
分析了 40000+ 条内衣数据,我终于发现了罩杯的秘密...
大家好,我是宝器
这篇内容是想教大家如何优雅地爬取天猫评论相关数据,以及怎么样去做些不一样的有趣的分析,奈何一直没想好合适的主题。
该用什么样的主题,才能把粉丝吸引进来呢?正想着,旁边同事的目光被从工位走过的一位妹子所吸引,我顺着看去...

灵光一闪,便有了主题——咱们这次就老老实实分析下内衣的数据吧!
数据爬取
很久前写过用selenium和requests爬取评论的教程,但时间久远,后台有不少小伙伴反馈已经被ban了,在网上其他地方也没找到合适的代码。所以,今天小z特来更新一波。
天猫评论反爬几经更迭,从最开始的什么都不用伪装,到后面要加上cookies才能访问,再到现在的headers构造,一定一定一定要加referer参数才能返回想要的数据结果。
具体怎么爬取呢?非常简单,只需3步:
第一步,定位目标网址
打开具体商品链接,点击累计评价页面,同时F12呼出开发调试工具:
评论翻页,动态加载找到评论数据所在的网址:
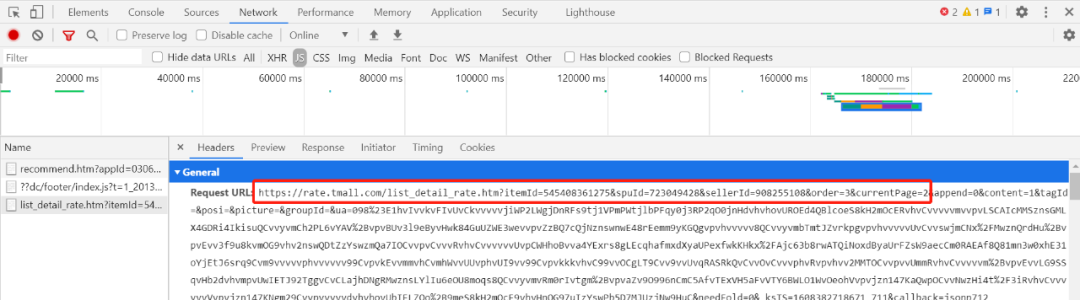
别被这巨长的一段网址唬住,真正有用的网址小z已经用红框标出来了,通过修改currentPage参数,轻松实现评论翻页。
第二步,实现单页爬取,为循环全量爬取打好基础
要顺利获取评论数据,需要构造好headers和cookies,经过反复测试,headers中的User-Agent,referer,还有cookies,3个核心参数缺一不可,根据自己的实际情况来构造即可:

评论数据中,我们感兴趣的主要是4个字段:评论内容,评论时间,SKU(款式尺码)和用户昵称。

数据本身是json格式的,所以解析起来非常容易:

最后,批量构造网址,实现循环爬取。
温馨提示:文明人,文明爬,控制好访问间隔时间

Easy~
接下来,我们参考销量排名,分别爬取了9款内衣产品共44832条评论数据,来一探内衣究竟。
注:上面已经把爬取的核心逻辑和代码做了展示,完整代码和本次爬取的评论数据已经整理好,放在文末。为节省篇幅,本次故意略去清洗数据,感兴趣的同学可自行尝试。
数据分析
我们已经成功爬到了此次分析的全部数据:

款式,买家昵称(加密过的),评论内容,评价日期全都健在。
按常规套路来说,做评价分析有三板斧:
先按时间维度来统计评价发布规律,再调用官方情感API做个简单情感分析,最后来一波词云图,美滋滋收工~

我本来也打算这样分析,但这种做法像是分析了很多,又好像没分析什么,对于内衣数据,未免太暴殄天物。
本次评论分析,小z不打算分析文本本身,毕竟大家关注的,貌似都是size数据啊!
有两个关于size的观点,困扰了我很久,今天就来逐一验证一波。
1、人人都是C-CUP?
之前逛某乎,看到过一篇不太正经的科普,讲的是经济发展,提升了人民的生活水平。
人民生活水平提升了,各种营养补充就更充分了,人们关注的身体特征也得到了充分的发展,像身高啊,胸围啊等等。里面印象比较深的一个观点,是作者认为目前c-cup已经是主流了。
凭借多年对生活细致入微的观察,我对这个观点表示严重怀疑。
Talk is cheap,几行Python,便统计出了罩杯分布:

数据不吹牛,C罩杯远远还没成为主流!
从数据上看,B罩杯44.61%的占比,体现了数量上毫无疑问的优势,C罩杯排名第二,占比24.41%,随后是A罩杯的18.50%,最后是不到十位数占比的D、E、F。
说实话,我是看了型号统计数据,才知道还有F...

注:百分比为各自罩杯下的占比,柱高表示数量的多少
对三大罩杯型号做进一步分析,可以看到,罩杯往大了走,下围也往大了走。同时,我们也能发现,不同消费者对于“松紧程度”也有不同的偏好,像C罩杯竟然还有2%选择70下围的。
2、消费力越强,罩杯越大?
我曾经还听过一个沙雕论证:
多吃木瓜会变大
木瓜不便宜,所以经常吃木瓜的人(更rich)也会买更高档的内衣
由此可得,买越高档内衣的人,平均罩杯也就越大
眼尖的同学看数据源的时候已经发现了,我在爬取数据的时候特意通过价格对内衣做了区分。爬取的44832条评价,来源于9款产品。其中3款价格低于100元,定义为平价款;3款中端型内衣价格介于100-200元,200元以上则是高端款。
一波可视化,数据会说话

不用做严谨的什么相关分析我们就能看出:
内衣平价,但不平庸。平价内衣呈现出一种类钟型分布,以B罩杯为主,A和C在两侧均匀分布,值得注意的是,D和E罩杯合计占比也接近7%。
中端内衣,波涛汹涌。C罩杯诚不欺我,已然成为主力,D及以上的罩杯,占比竟然超过了30%。
高端内衣,并不高耸。A和B占去了83%的份额,竟然没有C以上的...
瞎BB:难道平价型内衣以学生为主,还处在进一步发育阶段。而买高端内衣的人,大多追求的是“高级”感、性冷淡风。
以上,是关于如何爬取评论数据,并基于评论附带的款式数据,做一些另类角度的沙雕趣味分析,重在抛砖引玉,感兴趣的同学还可进一步深挖。
拿到数据,把目光仅仅局限在现有数据维度,硬怼分析逻辑,是很多刚入行同学的误区。
在接下来不定期的趣味分析内容中,我会尝试解构如何预设分析方向,如何拆解分析方向,如何让数据源服务于分析本身这些命题,希望对大家有所帮助。
最后,完整爬取代码已经打包好,获取地址如下
下载链接:
https://pan.baidu.com/s/1faLPDuw794qee1qZRf0oZg
提取码:1qdc

推荐阅读
欢迎长按扫码关注「数据管道」