
Kubernetes日志收集的那些套路


准备
关于容器日志
默认方式下容器日志并不会限制日志文件的大小,容器会一直写日志,导致磁盘爆满,影响系统应用。(docker log-driver支持log文件的rotate)
Docker Daemon收集容器的标准输出,当日志量过大时会导致Docker Daemon成为日志收集的瓶颈,日志的收集速度受限。
日志文件量过大时,利用docker logs -f查看时会直接将Docker Daemon阻塞住,造成docker ps等命令也不响应。
syslog 14.9 MB/s
json-file 37.9 MB/s
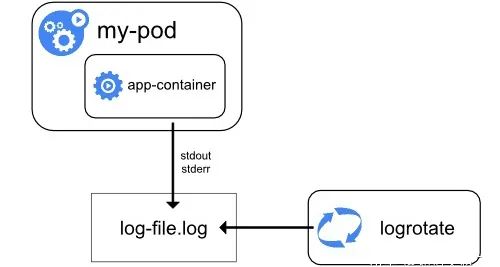

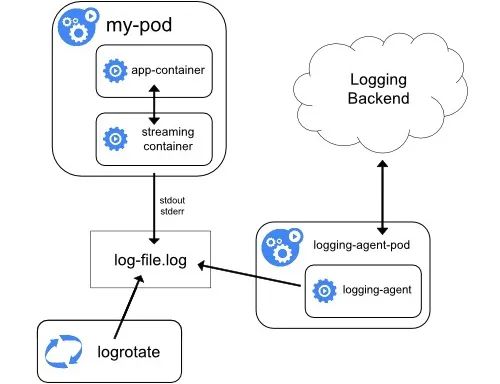

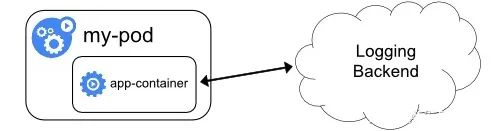
日志架构

所有应用容器都是基于S6基底镜像的,容器应用日志都会重定向到宿主机的某个目录文件下比如/data/logs/namespace/appname/podname/log/xxxx.log
log-agent内部包含Filebeat,Logrotate等工具,其中Filebeat是作为日志文件收集的agent
通过Filebeat将收集的日志发送到Kafka
Kafka在讲日志发送的ES日志存储/kibana检索层
Logstash作为中间工具主要用来在ES中创建index和消费Kafka的消息
用户部署的新应用,如何动态更新Filebeat配置
如何保证每个日志文件都被正常的rotate
如果需要更多的功能则需要二次开发Filebeat,使Filebeat支持更多的自定义配置
付诸实践
/var/log/xxxx/xxxxx.log {
su www-data www-data
missingok
notifempty
size 1G
copytruncate
}
总结
https://docs.docker.com/v17.09/engine/admin/logging/overview/
http://skarnet.org/software/s6/
文章转载: 分布式实验室
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多