
Kubernetes 日志收集的原理,看这一篇就够了
准备
关于容器日志
Docker 的日志分为两类,一类是 Docker 引擎日志;另一类是容器日志。引擎日志一般都交给了系统日志,不同的操作系统会放在不同的位置。
docker logs 显示当前运行的容器的日志信息,内容包含 STOUT(标准输出) 和 STDERR(标准错误输出)。日志都会以 json-file 的格式存储于 /var/lib/docker/containers/<容器id>/<容器id>-json.log,不过这种方式并不适合放到生产环境中。默认方式下容器日志并不会限制日志文件的大小,容器会一直写日志,导致磁盘爆满,影响系统应用。(docker log-driver 支持log文件的rotate)
Docker Daemon 收集容器的标准输出,当日志量过大时会导致 Docker Daemon 成为日志收集的瓶颈,日志的收集速度受限。
日志文件量过大时,利用
docker logs -f查看时会直接将 Docker Daemon 阻塞住,造成docker ps等命令也不响应。
log-driver 日志收集速度
syslog 14.9 MB/s
json-file 37.9 MB/s
关于k8s日志
k8s日志收集方案分成三个级别:
应用(Pod)级别
节点级别
集群级别
应用(Pod)级别
kubectl logs pod-name -n namespace 查看,具体参考。https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#logs
节点级别
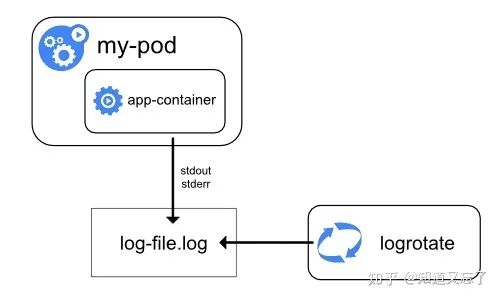
集群级别
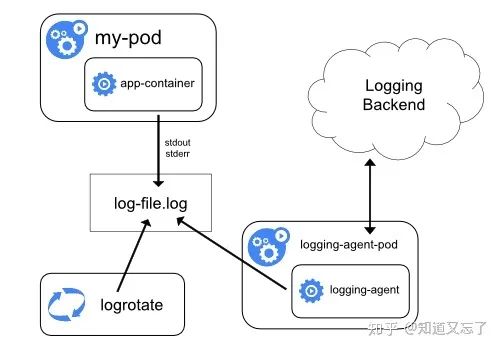
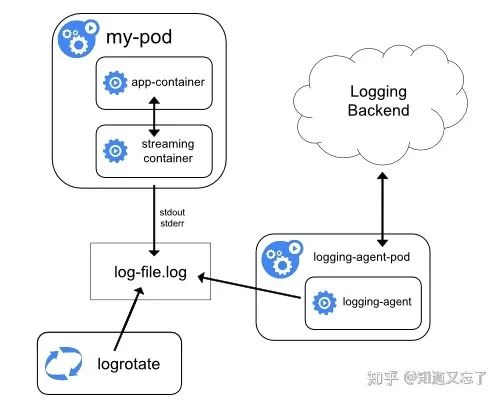


日志架构
解释如下:
所有应用容器都是基于s6基底镜像的,容器应用日志都会重定向到宿主机的某个目录文件下比如
/data/logs/namespace/appname/podname/log/xxxx.loglog-agent 内部 包含 filebeat ,logrotate 等工具,其中filebeat是作为日志文件收集的agent
通过filebeat将收集的日志发送到kafka
kafka再将日志发送的es日志存储/kibana检索层
logstash 作为中间工具主要用来在es中创建index和消费kafka 的消息
整个流程很好理解,但是需要解决的是
用户部署的新应用,如何动态更新filebeat配置,
如何保证每个日志文件都被正常的rotate,
如果需要更多的功能则需要二次开发filebeat,使filebeat 支持更多的自定义配置。
付诸实践
解决上述问题,就需要开发一个log-agent应用以daemonset形式运行在k8s集群的每个节点上,应用内部包含filebeat,logrotate,和需要开发的功能组件。
第一个问题,如何动态更新filebeat配置,可以利用http://github.com/fsnotify/fsnotify 工具包监听日志目录变化create、delete事件,利用模板渲染的方法更新filebeat配置文件
第二个问题,利用http://github.com/robfig/cron 工具包 创建cronJob,定期rotate日志文件,注意应用日志文件所属用户,如果不是root用户所属,可以在配置中设置切换用户
/var/log/xxxx/xxxxx.log {su www-data www-datamissingoknotifemptysize 1Gcopytruncate}
第三个问题,关于二次开发filebeat,可以参考博文 https://www.jianshu.com/p/fe3ac68f4
总结
本文只是对k8s日志收集提供了一个简单的思路,关于日志收集可以根据公司的需求,因地制宜。
参考文献
https://kubernetes.io/docs/concepts/cluster-administration/logging/
https://support.rackspace.com/how-to/understanding-logrotate-utility/
https://github.com/elastic/beats/tree/master/filebeat
http://skarnet.org/software/s6/
来源:https://zhuanlan.zhihu.com/p/70662744
文章转载:高效运维
(版权归原作者所有,侵删)
关注「开源Linux」加星标,提升IT技能
