通过共享内存直接获取数据,实际上省了网络这一层,因此它的通信是比较高效的。另一方面,在不同服务器之间,FN主要负责数据的发送,其内部是一个多线程的模型,可以存在很多个发送线程。FN内部还有一个Merge线程,它的作用是在一个数据发送之前,会检查哪个发送线程的队列比较空闲,然后把这个数据调度到这个空闲的发送线程中,从而达到复杂均能的效果。﹀﹀﹀-- 更多精彩 --TDSQL-A自研列存储及优化原理大揭秘海量数据,极速体验——TDSQL-A核心架构详解来了揭秘TDSQL-A:兼容Oracle的同时支持海量数据交互点击阅读原文,了解更多优惠福利! 浏览 72点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 统计学知识闯关之十问十答机器学习算法与Python实战0Serverless 云服务的十问十答近期,我们在与多家项目外包开发团队的沟通交流中,发现有几个问题经常被问到,比如:类似知晓云这样的 Serverless 云服务适用于什么场景?已有后端团队还需要用 Serverless 吗?爱范儿的项目也用知晓云吗,能应对百...直击灵魂!统计学知识十问十答,你都会吗?机器学习算法与Python实战0Linux文件系统十问苦逼的码农0“低代码”十问喔家ArchiSelf0Linux文件系统十问源码共读0西藏珠峰十问IT局1新华社:十问中国经济卫星与网络0用户密码加密存储十问十答,一文说透密码安全存储公众号程序猿DD0用户密码加密存储十问十答,一文说透密码安全存储程序IT圈0点赞 评论 收藏 分享 手机扫一扫分享分享 举报


 下载APP
下载APP