作者 | 陈大鑫
作者 | 陈大鑫
每件事物的出现都有它各自的使命,我们提到数据集就绕不过ImageNet,ImageNet数据集及其它推动的大规模视觉比赛对人工智能特别是计算机视觉领域的巨大贡献是毋庸置疑的。
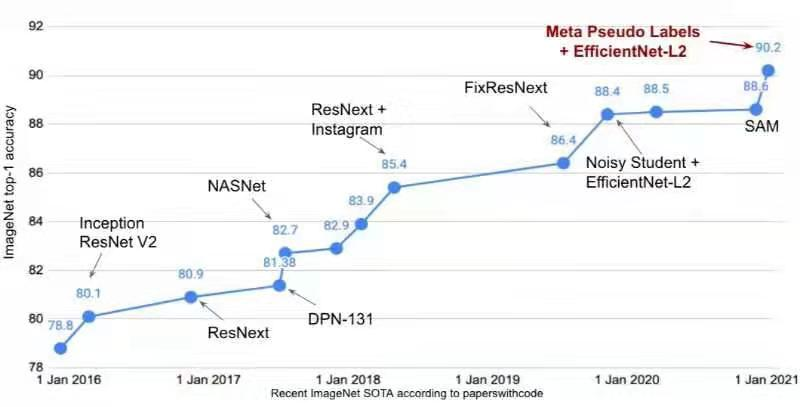
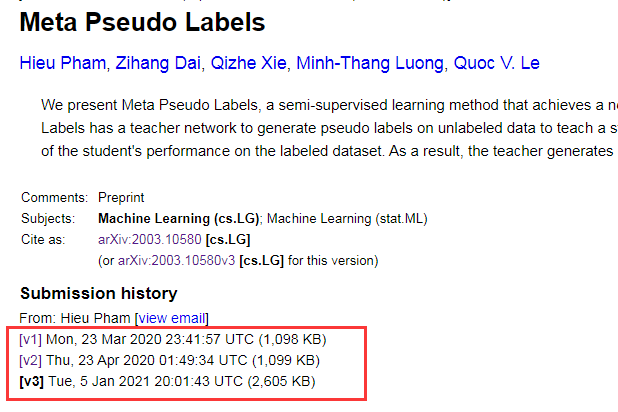
一晃十载,ImageNet竞赛和刷榜的历史见证了很多知名神经网络模型的诞生,如AlexNet在2012年横空出世,并在ImageNet竞赛取得冠军,而之后伴随ImageNet竞赛又出现了如Inception、ResNet、ResNeXt等网络模型。在当年,这些模型真是一时风头无量。虽然如李飞飞所言,ImageNet已经完成了它的历史使命(早早超出了人类的识别率),ImageNet竞赛也已经于几年前就早已不再举办,但是家里有矿的谷歌仍然默默地在ImageNet数据集上进行刷榜。近日,谷歌大脑团队首席科学家科学家Quoc Le 发推表示,他们提出了一种新的半监督学习方法,通过使用半监督学习方法Meta Pseudo Labels训练EfficientNet-L2,可以将ImageNet 上的 top-1准确率提升到90.2%,这一结果与之前的 SOTA 相比实现了1.6% 的性能提升。下图则是ImageNet Top-1准确率近五年的详细提升路线图。这篇有关元伪标签的论文《Meta Pseudo Labels》如下所示:论文链接:https://arxiv.org/abs/2003.10580其实这篇论文最早提交于 2020 年 3 月,只不过于最近又放出了最新的一个版本。可以看到这篇论文前两个版本的识别准确率是86.9%,由此可以间接看出谷歌在这一年期间为之作为目标并持续进行了模型改进(或许称为魔改+调参+trick? )。谷歌的这篇论文是把ImageNet上top-1识别准确率作为一个亮点,其实这篇论文同样在ImageNet上top-5识别率上也刷到了第一:98.8%。只不过top-5识别准确率相对比较简单,谷歌是不会把这当作卖点的。(注:top-5识别准确率指的是在测试图片的N个分类概率中,取前面5个最大的分类概率,这五个当中只要有一个预测正确即可,而top-1则最难,只取第一个预测输出结果,对就是对,错就是错。)那这篇论文究竟讲了什么呢?以下援引知乎@小小将的回答(已经过作者授权):【终于终于,ImageNet的Top-1可以上90%了。其实谷歌刷新的还是自己的记录,因为目前ImageNet上的SOTA还是由谷歌提出的EfficientNet-L2-NoisyStudent + SAM(88.6%)和ViT(88.55%)首先谷歌这篇paper所提出的方法Meta Pseudo Labels是一种半监督学习方法(a semi-supervised learning ),或者说是self-training方法。和谷歌之前的SOTA方法一样,这里当然用到了那个未公开的300M JFT数据集。不过这里把它们当成unlabeled的数据(和NoisyStudent一样,但ViT是用的labeled数据pretrain)。Meta Pseudo Labels可以看成是最简单的Pseudo Labels方法的改进,如下面图以图二所示。其实之前的SOTA方法Nosiy Student也是一种Pseudo Labels方法(也需要特定的技巧),如上图所示。
)。谷歌的这篇论文是把ImageNet上top-1识别准确率作为一个亮点,其实这篇论文同样在ImageNet上top-5识别率上也刷到了第一:98.8%。只不过top-5识别准确率相对比较简单,谷歌是不会把这当作卖点的。(注:top-5识别准确率指的是在测试图片的N个分类概率中,取前面5个最大的分类概率,这五个当中只要有一个预测正确即可,而top-1则最难,只取第一个预测输出结果,对就是对,错就是错。)那这篇论文究竟讲了什么呢?以下援引知乎@小小将的回答(已经过作者授权):【终于终于,ImageNet的Top-1可以上90%了。其实谷歌刷新的还是自己的记录,因为目前ImageNet上的SOTA还是由谷歌提出的EfficientNet-L2-NoisyStudent + SAM(88.6%)和ViT(88.55%)首先谷歌这篇paper所提出的方法Meta Pseudo Labels是一种半监督学习方法(a semi-supervised learning ),或者说是self-training方法。和谷歌之前的SOTA方法一样,这里当然用到了那个未公开的300M JFT数据集。不过这里把它们当成unlabeled的数据(和NoisyStudent一样,但ViT是用的labeled数据pretrain)。Meta Pseudo Labels可以看成是最简单的Pseudo Labels方法的改进,如下面图以图二所示。其实之前的SOTA方法Nosiy Student也是一种Pseudo Labels方法(也需要特定的技巧),如上图所示。 图一
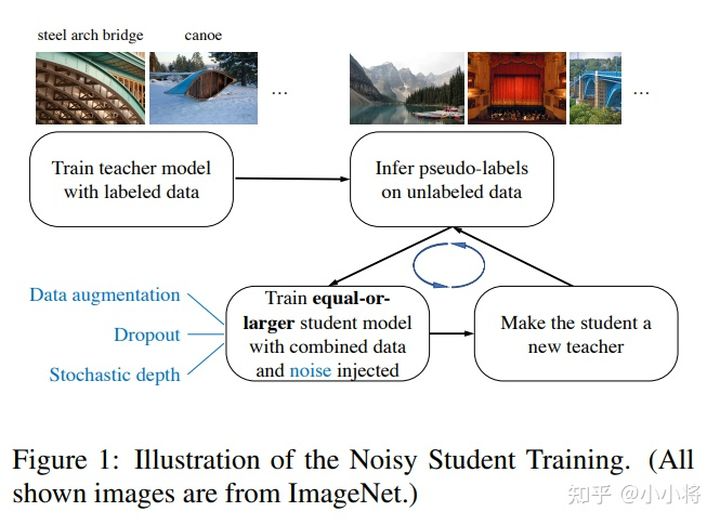
图一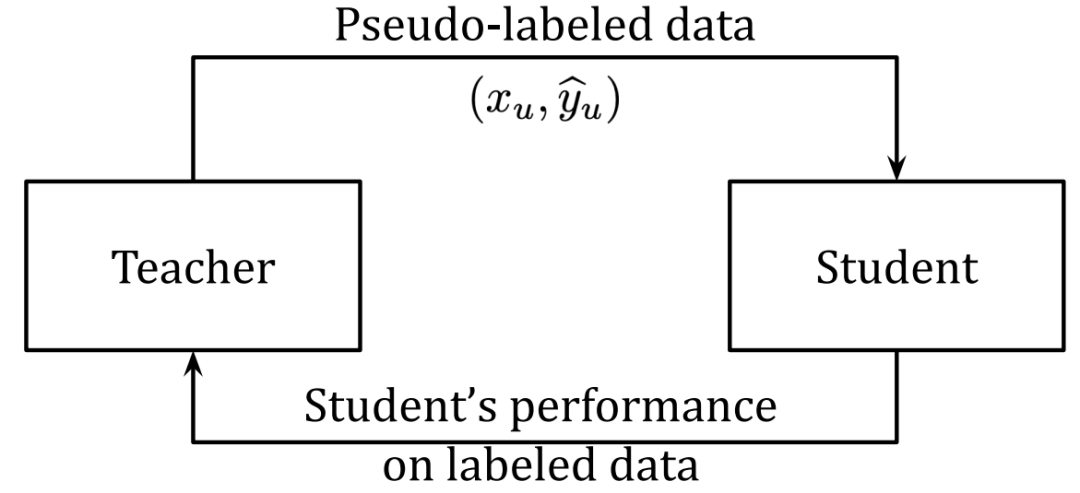 图二以上两图显示了伪标签和元伪标签之间的区别。图一:伪标签,在这里一个固定的预训练的教师生成供学生学习的伪标签。图二:元伪标签,老师和学生一起训练。根据教师生成的伪标签(顶部箭头)对学生进行培训。教师根据学生在标记数据(底部箭头)上的表现进行培训。而Meta Pseudo Labels要解决的是Pseudo Labels容易出现的confirmation bias:
图二以上两图显示了伪标签和元伪标签之间的区别。图一:伪标签,在这里一个固定的预训练的教师生成供学生学习的伪标签。图二:元伪标签,老师和学生一起训练。根据教师生成的伪标签(顶部箭头)对学生进行培训。教师根据学生在标记数据(底部箭头)上的表现进行培训。而Meta Pseudo Labels要解决的是Pseudo Labels容易出现的confirmation bias:如果伪标签不正确,则学生将从错误的数据中学习。结果,学生可能不会比老师好得多。过度拟合网络预测的错误伪标签称为确认偏差。
老师总会犯错,这就会带偏学生。谷歌提出的解决方案,是用学生在labeled数据集的表现来更新老师,就是上图中老师也是不断被训练的,有点强化学习的意味,就是student的preformance应该是teacher进化的一个reward。Meta Pseudo Labels其实也算是对模型训练过程的优化,为什么叫Meta,paper里面也给出解释:我们在方法名称中使用Meta,因为从学生的反馈中得出教师更新规则的技术是基于双级优化问题的,该问题在元学习的文献中经常出现。
虽然思路很简单,但是paper里有非常复杂的推导,这里直接贴出伪代码(训练teacher时其实gradient包含三个部分:来自student的feedback,labeled数据loss,以及UDA loss):关于Meta Pseudo Labels的benefits,paper里面给出了一个toy case,其实我也被这个效果给震惊了。简单来说,就是用TwoMoon dataset,这个数据集中共有两类,或者说是两个cluster,总数据是2000个,每个cluster共有1000个,现在每个cluster只有3个labeled数据,其它都是unlabeled的数据。作者在这样的一个任务上对比了三种方法:Supervised Learning, Pseudo Labels, and Meta Pseudo Labels,最终结果如下所示:其中红色圈和绿色圈分别是两类的samples,星号表示labeled的6个数据,红色和绿色区域表示模型的分类区域,虽然3类方法都可以对6个训练样本正确分类,但具体到unlabeled的数据效果差别很大。SL方法基本过拟合了,分类区域完全不对;而Pseudo Labels分对了一半,但是Meta Pseudo Labels却找到了一个比较完美的classifier。虽然这个分类任务看起来不难,但是只有6个训练样本,我个人觉得能finding a good classifier is hard。因此,我们设计了一个混合模型-数据并行框架来运行元伪标签。具体来说,我们的培训过程在2,048个TPUv3内核的集群上运行。
我觉得这句话应该是对谷歌这个方法的一个较好的总结。】在知乎帖子[如何看待谷歌最新论文第一次将ImageNet数据集的准确度提升至90%以上?]下面,众多知乎大V都对谷歌这一工作做了吐槽。
imagenet榜单前15名都是G家的,都用了不开源的jft data。。。
下面随即就有霍华德等一众大V对谷歌数据集不开源的调侃:
往下翻可以看到大家基本都对谷歌用额外数据集且不公开表示质疑。
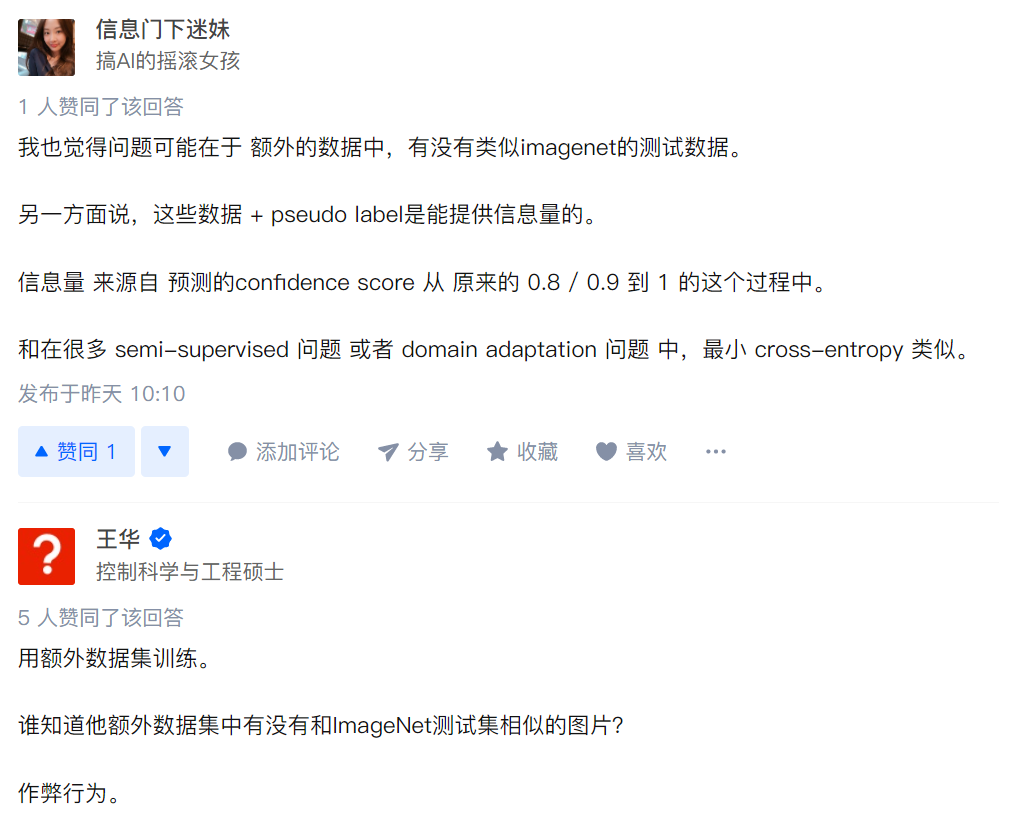
之后有匿名网友直接表示谷歌这是耍流氓行为:用了比imagenet还大几个数量级的dataset额外训练,还不公布数据集。
“Quoc Le的论文Yann Le Cun都吐槽小技巧太多,贼难复现,之前连论文一作都出来说没必要复现,trick太多了。
最后,关于谷歌的这篇论文,以及对于ImageNet Top-1识别率达到90%这件事,大家又有什么看法呢?参考链接:https://www.zhihu.com/question/439336844
↓扫描关注本号↓