
从一个线上问题看 Elasticsearch 数据清洗方式
如下问题来自真实场景,用对话方式模拟还原问题解答过程。
小明同学提问:铭毅老湿,如下两个链接,我们底层的数据是带空格的,但是用户输入可能不带空格这种改怎么处理?

http://192.168.1.1/sr/6mm/
http://192.168.1.1/sr/6%20mm/铭毅老湿:上面两个链接是用户的行为?我们不能限制用户的输入是吧?

小明同学:是哦,让用户输入字符加空格或者不加空格去适配写入的数据,这样会显得系统很不“智能”,用户体验会很差。
铭毅老湿:你能关注用户体验,不错!这是程序员必备的思维方式。
小明同学:那怎么解决类似问题呢?
铭毅老湿:其实最简单、最常用的解决方式就是:写入前做好数据清洗,去掉“特殊字符”、“空格”等。

图片来自互联网
小明同学:这个我知道,不就是ETL嘛!包含数据的抽取、转换和加载。ETL着重体现在一些数据清洗转化功能,比如空值处理、规范化数据、数据替换、数据验证等等。。。
咦,我的问题不就是“空值处理”嘛~~
铭毅老湿:那你说说怎么弄?
小明同学:“一脸的疑惑似乎舒缓了一些”,写入前去掉空格。java 里面貌似一行正则代码就能搞定。
str = str.replaceAll("\\s+", "");
我明白啦!
铭毅老湿:小明同学别着急!那用户检索怎么搞?
小明同学:原理一样的,前端接收用户请求,做一下清洗处理就可以。我走啦,铭毅老湿。
铭毅老湿:等等~~~你的源头数据从哪里来?
小明同学:MySQL呀。
铭毅老湿:那你是怎么同步数据的?
小明同学:借助 logstash,logstash-input-jdbc 同步插件非常好用,支持各种类型的关系型数据库的同步。我还画了各种类型同步到 Elasticsearch 的各种实现呢?手机上有,你看一下。
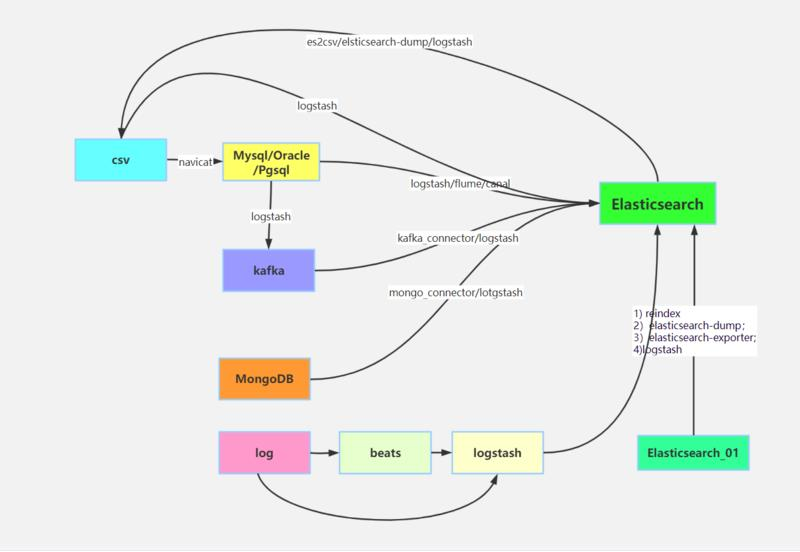
不同源数据同步到 Elasticsearch 实现方案
铭毅老湿:不错,总结的很全面 。那我问你,你这一行 java 代码往哪里写?
。那我问你,你这一行 java 代码往哪里写?
小明同学:我插 ,这点我忘记了。我想一下,logstash 是用 ruby 语言写的,找一下 ruby 语言如何处理空格就可以了。
,这点我忘记了。我想一下,logstash 是用 ruby 语言写的,找一下 ruby 语言如何处理空格就可以了。
小明同学拿起手机查了2分钟,找到啦!
mutate {
gsub => [
"Animal", "\s", ""
]
}语言不同,和 java 语法都有相通的地方。
我走啦,还是你考虑的周全,铭毅老湿!
铭毅老湿:别着急,那如果不用 logstash 处理,该如何搞定呢?假定你的 logstash 不允许再改了。
小明同学:这个假如不存在的,想改就改,非常受控。嘻嘻~~~,让我想想。。。。。。
与 logstash filter 中转处理环节有个同等重量级的 ingest 预处理借助脚本可以实现,还有个我不大确认,自定义分词能否实现呢?
铭毅老湿:你说的很对,自定义分词包含哪三个环节?如何实现咋实现有思路吗?
小明同学:这个我有点忘记了,得查一下文档。有了,这个图很万能。
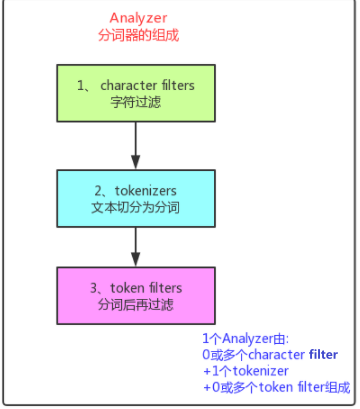
涉及细节不少,我得回去研究一下了。
多谢铭毅老湿~~我真的得走啦,再见!
间隔了一天。。。。。。
第二天,小明带来了他的实现。
铭毅老湿:小明,你讲一下实现思路吧?小明同学:我用了两种方法,
方法一:在自定义分词的 character filter 环节借助 pattern replace 方式将空格转化为没有任何字符,就相当于去掉了空格。 方法二:通过 character filter 环节的 Mapping 将空格字符等同于无字符处理,就间接去掉了空格。 这两种方法本质都是借助之前给的图的第一个环节:character filter 字符过滤的方式实现的。
这里有可供演示的 DSL,我给你演示一下:
PUT my-index-000001
{
"settings": {
"analysis": {
"filter": {
"whitespace_remove": {
"type": "pattern_replace",
"pattern": " ",
"replacement": ""
}
},
"analyzer": {
"auto_analyzer": {
"filter": [
"lowercase",
"whitespace_remove"
],
"type": "custom",
"tokenizer": "keyword"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "auto_analyzer",
"fields": {
"field": {
"type": "keyword"
}
}
}
}
}
}
POST my-index-000001/_bulk
{"index":{"_id":1}}
{"title":"6mm"}
{"index":{"_id":2}}
{"title":"6 mm"}
{"index":{"_id":3}}
{"title":"6 mm"}
GET my-index-000001/_analyze
{
"text": ["6mm", "6 mm", "6 mm"],
"analyzer": "auto_analyzer"
}
## 三类数据都能召回
POST my-index-000001/_search
{
"query": {
"match": {
"title": "6mm"
}
}
}https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-pattern_replace-tokenfilter.html
PUT my-index-000002
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"""\u0020=>"""
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "my_analyzer",
"fields": {
"field": {
"type": "keyword"
}
}
}
}
}
}
POST my-index-000002/_bulk
{"index":{"_id":1}}
{"title":"6mm"}
{"index":{"_id":2}}
{"title":"6 mm"}
{"index":{"_id":3}}
{"title":"6 mm"}
GET my-index-000002/_analyze
{
"text": ["6mm", "6 mm", "6 mm"],
"analyzer": "my_analyzer"
}
## 三类数据都能召回
POST my-index-000002/_search
{"query":{"match":{"title":"6mm"}}}铭毅老湿:不错,不错,考虑的很全面。那小明同学,你能否总结一下:Elasticsearch 数据预处理的方式有哪些?
小明同学:我给你现场画个脑图吧。
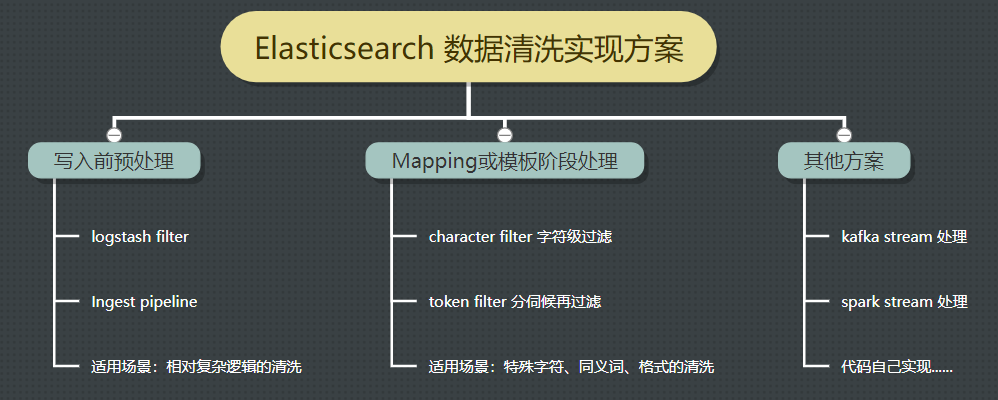
铭毅老湿:哎呦,不错哦。。。
未完,待续~~~
推荐
和 20000+ Elastic小伙伴一起学习 ElasticStack!
