
Kyuubi 原理 | Apache Kyuubi 高可用的云原生实现
本文作者为中国移动云能力中心大数据团队软件开发工程师洪冬冬,文章主要介绍了 Apache Kyuubi 基于 Apache ZooKeeper 实现高可用的原理,以及在云原生场景下,利用现有的组件和技术实现云原生的负载均衡和客户端高并发。
背景
Apache Kyuubi 是一个分布式的、多租户网关,用于在 Lakehouse 上提供 Serverless SQL。Kyuubi 最初是基于 Apache Spark 构建的兼容 HiveServer2 协议的大规模数据处理和分析工具,目前已经支持 Flink/Trino/Hive/Doris 等引擎。Kyuubi 致力于成为一个开箱即用的数据仓库和数据湖工具,让任何人都可以轻松高效地使用各种计算引擎,在了解 SQL 的基础上可以像处理普通数据一样处理大数据。在 Kyuubi 架构中,有三个主要的特性:
1.多租户,Kyuubi 通过统一的身份验证授权层为资源获取和数据 / 元数据访问提供端到端的多租户支持。2.高可用,Kyuubi 通过 ZooKeeper 提供负载均衡,它提供了企业级的高可用性,以及无限的客户端高并发。3.多个工作负载,Kyuubi 可以通过一个平台、一个数据副本和一个 SQL 接口轻松支持多个不同的工作负载。
在云原生场景中,额外部署和维护 ZooKeeper 代价很高,我们是否有云原生的方案可以替代?
基于 ZooKeeper 的高可用实现
Kyuubi-ha 模块下的 DiscoveryClient 接口中包含了服务注册和发现所需要实现的所有的接口(基于 master 分支),大致包含:客户端的创建和关闭、节点的创建和删除、节点是否存在、注册和注销服务、获取分布式锁、获取引擎地址等。下图简要展示了租户连接到 Kyuubi 的过程中与 discovery 交互的步骤。

当我们启动 Kyuubi server 或者拉起 engine 时,ServiceDiscovery 会在 ZooKeeper 中注册相关信息,租户获取到可用 server 列表后,根据策略选择 server 开启 session,在开启 session 的过程中,Kyuubi server 会根据用户连接时制定的引擎共享策略在 ZooKeeper 中查找是否有可用的 engine,如果没有则拉起一个新的 engine 并连接。
在整个过程中,主要是用了 ZooKeeper 的两个核心功能:服务注册和分布式锁。
服务注册
ZooKeeper 提供 4 种创建节点的方式:
1.PERSISTENT(持久化)即使客户端与 ZooKeeper 断开连接,该节点依然存在,只要不手动删除该节点,将永远存在;2.PERSISTENT_SEQUENTIAL(持久化顺序编号目录节点)在持久化目录节点基础上,ZooKeeper 给该节点名称进行顺序编号;3.EPHEMERAL(临时目录节点)客户端与 ZooKeeper 断开连接后,该节点就会被删除;4.EPHEMERAL_SEQUENTIAL(临时顺序编号目录节点)在临时目录节点基础上 ZooKeeper 给该节点名称进行顺序编号
Kyuubi 中 server 和 engine 的服务注册基于 EPHEMERAL_SEQUENTIAL 实现,在服务启动时创建临时节点,退出时断开链接,ZooKeeper 自动删除对应节点。同时,服务启动时会创建 watcher 监听注册的临时节点,当该节点被删除时,会优雅的停止服务。
分布式锁
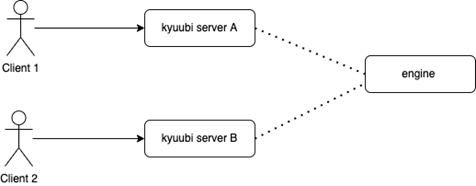
如上图,当两个客户端同时请求同一个引擎时,如果引擎不存在,在不加锁状态下,我们会启动两个 engine,后续再有新连接时,总会连接到后注册的引擎,先注册的引擎会长时间空闲。因此,在创建新的引擎时,通过对对应节点添加分布式锁,先获取到锁的客户端创建引擎,后获取锁的客户端直接使用已启动的引擎。
基于 ETCD 的高可用云原生实现
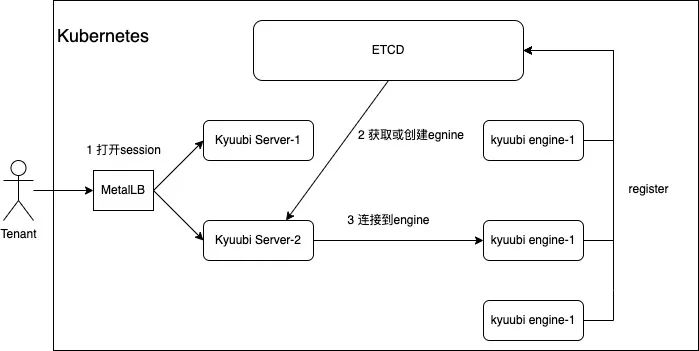
上图是云原生场景下,租户连接 Kyuubi 的过程,其中涉及到云原生应用中比较关键的组件,ETCD 和 MetalLB。其中,ETCD 负责引擎服务注册和发现,MetalLB 则为 Kyuubi server 提供负载均衡能力。
ETCD 既然支持引擎的注册和发现,为什么不像 ZooKeeper 一样同时支持 Server 的高可用呢?
这个我们主要从客户使用方面考量,我们通常使用的 beeline、jdbc 驱动都支持基于 ZooKeeper 的服务发现,但并不支持 ETCD。如果将 server 注册到 ETCD 中,我们没有办法兼容现有的客户端,需要为租户提供额外的驱动。同时,我们也知道在云原生场景中 MetalLB 可以通过单个 IP 为下面的 pod(deployment)提供负载均衡。经过考量最终我们选择 ETCD+MetalLB 的方式。
关于 ETCD
ETCD 是用于共享配置和服务发现的分布式,一致性的 KV 存储系统,是 CoreOS 公司发起的一个开源项目,授权协议为 Apache。ETCD 有很多使用场景,包括:配置管理、服务注册与发现、leader 选举、应用调度、分布式队列、分布式锁等。其中,比较多的应用场景是服务发现,服务发现 (Service Discovery) 要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。ETCD 是 Kubernetes 的首要数据存储,也是容器编排的实际标准系统。使用 ETCD,云原生应用可以保持更为一致的运行时间,而且在个别服务器发生故障时也能正常工作。应用从 ETCD 读取数据并写入到其中;通过分散配置数据,为节点配置提供冗余和弹性。
ETCD 与 ZooKeeper 的简单对比如下:
| ETCD | ZooKeeper | |
| 一致性协议 | Raft | ZAB |
| API | HTTP+JSON, gRPC | 客户端 |
| 安全控制 | HTTPS | Kerberos |
| 运维 | 简单 | 困难 |
关于 MetalLB
Kubernetes 默认没有提供负载均衡器的实现,MetalLB 通过 MetalLB hooks 为 Kubernetes 中提供网络负载均衡器的实现。简单的说,它允许在私有的 Kubernetes 中创建 LoadBalancer 类型的 services。MetalLB 有两大功能:
1.地址分配:在平台中申请 LB,会自动分配一个 IP,因此,MetalLB 也需要管理 IP 地址的分配工作2.IP 外部声明:当 MetalLB 获取外部地址后,需要对外声明该 IP 在 Kubernetes 中使用,并可以正常通信。
实现细节
当 Kyuubi 底层引擎启动时,会在 ETCD 中创建对应的 Key。租户使用是,直接连接 MetalLB 提供的地址,由底层 LoadBalancer 负责负载均衡,连接到对应 Kyuubi server 后,server 会在 ETCD 中查找是否有可用的引擎,没有则创建。其中主要涉及以下三点内容:
1.使用 Kubernetes 中原生组件 MetalLB+Deployment 方式实现实现 Kyuubi server 的高可用2.ETCD 中模拟 EPHEMERAL_SEQUENTIAL 节点。在 ETCD 中没有临时 Key 的概念,无法在服务停止是自动删除对应 Key 信息。但是在客户端中提供了 KeepAlive 功能:为特定的 Key 附加一个过期时间,并且在客户端未被关闭或超时的情况下,自动刷新这个过期时间。同时,引擎在注册时,获取对应节点的分布式锁,计算编号,以实现节点编号的自增长。3.分布式锁,ETCD 的分布式锁在使用方面和 ZooKeeper 基本一致,但在锁持有时间方面稍有区别,ETCD 中锁有租约时间,到时间后如果没有主动释放锁,则会自动释放,而 ZooKeeper 不主动释放则不会释放。
总结
首先,我们先简单对比下云原生架构和现有架构:
| Server+ZooKeeper | Kurbernetes+ETCD | |
| 包管理 | 无 | Helm3 |
| Server 高可用 | ZooKeeper | LoadBalancer |
| Engine 注册 | ZooKeeper | ETCD |
| 部署维护成本 | 高 | 低 |
引入云原生架构的 Kyuubi 在部署和运维方面极大的节约了成本,并且基于 deployment 我们可以实现 Kyuubi server 的动态扩容,基于 comfigmap 实现 server 的统一配置管理。目前,ETCD 的服务注册和发现逻辑我们主要参考 ZooKeeper 的实现,后续工作会进一步优化调用逻辑。
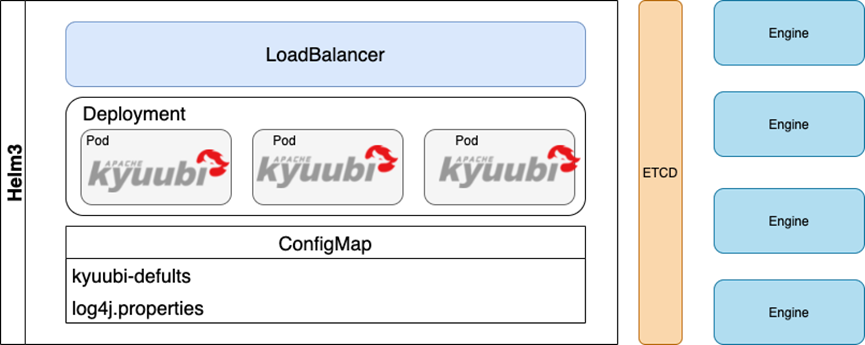
最后,我们目前 Kyuubi 的整体架构图如下,供大家参考。
关于本周文章如果大家有疑问,或者有其他感兴趣的大数据内容,欢迎大家在评论区留言,后续会持续分享大数据领域的干货知识。