
手把手教你用Pandas分析全国城市房价

导读:Pandas灵活好用,能够完成复杂的、重复的、批量的数据处理。本文教你利用Pandas爬取房价,以及分析全国城市的房价。

01 利用爬虫获取房价
Pandas在配合做网络数据采集爬虫时,也能发挥其优势,可承担数据调用、数据存储的工作。将数据存入DataFrame后,可直接进入下一步分析。本例以获取某房产网站中房价为目标,来体验一下Pandas的便捷之处。
首先利用requests(需要安装)库获取单个小区的平均价格:
import requests # 安装:pip install requests
# 创建一个Session
s = requests.Session()
# 访问小区页面
xq = s.get('https://bj.lianjia.com/xiaoqu/1111027382589/')
# 查看页面源码
xq.text
# 找到价格位置附近的源码为:
# <span class="xiaoquUnitPrice">95137</span>
# 切分与解析
xq.text.split('xiaoquUnitPrice">')[1].split('</span>')[0]
# '93754'最终得到这个小区的平均房价。这里使用了将目标信息两边的信息进行切片、形成列表再读取的方法。也可以用第三方库Beautiful Soup 4来解析。Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,它能够通过解析源码来方便地获取指定信息。
我们构建获取小区名称和平均房价的函数:
# 获取小区名称的函数
def pa_name(x):
xq = s.get(f'https://bj.lianjia.com/xiaoqu/{x}/')
name = xq.text.split('detailTitle">')[1].split('</h1>')[0]
return name
# 获取平均房价的函数
def pa_price(x):
xq = s.get(f'https://bj.lianjia.com/xiaoqu/{x}/')
price = xq.text.split('xiaoquUnitPrice">')[1].split('</span>')[0]
return price接下来利用Pandas执行爬虫获取信息:
# 小区列表
xqs = [1111027377595, 1111027382589,
1111027378611, 1111027374569,
1111027378069, 1111027374228,
116964627385853]
# 构造数据
df = pd.DataFrame(xqs, columns=['小区'])
# 爬取小区名
df['小区名'] = df.小区.apply(lambda x: pa_name(x))
# 爬取房价
df['房价'] = df.小区.apply(lambda x: pa_price(x))
# 查看结果
df
'''
小区 小区名 房价
0 1111027377595 瞰都国际 73361
1 1111027382589 棕榈泉国际公寓 93754
2 1111027378611 南十里居 56459
3 1111027374569 观湖国际 88661
4 1111027378069 丽水嘉园 76827
5 1111027374228 泛海国际碧海园 97061
6 116964627385853 东山condo 145965
'''可以先用Python的类改造函数,再用链式方法调用:
# 爬虫类
class PaChong(object):
def __init__(self, x):
self.s = requests.session()
self.xq = self.s.get(f'https://bj.lianjia.com/xiaoqu/{x}/')
self.name = self.xq.text.split('detailTitle">')[1].split('</h1>')[0]
self.price = self.xq.text.split('xiaoquUnitPrice">')[1].split('</span>')[0]
# 爬取数据
(
df
.assign(小区名=df.小区.apply(lambda x: PaChong(x).name))
.assign(房价=df.小区.apply(lambda x: PaChong(x).price))
)以上网站可能会改版,代码不适用时需要调整爬虫代码。
02 全国城市房价分析
中国主要城市的房价可以从以下网址获取:
https://www.creprice.cn/rank/index.html
该网页中会显示上一个月的房价排行情况,先复制前20个城市的数据,然后使用pd.read_clipboard()读取。我们来分析一下该月的数据(下例中用的是2020年10月数据)。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (8.0, 5.0) # 固定显示大小
plt.rcParams['font.family'] = ['sans-serif'] # 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 显示负号
dfr = pd.read_clipboard()
# 取源数据
dfr.head()
'''
序号 城市名称 平均单价(元/㎡) 环比 同比
0 1 深圳 78,722 +2.61% +20.44%
1 2 北京 63,554 -0.82% -1.2%
2 3 上海 58,831 +0.4% +9.7%
3 4 厦门 48,169 -0.61% +9.52%
4 5 广州 38,351 -1.64% +13.79%
'''查看数据类型:
dfr.dtypes
'''
序号 int64
城市名称 object
平均单价(元/㎡) object
环比 object
同比 object
dtype: object
'''数据都是object类型,需要对数据进行提取和类型转换:
df = (
# 去掉千分位符并转为整型
dfr.assign(平均单价=dfr['平均单价(元/㎡)'].str.replace(',','').astype(int))
.assign(同比=dfr.同比.str[:-1].astype(float)) # 去百分号并转为浮点型
.assign(环比=dfr.环比.str[:-1].astype(float)) # 去百分号并转为浮点型
.loc[:,['城市名称','平均单价','同比','环比']] # 重命名列
)
df.head()
'''
城市名称 平均单价 同比 环比
0 深圳 78722 20.44 2.61
1 北京 63554 -1.20 -0.82
2 上海 58831 9.70 0.40
3 厦门 48169 9.52 -0.61
4 广州 38351 13.79 -1.64
'''接下来就可以对整理好的数据进行分析了。首先看一下各城市的均价差异,数据顺序无须再调整,代码执行效果如图1所示。
(
df.set_index('城市名称')
.平均单价
.plot
.bar()
)
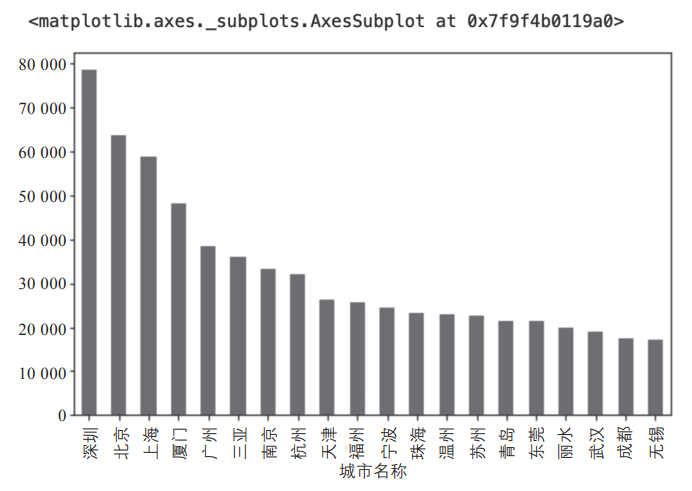
▲图1 各城市平均房价
各城市平均房价同比与环比情况如图2所示。
(
df.set_index('城市名称')
.loc[:, '同比':'环比']
.plot
.bar()
)
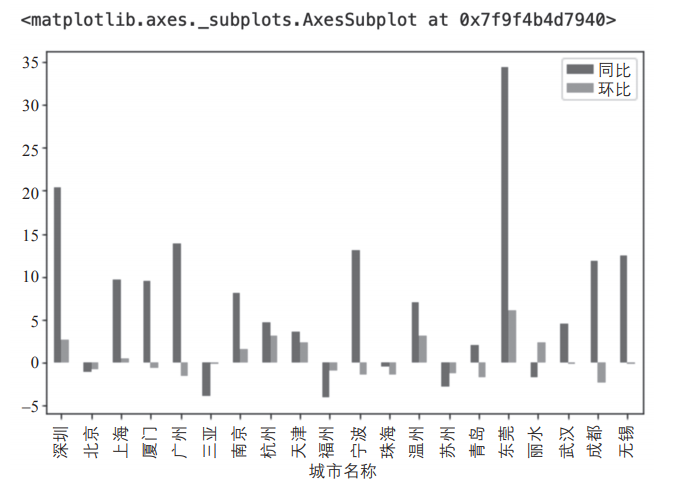
▲图2 各城市平均房价同比和环比
将同比与环比的极值用样式标注,可见东莞异常突出,房价同比、环比均大幅上升,如图3所示。
(
df.style
.highlight_max(color='red', subset=['同比', '环比'])
.highlight_min(subset=['同比', '环比'])
.format({'平均单价':"{:,.0f}"})
.format({'同比':"{:2}%", '环比':"{:2}%"})
)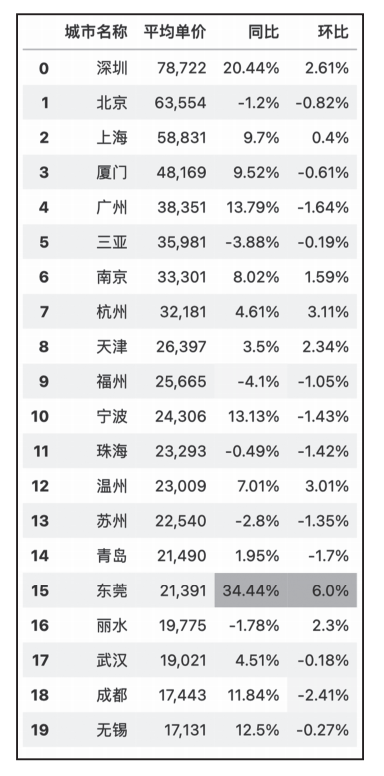
▲图3 各城市平均房价变化样式图
绘制各城市平均单价条形图,如图4所示。
# 条形图
(
df.style
.bar(subset=['平均单价'], color='yellow')
)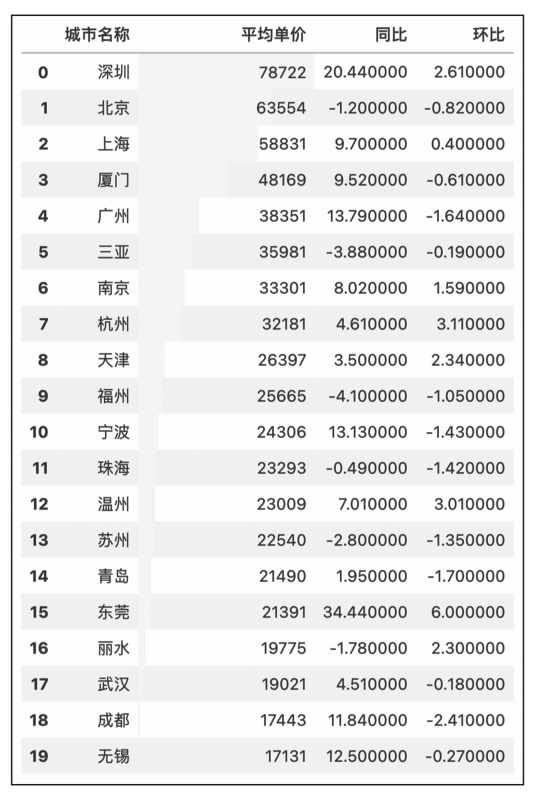
▲图4 各城市平均单价样式图
将数据样式进行综合可视化:将平均单价背景色设为渐变,并指定色系BuGn;同比、环比条形图使用不同色系,且以0为中点,体现正负;为比值加百分号。最终效果如图5所示。
(
df.style
.background_gradient(subset=['平均单价'], cmap='BuGn')
.format({'同比':"{:2}%", '环比':"{:2}%"})
.bar(subset=['同比'],
color=['#ffe4e4','#bbf9ce'], # 上涨、下降的颜色
vmin=0, vmax=15, # 范围定为以0为基准的上下15
align='zero'
)
.bar(subset=['环比'],
color=['red','green'], # 上涨、下降的颜色
vmin=0, vmax=11, # 范围定为以0为基准的上下11
align='zero'
)
)

▲图5 各城市平均房价综合样式图
关于作者:李庆辉,数据产品专家,某电商公司数据产品团队负责人,擅长通过数据治理、数据分析、数据化运营提升公司的数据应用水平。
本文摘编自《深入浅出Pandas:利用Python进行数据处理与分析》,经出版方授权发布。

推荐语:这是一本全面覆盖了Pandas使用者的普遍需求和痛点的著作,基于实用、易学的原则,从功能、使用、原理等多个维度对Pandas做了全方位的详细讲解,既是初学者系统学习Pandas难得的入门书,又是有经验的Python工程师案头必不可少的查询手册。